by Rurik Thomas Greenall
Introduction
This paper introduces an ultralightweight “add-on” system for commenting on things in library catalogues, although in reality, the system can be used to comment on any web page containing a minimum of bibliographic data. Additionally, it improves the commenting experience for users by presenting comments on related bibliographic items together and increasing the volume of comments by providing access to the same comment system from multiple sites.
Commenting
Commenting is the provision of a space for users to give their opinions, information and feedback on/about the item described on a page. In many contexts, comments are personal opinions of the work in question and can vary from longer book-review type comments to shorter “Awesome!”-type comments. In the case of non-fiction literature, the reviews often provide meta-information about the up-to-date-ness of an item as well as alternative resources. There are a number of reasons to provide this kind of service:
- Adds value to pages about content
- Enriches user-participatory experience
- Provides clues to the reception of collection building strategies
- Provides another point of contact between an institution and its users
Of course, it must be assumed that the likelihood of users commenting is relatively low; it has been pointed out that users do not necessarily expect commenting facilities in online library resources, and additionally, commenters are generally assumed to be a small subgroup of the whole user base [1]. Nevertheless, provision of this feature can prove successful, as attested by the numerous sites that provide this kind of service.
Because the volume of comments is expected to be relatively low, it is necessary to improve the way in which user comments are distributed online — if a comment on an item exists, then it should also be viewable in other contexts where it is relevant. The best example of this is two editions of the same book existing in the same catalogue: comments on one edition should appear in the comment space of the other edition. The system developed here uses the FRBR entities Work and Manifestation, where a Work is the top-level concept of the creative work, and a Manifestation is a published version of this Work [2]. This factor and the further distribution of comments to/from other sites increases the “comment ecology”, or volume of comments and users who comment.
Existing Approaches
The existing approaches to commenting in library catalogues fall into one of two categories: local and distributed, which in turn can be modular or built-in. In the case of “local”, a comment system is implemented for a single site; this may be as part of a configurable part of the system (as is the case for Koha [3]) or as an external module. In either case, if the catalogue is FRBR-aware, it can support Work-level commenting, but the extent of the comment ecology will be small and these systems typically only work well for libraries with very large user bases.
Bibliocommons provides a distributed, built-in approach whereby the OPAC is provided as software as a service. In fact, each library has a DNS subdomain of bibliocommons.com (for example http://wilmette.bibliocommons.com and http://christchurch.bibliocommons.com), and there is a shared, Work-related comment ecology that functions for all media types. Because this functionality is bound to the Bibliocommons platform, it cannot be implemented in other existing systems; the Bibliocommons sites do however show that commenting systems engage users and the feedback provided is often useful.
The distributed, modular approach is adopted by the Swedish project Öppna bibliotek [4] (translation: open libraries), which provides an API for submission and retrieval of comments. This approach creates a large-scale comment ecology, but it does not support Work-level commenting. Additionally, it has a technical overhead that is potentially insurmountable for many libraries as it is an API, not a complete, easily installable system.
It is apparent that the Bibliocommons approach is both elegant and creates a good level of comment frequency on items in the catalogue. It could be said that this paper attempts to provide Bibliocommons-style commenting without using that system. Note, however, that using an integrated system obviously provides benefits regarding knowledge of and access to the structure of the content (allowing more precise facet appraisal to identify Works).
System Design
The system needs to generate a Work ID and link to a comment space associated with this ID. In this scenario, two external systems are assumed to exist: one that provides the Work ID and one that provides the comment space for the Work ID that is passed to it.
To find a Work ID, the system must pass a variable that allows the Work-ID service to identify the Work. Thus three further system components are necessary:
- extraction of criteria for Work identification
- designation of Work IDs
- linking to comment space
Figure 1 shows how these components interact with each other.
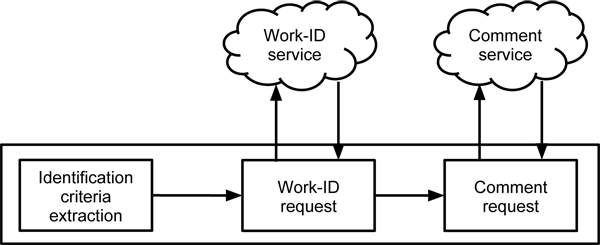
Figure 1. System Components
Functional Requirements
The functional requirements for the system are:
- The system must automatically find criteria on the local page which allow a Work to be identified
- The system must provide a comment space which is explicitly connected to the Work that has been identified so that users can view or add comments
- The system must, upon encountering errors, provide an intelligent failure method
Additional requirements for the software:
- The system must require a minimum of programming for installation
- The system must use cross-platform HTML and AJAX on the client side
- The system must cost as little as possible, and preferably be free
Further, functional requirements for the Work-ID service:
- Upon receipt of a Manifestation identifier the system must return a unique ID that can be used to identify Works, or, in the case of no Work identifier being found, fail gracefully
- The system must cost as little as possible, and preferably be free
And the comment service:
- The system must provide a comment space that can be distributed across multiple web domains and sites based on shared IDs
- The system must be simple to install and not require modification of the code to work for each site
- The system must provide robust and reliable methods for authentication, including single sign-on for libraries that wish to implement this
- The system must allow export of data to ensure the future stability of the services built upon it
- The system must cost as little as possible, and preferably be free
Implementation
Initially, the system needs to be broken into its components: The comment system, the Work-ID system and the core system that is used to link these together. These components will be treated in turn.
