by Dan Scott
Part 2 of a 2 part article. See part one at http://journal.code4lib.org/articles/3284.
Returning streaming results
In the previous implementation of the opensrf.simple-text.split method, we returned a reference to the complete array of results. For small values being delivered over the network, this is perfectly acceptable, but for large sets of values this can pose a number of problems for the requesting client. Consider a service that returns a set of bibliographic records in response to a query like “all records edited in the past month”; if the underlying database is relatively active, that could result in thousands of records being returned as a single network request. The client would be forced to block until all of the results are returned, likely resulting in a significant delay, and depending on the implementation, correspondingly large amounts of memory might be consumed as all of the results are read from the network in a single block.
OpenSRF offers a solution to this problem. If the method returns results that can be divided into separate meaningful units, you can register the OpenSRF method as a streaming method and enable the client to loop over the results one unit at a time until the method returns no further results. In addition to registering the method with the provided name, OpenSRF also registers an additional method with .atomic appended to the method name. The .atomic variant gathers all of the results into a single block to return to the client, giving the caller the ability to choose either streaming or atomic results from a single method definition.
In the following example, the text splitting method has been reimplemented to support streaming; very few changes are required:
Text splitting method – streaming mode
sub text_split {
my $self = shift;
my $conn = shift;
my $text = shift;
my $delimiter = shift || ' ';
my @split_text = split $delimiter, $text;
foreach my $string (@split_text) { # <1>
$conn->respond($string);
}
return undef;
}
__PACKAGE__->register_method(
method => 'text_split',
api_name => 'opensrf.simple-text.split',
stream => 1 # <2>
);
- Rather than returning a reference to the array, a streaming method loops over the contents of the array and invokes the respond() method of the connection object on each element of the array.
- Registering the method as a streaming method instructs OpenSRF to also register an atomic variant (opensrf.simple-text.split.atomic).
Error! Warning! Info! Debug!
As hard as it may be to believe, it is true: applications sometimes do not behave in the expected manner, particularly when they are still under development. The service language bindings for OpenSRF include integrated support for logging messages at the levels of ERROR, WARNING, INFO, DEBUG, and the extremely verbose INTERNAL to either a local file or to a syslogger service. The destination of the log files, and the level of verbosity to be logged, is set in the opensrf_core.xml configuration file. To add logging to our Perl example, we just have to add the OpenSRF::Utils::Logger package to our list of used Perl modules, then invoke the logger at the desired logging level.
You can include many calls to the OpenSRF logger; only those that are higher than your configured logging level will actually hit the log. The following example exercises all of the available logging levels in OpenSRF:
use OpenSRF::Utils::Logger;
my $logger = OpenSRF::Utils::Logger;
# some code in some function
{
$logger->error("Hmm, something bad DEFINITELY happened!");
$logger->warn("Hmm, something bad might have happened.");
$logger->info("Something happened.");
$logger->debug("Something happened; here are some more details.");
$logger->internal("Something happened; here are all the gory details.")
}
If you call the mythical OpenSRF method containing the preceding OpenSRF logger statements on a system running at the default logging level of INFO, you will only see the INFO, WARN, and ERR messages, as follows:
Results of logging calls at the default level of INFO
[2010-03-17 22:27:30] opensrf.simple-text [ERR :5681:SimpleText.pm:277:] Hmm, something bad DEFINITELY happened! [2010-03-17 22:27:30] opensrf.simple-text [WARN:5681:SimpleText.pm:278:] Hmm, something bad might have happened. [2010-03-17 22:27:30] opensrf.simple-text [INFO:5681:SimpleText.pm:279:] Something happened.
If you then increase the the logging level to INTERNAL (5), the logs will contain much more information, as follows:
Results of logging calls at the default level of INTERNAL
[2010-03-17 22:48:11] opensrf.simple-text [ERR :5934:SimpleText.pm:277:] Hmm, something bad DEFINITELY happened! [2010-03-17 22:48:11] opensrf.simple-text [WARN:5934:SimpleText.pm:278:] Hmm, something bad might have happened. [2010-03-17 22:48:11] opensrf.simple-text [INFO:5934:SimpleText.pm:279:] Something happened. [2010-03-17 22:48:11] opensrf.simple-text [DEBG:5934:SimpleText.pm:280:] Something happened; here are some more details. [2010-03-17 22:48:11] opensrf.simple-text [INTL:5934:SimpleText.pm:281:] Something happened; here are all the gory details. [2010-03-17 22:48:11] opensrf.simple-text [ERR :5934:SimpleText.pm:283:] Resolver did not find a cache hit [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:Cache.pm:125:] Stored opensrf.simple-text.test_cache.masaa => "here" in memcached server [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:Application.pm:579:] Coderef for [OpenSRF::Application::Demo::SimpleText::test_cache] has been run [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:Application.pm:586:] A top level Request object is responding de nada [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:Application.pm:190:] Method duration for [opensrf.simple-text.test_cache]: 10.005 [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:AppSession.pm:780:] Calling queue_wait(0) [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:AppSession.pm:769:] Resending...0 [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:AppSession.pm:450:] In send [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:AppSession.pm:506:] AppSession sending RESULT to opensrf@private.localhost/_dan-karmic-liblap_1268880489.752154_5943 with threadTrace [1] [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:AppSession.pm:506:] AppSession sending STATUS to opensrf@private.localhost/_dan-karmic-liblap_1268880489.752154_5943 with threadTrace [1] ...
To see everything that is happening in OpenSRF, try leaving your logging level set to INTERNAL for a few minutes – just ensure that you have a lot of free disk space available if you have a moderately busy system!
Caching results: one secret of scalability
If you have ever used an application that depends on a remote Web service outside of your control — say, if you need to retrieve results from a microblogging service — you know the pain of latency and dependability (or the lack thereof). To improve the response time for OpenSRF services, you can take advantage of the support offered by the OpenSRF::Utils::Cache module for communicating with a local instance or cluster of memcache daemons to store and retrieve persistent values. The following example demonstrates caching by sleeping for 10 seconds the first time it receives a given cache key and cannot retrieve a corresponding value from the cache:
Simple caching OpenSRF service
use OpenSRF::Utils::Cache; # <1>
sub test_cache {
my $self = shift;
my $conn = shift;
my $test_key = shift;
my $cache = OpenSRF::Utils::Cache->new('global'); # <2>
my $cache_key = "opensrf.simple-text.test_cache.$test_key"; # <3>
my $result = $cache->get_cache($cache_key) || undef; # <4>
if ($result) {
$logger->info("Resolver found a cache hit");
return $result;
}
sleep 10; # <5>
my $cache_timeout = 300; # <6>
$cache->put_cache($cache_key, "here", $cache_timeout); # <7>
return "There was no cache hit.";
}
- The OpenSRF::Utils::Cache module provides access to the built-in caching support in OpenSRF.
- The constructor for the cache object accepts a single argument to define the cache type for the object. Each cache type can use a separate memcache server to keep the caches separated. Most Evergreen services use the global cache, while the anon cache is used for Web sessions.
- The cache key is simply a string that uniquely identifies the value you want to store or retrieve. This line creates a cache key based on the OpenSRF method name and request input value.
- The get_cache() method checks to see if the cache key already exists. If a matching key is found, the service immediately returns the stored value.
- If the cache key does not exist, the code sleeps for 10 seconds to simulate a call to a slow remote Web service or an intensive process.
- The $cache_timeout variable represents a value for the lifetime of the cache key in seconds.
- After the code retrieves its value (or, in the case of this example, finishes sleeping), it creates the cache entry by calling the put_cache() method. The method accepts three arguments: the cache key, the value to be stored (“here”), and the timeout value in seconds to ensure that we do not return stale data on subsequent calls.