Comment System
The comment system needs to be stable and distributable; there are many examples of commercial services that can be used for this purpose. In the current case, Disqus [5] was chosen for a number of reasons:
- Widely-used, familiar system
- Free
- Good level of support, even for free service
- Well-documented API [6]
- Supports multi-domain and multi-site, distributed commenting
- Options for login, including single sign-on (for paid plan)
- Small code footprint
The standard code to include Disqus commenting was adapted to receive a Work ID, but otherwise remains largely unchanged. This code can be found in https://github.com/brinxmat/Global-book-commenting/blob/master/globalcomments.js.
Work-ID System
Work IDs are typically considered difficult to generate; this is because it is not easy to identify which Expressions, Manifestations or Items are to be linked to a Work. Typically, various facets of the bibliographic record are used, including standard titles, responsible authorities and so forth. Because the current implementation assumes nothing about the systems into which it is to be integrated, it cannot be assumed that there is access to any of these facets. Rather, the lowest level identifier that is available is taken: ISBNs.
At this point, it should be noted that ISBNs are not unique, they are not available for every item, nor are they consistent in identifying the same kind of thing; however they are largely unique and largely represent Manifestations. In the absence of true Manifestation IDs, ISBNs are the best and most realistic option. It is possible to combine an ISBN search with the other facets mentioned above. However, for the sake of simplicity, this approach has not been used here; indeed, it is not clear that this approach would make enough difference for it to be worthwhile. The current approach simply identifies one of six possible ISBN types, whereas identifying titles and author names on pages is far from simple as these are largely represented as text strings that are not semantically marked in a way that makes it possible to identify them programmatically.
ISBNs largely identify books, and this means that much content on the target site will not be identified as a Work, but rather as a Manifestation — consequently, the system fail-safes to providing a unique ID where none is provided. This issue can easily be addressed by querying other services that provide identifiers for other item types (for example, ISMNs and EANs).
For the current implementation, a service was built around OCLC’s xISBN [7] and xOCLCNUM [8] services. These were chosen because they are relatively stable, have straightforward ReSTful APIs and encompass a large volume of content (albeit scantier for Works in languages not widely covered in WorldCat). The LibraryThing API [9] was also considered, but it provided no transparent method of assigning a unique ID for Works as it just returns a list of ISBNs. These services have restricted free use (one thousand requests per day) and do not permit the caching of data retrieved from them [10] .
The service was designed as described in figure 2.
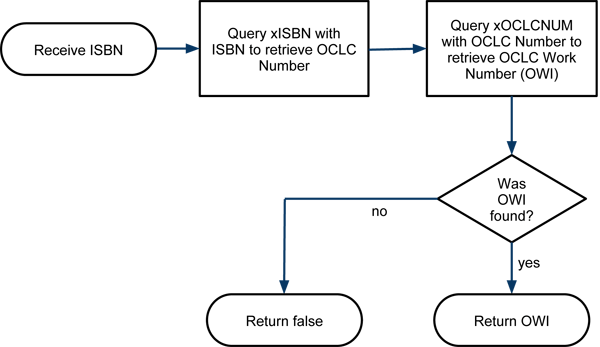
Figure 2. Work IDs
The system was implemented in PHP, the code: https://github.com/brinxmat/Global-book-commenting/blob/master/oclc.php.
Core System
The core system has three major processes:
- finding ISBNs
- passing found ISBNs to the Work-ID service
- initializing the comment service with an ID
The initial step is to identify the ISBNs on the page where the code is embedded. This was done using four regular expressions to identify ISBN10/ISBN13 (with and without separators) on the page. The flow is described in figure 3:
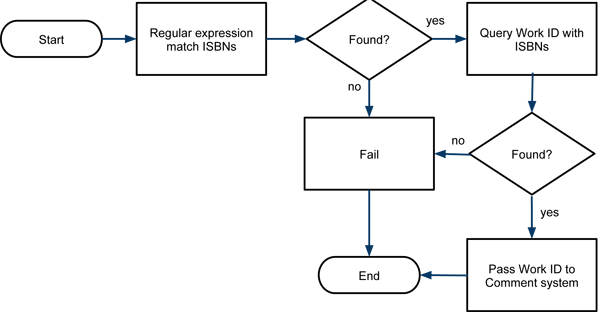
Figure 3. Core system flow
The software was implemented in JavaScript, using the jQuery [11] framework and a jQuery plugin for cross-domain AJAX [12] ; the latter is necessary because the Work ID service is queried using this, although it is not necessary to do this in this way — alternatives include JSONP [13] and CORS [14] . Using JavaScript in this way means that after the jQuery and the plugin are loaded, those wishing to use the comment system need only include a single <div> tag and a <script> tag.