Initializing the service and its children: child labour
When an OpenSRF service is started, it looks for a procedure called initialize() to set up any global variables shared by all of the children of the service. The initialize() procedure is typically used to retrieve configuration settings from the opensrf.xml file.
An OpenSRF service spawns one or more children to actually do the work requested by callers of the service. For every child process an OpenSRF service spawns, the child process clones the parent environment and then each child process runs the child_init() process (if any) defined in the OpenSRF service to initialize any child-specific settings.
When the OpenSRF service kills a child process, it invokes the child_exit() procedure (if any) to clean up any resources associated with the child process. Similarly, when the OpenSRF service is stopped, it calls the DESTROY() procedure to clean up any remaining resources.
Retrieving configuration settings
The settings for OpenSRF services are maintained in the opensrf.xml XML configuration file. The structure of the XML document consists of a root element <opensrf> containing two child elements:
- The <default> element contains an <apps> element describing all OpenSRF services running on this system — see [serviceRegistration] –, as well as any other arbitrary XML descriptions required for global configuration purposes. For example, Evergreen uses this section for email notification and inter-library patron privacy settings.
- The <hosts> element contains one element per host that participates in this OpenSRF system. Each host element must include an <activeapps> element that lists all of the services to start on this host when the system starts up. Each host element can optionally override any of the default settings.
OpenSRF includes a service named opensrf.settings to provide distributed cached access to the configuration settings with a simple API:
- opensrf.settings.default_config.get accepts zero arguments and returns the complete set of default settings as a JSON document.
- opensrf.settings.host_config.get accepts one argument (hostname) and returns the complete set of settings, as customized for that hostname, as a JSON document.
- opensrf.settings.xpath.get accepts one argument (an XPath expression) and returns the portion of the configuration file that matches the expression as a JSON document.
For example, to determine whether an Evergreen system uses the opt-in support for sharing patron information between libraries, you could either invoke the opensrf.settings.default_config.get method and parse the JSON document to determine the value, or invoke the opensrf.settings.xpath.get method with the XPath /opensrf/default/share/user/opt_in argument to retrieve the value directly.
In practice, OpenSRF includes convenience libraries in all of its client language bindings to simplify access to configuration values. C offers osrfConfig.c, Perl offers OpenSRF::Utils::SettingsClient, Java offers org.opensrf.util.SettingsClient, and Python offers osrf.set. These libraries locally cache the configuration file to avoid network roundtrips for every request and enable the developer to request specific values without having to manually construct XPath expressions.
Getting under the covers with OpenSRF
Get on the messaging bus – safelyOne of the core innovations of OpenSRF was to use the Extensible Messaging and Presence Protocol (XMPP, more colloquially known as Jabber) as the messaging bus that ties OpenSRF services together across servers. XMPP is an “XML protocol for near-real-time messaging, presence, and request-response services” (http://www.ietf.org/rfc/rfc3920.txt) that OpenSRF relies on to handle most of the complexity of networked communications. OpenSRF requres an XMPP server that supports multiple domains such as ejabberd. Multiple domain support means that a single server can support XMPP virtual hosts with separate sets of users and access privileges per domain. By routing communications through separate public and private XMPP domains, OpenSRF services gain an additional layer of security.
The OpenSRF installation documentation instructs you to create two separate hostnames (private.localhost and public.localhost) to use as XMPP domains. OpenSRF can control access to its services based on the domain of the client and whether a given service allows access from clients on the public domain. When you start OpenSRF, the first XMPP clients that connect to the XMPP server are the OpenSRF public and private routers. OpenSRF routers maintain a list of available services and connect clients to available services. When an OpenSRF service starts, it establishes a connection to the XMPP server and registers itself with the private router. The OpenSRF configuration contains a list of public OpenSRF services, each of which must also register with the public router.
OpenSRF communication flows over XMPP
In a minimal OpenSRF deployment, two XMPP users named “router” connect to the XMPP server, with one connected to the private XMPP domain and one connected to the public XMPP domain. Similarly, two XMPP users named “opensrf” connect to the XMPP server via the private and public XMPP domains. When an OpenSRF service is started, it uses the “opensrf” XMPP user to advertise its availability with the corresponding router on that XMPP domain; the XMPP server automatically assigns a Jabber ID (JID) based on the client hostname to each service’s listener process and each connected drone process waiting to carry out requests. When an OpenSRF router receives a request to invoke a method on a given service, it connects the requester to the next available listener in the list of registered listeners for that service.
Services and clients connect to the XMPP server using a single set of XMPP client credentials (for example, opensrf@private.localhost), but use XMPP resource identifiers to differentiate themselves in the JID for each connection. For example, the JID for a copy of the opensrf.simple-text service with process ID 6285 that has connected to the private.localhost domain using the opensrf XMPP client credentials could be opensrf@private.localhost/opensrf.simple-text_drone_at_localhost_6285. By convention, the user name for OpenSRF clients is opensrf, and the user name for OpenSRF routers is router, so the XMPP server for OpenSRF will have four separate users registered:
- opensrf@private.localhost is an OpenSRF client that connects with these credentials and which can access any OpenSRF service.
- opensrf@public.localhost is an OpenSRF client that connects with these credentials and which can only access OpenSRF services that have registered with the public router.
- router@private.localhost is the private OpenSRF router with which all services register.
- router@public.localhost is the public OpenSRF router with which only services that must be publicly accessible register.
All OpenSRF services automatically register themselves with the private XMPP domain, but only those services that register themselves with the public XMPP domain can be invoked from public OpenSRF clients. The OpenSRF client and router user names, passwords, and domain names, along with the list of services that should be public, are contained in the opensrf_core.xml configuration file.
OpenSRF communication flows over HTTP
In some contexts, access to a full XMPP client is not a practical option. For example, while XMPP clients have been implemented in JavaScript, you might be concerned about browser compatibility and processing overhead – or you might want to issue OpenSRF requests from the command line with curl. Fortunately, any OpenSRF service registered with the public router is accessible via the OpenSRF HTTP Translator. The OpenSRF HTTP Translator implements the OpenSRF-over-HTTP proposed specification as an Apache module that translates HTTP requests into OpenSRF requests and returns OpenSRF results as HTTP results to the initiating HTTP client.
Issuing an HTTP POST request to an OpenSRF method via the OpenSRF HTTP Translator
# curl request broken up over multiple lines for legibility
curl -H "X-OpenSRF-service: opensrf.simple-text" \ # <1>
--data 'osrf-msg=[ \ # <2>
{"__c":"osrfMessage","__p":{"threadTrace":0,"locale":"en-CA", \ # <3>
"type":"REQUEST","payload": {"__c":"osrfMethod","__p": \
{"method":"opensrf.simple-text.reverse","params":["foobar"]} \
}} \
}]' \
http://localhost/osrf-http-translator \ # <4>
- The X-OpenSRF-service header identifies the OpenSRF service of interest.
- The POST request consists of a single parameter, the osrf-msg value, which contains a JSON array.
- The first object is an OpenSRF message ("__c":"osrfMessage") with a set of parameters ("__p":{}).
- The identifier for the request ("threadTrace":0); this value is echoed back in the result.
- The message type ("type":"REQUEST").
- The locale for the message; if the OpenSRF method is locale-sensitive, it can check the locale for each OpenSRF request and return different information depending on the locale.
- The payload of the message ("payload":{}) containing the OpenSRF method request ("__c":"osrfMethod") and its parameters ("__p:"{}).
- The method name for the request ("method":"opensrf.simple-text.reverse").
- A set of JSON parameters to pass to the method ("params":["foobar"]); in this case, a single string "foobar".
- The URL on which the OpenSRF HTTP translator is listening, /osrf-http-translator is the default location in the Apache example configuration files shipped with the OpenSRF source, but this is configurable.