The JavaScript code: https://github.com/brinxmat/Global-book-commenting/blob/master/globalcomments.js.
A live example can be found at http://folk.ntnu.no/greenall/comments.
Installation
The system is simple to install. Load jQuery and the plugin, then put
<div id="disqus_thread"></div>
in the body of the page and
<script type="text/javascript" src="path/to/globalcomments.js"></script>
just before closing the closing </body> tag (as it is important to load the script after the page has loaded).
The Road Ahead
The system has not been widely tested, so it is difficult to know whether it would take the strain of real use. More testing across more sites is the first task that needs to be performed, and the author welcomes interested parties to get in touch about this.
Improvements can be made to every part of the system, including removing reliance on jQuery and the cross-site AJAX plugin (these potentially conflict with systems already using jQuery) and improving the ISBN matching regular expressions.
It is worth looking for other systems that can return Work IDs for other content types so that this feature can be incorporated. Additionally, the benefits of improved Work identification balanced against the cost of more complex installation should be investigated; this will solve many of the issues that arise from using ISBNs as the sole identifiers of Manifestations.
While the system is a very early phase in its development, it has many of the “must-have” features that are seen in higher-end systems, without the costs. It also shows that lightweight solutions that are implementable in very many contexts can be used to solve relatively complex problems in an elegant way.
Source Code
- DISQUS integration: https://github.com/brinxmat/Global-book-commenting/blob/master/globalcomments.js.
- OCLC integration: https://github.com/brinxmat/Global-book-commenting/blob/master/oclc.php
- Global Commenting: https://github.com/brinxmat/Global-book-commenting/blob/master/globalcomments.js
References
1. Tam W, Cox A M, Bussey A. Student user preferences for features of next-generation OPACs: A case study of University of Sheffield international students. Program: electronic library and information systems. 2009;43(4):349–374.
2. IFLA Study Group on the Functional Requirements for Bibliographic Records. Functional requirements for bibliographic records: final report [Internet]. München: K.G. Saur; 1998 [cited 2011 May 23]. Available from: http://www.ifla.org/files/cataloguing/frbr/frbr_2008.pdf
3. Koha – Open Source ILS – Integrated Library System [Internet]. [cited 2011 May 23]; Available from: http://www.koha.org/
4. Biblioteket.se. Öppna bibliotek [Internet]. Öppna bibliotek. [cited 2011 May 22]; Available from: http://biblioteket.se/default.asp?id=14392
5. Discover your community – DISQUS [Internet]. [cited 2011 May 22]; Available from: http://disqus.com/
6 DISQUS Docs | Developers [Internet]. [cited 2011 May 22];Available from: http://docs.disqus.com/developers/
7. WorldCat Web service: xISBN [OCLC – WorldCat Affiliate tools]: xOCLCNUM API [Internet]. [cited 2011 May 22]; Available from: http://xisbn.worldcat.org/xisbnadmin/xoclcnum/api.htm
8. xISBN [WorldCat Affiliate Program] [Internet]. [cited 2011 May 22]; Available from: http://www.worldcat.org/affiliate/webservices/xisbn/app.jsp
9. APIs and Easy Linking | LibraryThing [Internet]. [cited 2011 Jun 26]; Available from: http://www.librarything.com/api.php
10. Worldcat: OCLC Affiliate Services Terms and Conditions [Internet]. [cited 2011 May 22]; Available from: http://www.worldcat.org/ldap/terms.jsp
11. jQuery: The Write Less, Do More, JavaScript Library [Internet]. [cited 2011 May 22]; Available from: http://jquery.com/
12. cross-domain-ajax at master from jamespadolsey/jQuery-Plugins – GitHub [Internet]. [cited 2011 May 22]; Available from: https://github.com/jamespadolsey/jQuery-Plugins/tree/master/cross-domain-ajax/
13. JSON-P: Safer cross-domain Ajax with JSON-P/JSONP [Internet]. [cited 2011 May 22]; Available from: http://www.json-p.org/
14. Cross-Origin Resource Sharing [Internet]. [cited 2011 May 22]; Available from: http://www.w3.org/TR/cors/
About the Author
Rurik Thomas Greenall is a research librarian at the Section for information resources of the Library of the Norwegian University of Science and Technology. He is a programmer and data modeller, working mostly with RDF and linked data.
Acknowledgements
The idea for this project originally arose in discussions at the Norwegian Library laboratory (www.biblab.no), where a similar system was outlined for public libraries in Norway.
The author would like to take this opportunity to thank David Massey of Oslo University College for help testing the initial implementations of the software, as well as the editors of the Code4Lib Journal for their help in shaping this text. All errors, of course, remain the sole responsibility of the author

Code4Lib Journal – n° 14 « pintiniblog, 2011-07-27
[…] A Novel Method for Creating a Distributed, Collaborative Commenting Environment for Bibliographic It… […]
SWIB13: semantic web in bibliotheken 2013 | Brinxmat's blog, 2013-11-28
[…] As the system uses ISBNs, the traditional issues are noted (ISBN is not an ID, linking editions, etc.) Might be worth looking at the methods in http://journal.code4lib.org/articles/5339 […]