Results from an HTTP POST request to an OpenSRF method via the OpenSRF HTTP Translator
# HTTP response broken up over multiple lines for legibility
[{"__c":"osrfMessage","__p": \ # <1>
{"threadTrace":0, "payload": \ # <2>
{"__c":"osrfResult","__p": \ # <3>
{"status":"OK","content":"raboof","statusCode":200} \ # <4>
},"type":"RESULT","locale":"en-CA" \ # <5>
}
},
{"__c":"osrfMessage","__p": \ # <6>
{"threadTrace":0,"payload": \ # <7>
{"__c":"osrfConnectStatus","__p": \ # <8>
{"status":"Request Complete","statusCode":205} \ # <9>
},"type":"STATUS","locale":"en-CA" \ # <10>
}
}]
- The OpenSRF HTTP Translator returns an array of JSON objects in its response. Each object in the response is an OpenSRF message ("__c":"osrfMessage") with a collection of response parameters ("__p":).
- The OpenSRF message identifier ("threadTrace":0) confirms that this message is in response to the request matching the same identifier.
- The message includes a payload JSON object ("payload":) with an OpenSRF result for the request ("__c":"osrfResult").
- The result includes a status indicator string ("status":"OK"), the content of the result response – in this case, a single string “raboof” ("content":"raboof") – and an integer status code for the request ("statusCode":200).
- The message also includes the message type ("type":"RESULT") and the message locale ("locale":"en-CA").
- The second message in the set of results from the response.
- Again, the message identifier confirms that this message is in response to a particular request.
- The payload of the message denotes that this message is an OpenSRF connection status message ("__c":"osrfConnectStatus"), with some information about the particular OpenSRF connection that was used for this request.
- The response parameters for an OpenSRF connection status message include a verbose status ("status":"Request Complete") and an integer status code for the connection status (`”statusCode”:205).
- The message also includes the message type ("type":"RESULT") and the message locale ("locale":"en-CA").
|
Tip |
Before adding a new public OpenSRF service, ensure that it does not introduce privilege escalation or unchecked access to data. For example, the Evergreen open-ils.cstore private service is an object-relational mapper that provides read and write access to the entire Evergreen database, so it would be catastrophic to expose that service publicly. In comparison, the Evergreen open-ils.pcrud public service offers the same functionality as open-ils.cstore to any connected HTTP client or OpenSRF client, but the additional authentication and authorization layer in open-ils.pcrud prevents unchecked access to Evergreen’s data. |
Stateless and stateful connections
OpenSRF supports both stateless and stateful connections. When an OpenSRF client issues a REQUEST message in a stateless connection, the router forwards the request to the next available service and the service returns the result directly to the client.
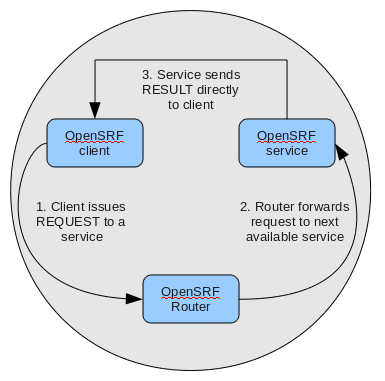
When an OpenSRF client issues a CONNECT message to create a stateful conection, the router returns the Jabber ID of the next available service to the client so that the client can issue one or more REQUEST message directly to that particular service and the service will return corresponding RESULT messages directly to the client. Until the client issues a DISCONNECT message, that particular service is only available to the requesting client. Stateful connections are useful for clients that need to make many requests from a particular service, as it avoids the intermediary step of contacting the router for each request, as well as for operations that require a controlled sequence of commands, such as a set of database INSERT, UPDATE, and DELETE statements within a transaction.

Message body format
OpenSRF was an early adopter of JavaScript Object Notation (JSON). While XMPP is an XML protocol, the Evergreen developers recognized that the compactness of the JSON format offered a significant reduction in bandwidth for the volume of messages that would be generated in an application of that size. In addition, the ability of languages such as JavaScript, Perl, and Python to generate native objects with minimal parsing offered an attractive advantage over invoking an XML parser for every message. Instead, the body of the XMPP message is a simple JSON structure. For a simple request, like the following example that simply reverses a string, it looks like a significant overhead: but we get the advantages of locale support and tracing the request from the requester through the listener and responder (drone).
A request for opensrf.simple-text.reverse(“foobar”):
<message from='router@private.localhost/opensrf.simple-text'
to='opensrf@private.localhost/opensrf.simple-text_listener_at_localhost_6275'
router_from='opensrf@private.localhost/_karmic_126678.3719_6288'
router_to='' router_class='' router_command='' osrf_xid=''
>
<thread>1266781414.366573.12667814146288</thread>
<body>
[
{"__c":"osrfMessage","__p":
{"threadTrace":"1","locale":"en-US","type":"REQUEST","payload":
{"__c":"osrfMethod","__p":
{"method":"opensrf.simple-text.reverse","params":["foobar"]}
}
}
}
]
</body>
</message>
A response from opensrf.simple-text.reverse(“foobar”)
<message from='opensrf@private.localhost/opensrf.simple-text_drone_at_localhost_6285'
to='opensrf@private.localhost/_karmic_126678.3719_6288'
router_command='' router_class='' osrf_xid=''
>
<thread>1266781414.366573.12667814146288</thread>
<body>
[
{"__c":"osrfMessage","__p":
{"threadTrace":"1","payload":
{"__c":"osrfResult","__p":
{"status":"OK","content":"raboof","statusCode":200}
} ,"type":"RESULT","locale":"en-US"}
},
{"__c":"osrfMessage","__p":
{"threadTrace":"1","payload":
{"__c":"osrfConnectStatus","__p":
{"status":"Request Complete","statusCode":205}
},"type":"STATUS","locale":"en-US"}
}
]
</body>
</message>
The content of the <body> element of the OpenSRF request and result should look familiar; they match the structure of the OpenSRF over HTTP examples that we previously dissected.
Registering OpenSRF methods in depth
Let’s explore the call to __PACKAGE__->register_method(); most of the members of the hash are optional, and for the sake of brevity we omitted them in the previous example. As we have seen in the results of the introspection call, a verbose registration method call is recommended to better enable the internal documentation. Here is the complete set of members that you should pass to __PACKAGE__->register_method():
- The method member specifies the name of the procedure in this module that is being registered as an OpenSRF method.
- The api_name member specifies the invocable name of the OpenSRF method; by convention, the OpenSRF service name is used as the prefix.
- The optional api_level member can be used for versioning the methods to allow the use of a deprecated API, but in practical use is always 1.
- The optional argc member specifies the minimal number of arguments that the method expects.
- The optional stream member, if set to any value, specifies that the method supports returning multiple values from a single call to subsequent requests. OpenSRF automatically creates a corresponding method with “.atomic” appended to its name that returns the complete set of results in a single request. Streaming methods are useful if you are returning hundreds of records and want to act on the results as they return.
- The optional signature member is a hash that describes the method’s purpose, arguments, and return value.
- The desc member of the signature hash describes the method’s purpose.
- The params member of the signature hash is an array of hashes in which each array element describes the corresponding method argument in order.
- The name member of the argument hash specifies the name of the argument.
- The desc member of the argument hash describes the argument’s purpose.
- The type member of the argument hash specifies the data type of the argument: for example, string, integer, boolean, number, array, or hash.
- The return member of the signature hash is a hash that describes the return value of the method.
- The desc member of the return hash describes the return value.
- The type member of the return hash specifies the data type of the return value: for example, string, integer, boolean, number, array, or hash.
Evergreen-specific OpenSRF services
Evergreen is currently the primary showcase for the use of OpenSRF as an application architecture. Evergreen 1.6.1 includes the following set of OpenSRF services:
- The open-ils.actor service supports common tasks for working with user accounts and libraries.
- The open-ils.auth service supports authentication of Evergreen users.
- The open-ils.booking service supports the management of reservations for bookable items.
- The open-ils.cat service supports common cataloging tasks, such as creating, modifying, and merging bibliographic and authority records.
- The open-ils.circ service supports circulation tasks such as checking out items and calculating due dates.
- The open-ils.collections service supports tasks that assist collections agencies in contacting users with outstanding fines above a certain threshold.
- The open-ils.cstore private service supports unrestricted access to Evergreen fieldmapper objects.
- The open-ils.ingest private service supports tasks for importing data such as bibliographic and authority records.
- The open-ils.pcrud service supports permission-based access to Evergreen fieldmapper objects.
- The open-ils.penalty penalty service supports the calculation of penalties for users, such as being blocked from further borrowing, for conditions such as having too many items checked out or too many unpaid fines.
- The open-ils.reporter service supports the creation and scheduling of reports.
- The open-ils.reporter-store private service supports access to Evergreen fieldmapper objects for the reporting service.
- The open-ils.search service supports searching across bibliographic records, authority records, serial records, Z39.50 sources, and ZIP codes.
- The open-ils.storage private service supports a deprecated method of providing access to Evergreen fieldmapper objects. Implemented in Perl, this service has largely been replaced by the much faster C-based open-ils.cstore service.
- The open-ils.supercat service supports transforms of MARC records into other formats, such as MODS, as well as providing Atom and RSS feeds and SRU access.
- The open-ils.trigger private service supports event-based triggers for actions such as overdue and holds available notification emails.
- The open-ils.vandelay service supports the import and export of batches of bibliographic and authority records.
Of some interest is that the open-ils.reporter-store and open-ils.cstore services have identical implementations. Surfacing them as separate services enables a deployer of Evergreen to ensure that the reporting service does not interfere with the performance-critical open-ils.cstore service. One can also direct the reporting service to a read-only database replica to, again, avoid interference with open-ils.cstore which must write to the master database.
There are only a few significant services that are not built on OpenSRF in Evergreen 1.6.0, such as the SIP and Z39.50 servers. These services implement different protocols and build on existing daemon architectures (Simple2ZOOM for Z39.50), but still rely on the other OpenSRF services to provide access to the Evergreen data. The non-OpenSRF services are reasonably self-contained and can be deployed on different servers to deliver the same sort of deployment flexibility as OpenSRF services, but have the disadvantage of not being integrated into the same configuration and control infrastructure as the OpenSRF services.
Evergreen after one year: reflections on OpenSRF
Project Conifer has been live on Evergreen for just over a year now, and as one of the primary technologists I have had to work closely with the OpenSRF infrastructure during that time. As such, I am in a position to identify some of the strengths and weaknesses of OpenSRF based on our experiences.
Weaknesses
The primary weakness of OpenSRF is the lack of either formal or informal documentation for OpenSRF. There are many frequently asked questions on the Evergreen mailing lists and IRC channel that indicate that some of the people running Evergreen or trying to run Evergreen have not been able to find documentation to help them understand, even at a high level, how the OpenSRF Router and services work with XMPP and the Apache Web server to provide a working Evergreen system. Also, over the past few years several developers have indicated an interest in developing Ruby and PHP bindings for OpenSRF, but the efforts so far have resulted in no working code. The lack of a formal specification, clearly annotated examples, and portable unit tests for the major OpenSRF communication use cases is a significant hurdle for a developer seeking to fulfill a base set of expectations for a working binding. As a result, Evergreen integration efforts with popular frameworks like Drupal, Blacklight, and VuFind result in the best practical option for a developer with limited time — database-level integration — which has the unfortunate side effect of being much more likely to break after an upgrade.
In conjunction with the lack of documentation that makes it hard to get started with the framework, a disincentive for new developers to contribute to OpenSRF itself is the lack of integrated unit tests. For a developer to contribute a significant, non-obvious patch to OpenSRF, they need to manually run through various (undocumented, again) use cases to try and ensure that the patch introduced no unanticipated side effects. The same problems hold for Evergreen itself, although the Constrictor stress-testing framework offers a way of performing some automated system testing and performance testing.
These weaknesses could be relatively easily overcome with the effort through contributions from people with the right skill sets. This article arguably offers a small set of clear examples at both the networking and application layer of OpenSRF. A technical writer who understands OpenSRF could contribute a formal specification to the project. With a formal specification at their disposal, a quality assurance expert could create an automated test harness and a basic set of unit tests that could be incrementally extended to provide more coverage over time. If one or more continual integration environments are set up to track the various OpenSRF branches of interest, then the OpenSRF community would have immediate feedback on build quality. Once a unit testing framework is in place, more developers might be willing to develop and contribute patches as they could sanity check their own code without an intense effort before exposing it to their peers.
Strengths of OpenSRF
As a service infrastructure, OpenSRF has been remarkably reliable. We initially deployed Evergreen on an unreleased version of both OpenSRF and Evergreen due to our requirements for some functionality that had not been delivered in a stable release at that point in time, and despite this risky move we suffered very little unplanned downtime in the opening months. On July 27, 2009 we moved to a newer (but still unreleased) version of the OpenSRF and Evergreen code, and began formally tracking our downtime. Since then, we have achieved more than 99.9% availability – including scheduled downtime for maintenance. This compares quite favourably to the maximum of 75% availability that we were capable of achieving on our previous library system due to the nightly downtime that was required for our backup process. The OpenSRF “maximum request” configuration parameter for each service that kills off drone processes after they have served a given number of requests provides a nice failsafe for processes that might otherwise suffer from a memory leak or hung process. It also helps that when we need to apply an update to a Perl service that is running on multiple servers, we can apply the updated code, then restart the service on one server at a time to avoid any downtime.
As promised by the OpenSRF infrastructure, we have also been able to tune our cluster of servers to provide better performance. For example, we were able to change the number of maximum concurrent processes for our database services when we saw a performance bottleneck with database access. To go live with a configuration change, we restart the opensrf.setting service to pick up the change, then restart the affected service on each of our servers. We were also able to turn off some of the less-used OpenSRF services, such as open-ils.collections, on one of our servers to devote more resources on that server to the more frequently used services and other performance-critical processes such as Apache.
The support for logging and caching that is built into OpenSRF has been particularly helpful with the development of a custom service for SFX holdings integration into our catalogue. Once I understood how OpenSRF works, most of the effort required to build that SFX integration service was spent on figuring out how to properly invoke the SFX API to display human-readable holdings. Adding a new OpenSRF service and registering several new methods for the service was relatively easy. The support for directing log messages to syslog in OpenSRF has also been a boon for both development and debugging when problems arise in a cluster of five servers; we direct all of our log messages to a single server where we can inspect the complete set of messages for the entire cluster in context, rather than trying to piece them together across servers.
Appendices: Code Examples
- opensrf_core.xml complete example: This complete example of opensrf_core.xml from a working test system is included for your convenience.
- opensrf.xml complete example: This complete example of opensrf.xml from a This complete example of opensrf.xml from a working test system is included for your convenience.
- Python client: A Python client that makes the same OpenSRF calls as the Perl client.
About the Author
Dan Scott is the Systems Librarian for Laurentian University and a
committer for the the Evergreen and OpenSRF projects. You can reach
him by email at dan@coffeecode.net or follow his occasional ramblings
at http://coffeecode.net.

Leonard Parker, 2011-08-01
I was just starting to read the two articles mentioned on the Evergreen site. I think the links found on that site are reversed when one goes to fetch the content of part 1 and part 2 of the topics.
Should you have questions, feel free to drop me a line.