By Kirk Hess
Introduction
In my first digital library job, every so often I would have to compile reports based on the server logs to answer a question about the site. Questions such as “How many times was X document downloaded”, or “What’s the most popular item in our collection?” were common and I answered them using AWStats data collected from our server logs. However, I was concerned the results were not accurate because of many inconsistencies, such as how many of the IP addresses were from non-.edu domains, or the page entry and exit numbers didn’t match up.
While working on the Illinois Harvest Portal I found there was no web analytics solution enabled on the website, and the web logs were no longer easily accessible. I turned to Google Analytics, which allowed me to answer simple questions about numbers of user hits. But one of the things I found that Google Analytics didn’t do well out of the box was tracking two types of events: clicks on links to other domains, such as the Internet Archive, and clicks which downloaded files. By implementing event tracking, I was able to determine which items were used and which ones weren’t being used, and I could track complete user interactions with the website.
The goal of this paper is to help librarians and programmers who develop and maintain digital library websites to use events and site search within Google Analytics. By gathering better intelligence about what users are doing, you can determine what you should change on the website to make it more useful to users without having to do extensive usability tests or human-computer interaction (HCI) studies.
Web Analytics
The Digital Analytics Association defines web analytics as:
… the measurement, collection, analysis and reporting of Internet data for the purposes of understanding and optimizing Web usage. [1]
There are many potential solutions, both log based and script based for web analytics. Logging solutions use raw server logs to mine the information for usage trends. Your typical AWStats logs will track hits, which usually are HTTP GET requests for something, a page, an image, a file, etc. Hits on your webserver are going to be from humans, but because of the way the web is crawled, a substantial portion will often be from various automated systems like GoogleBot or BingBot. Solutions like AWStats do a good job of trying to filter out all this noise, but the problem is you never get rid of 100% of the noise. In addition, a significant subset of bots try their best to avoid detection.
Google Analytics uses a JavaScript-based approach that injects a tiny image onto each page for tracking. Because most automated crawlers do not have JavaScript or cookies enabled, and most modern browsers do, you have a high level of confidence that the hits captured are human users. Google Analytics is a simple, inexpensive, and effective way to capture data about your users.
Google Analytics Basics
Google Analytics is easy to set up on any website following the basic instructions. Generally, you sign in, input the information about your site and put the JavaScript <script> element in the <head> portion of your website. Of course, every system builds the <head> element for pages a little differently, and since you want to include the tracking cookie on every page in a consistent way you’ll need to figure out how to do this in your system. This hopefully is as simple as putting it in an include file which is included when the page is rendered.
<script type="text/javascript">
var _gaq = _gaq || [];
_gaq.push(['_setAccount', 'UA-XXXXXXXX-1']);
_gaq.push(['_setAllowLinker', true]);
_gaq.push(['_setDomainName', 'illinoisharvest.grainger.uiuc.edu']);
_gaq.push(['_setAllowHash', false]);
_gaq.push(['_trackPageview']);
(function() {
var ga = document.createElement('script'); ga.type = 'text/javascript'; ga.async = true;
ga.src = ('https:' == document.location.protocol ? 'https://ssl' : 'http://www') + '.google-analytics.com/ga.js';
var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ga, s);
})();
</script>
Finally, once you figure this out it’s hard to tell if tracking actually works because there is usually some minor amount of lag in between installing the code and actually getting data in the online tool. To see the tracking cookie using Firebug (or its Chrome/IE/Safari equivalents), you simply refresh the page with the net, images tab visible. If you see an image starting with _utm.gif, you are tracking that page.
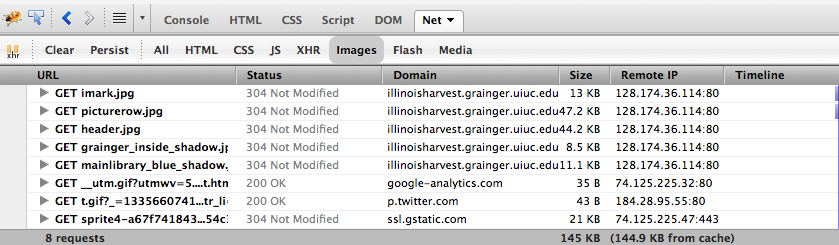
Figure 1.
Firebug showing _utm.gif?… tracking cookie.
Tracking
Events
To gather information such as clicking external links or downloading files, we’ll enable event tracking to track those events. Again, Google has this documented pretty well online. Events are segmented into categories, actions, and labels. For our site, I chose two types of categories of events, external and download. For actions, I chose click, and click-
In your system you may simply be able to change the code that displays links, however in our system that was too complex so instead I wrote a jQuery script that does the work after the page has been loaded, which would also be useful for tracking a vendor system that doesn’t allow changes to the code. jQuery binds an event handler to the “click” JavaScript event:
<script type="text/javascript">
if (typeof jQuery != 'undefined') {
jQuery(document).ready(function($) {
var filetypes = /\.(pdf|txt|dijv|xml)$/i;
var baseHref = '';
if (jQuery('base').attr('href') != undefined)
baseHref = jQuery('base').attr('href');
jQuery('a').each(function() {
var href = jQuery(this).attr('href');
if (href & (href.match(/^https?\:/i)) & (!href.match(document.domain))) {
jQuery(this).click(function() {
var extLink = href.replace(/^https?\:\/\//i, '');
_gaq.push(['_link', href]);
_gaq.push(['_trackEvent', 'External', 'Click', extLink]);
if (jQuery(this).attr('target') != undefined & jQuery(this).attr('target').toLowerCase() != '_blank') {
setTimeout(function() { location.href = href; }, 200);
return false;
}
});
}
else if (href & href.match(filetypes)) {
jQuery(this).click(function() {
var extension = (/[.]/.exec(href)) ? /[^.]+$/.exec(href) : undefined;
var filePath = href;
_gaq.push(['_trackEvent', 'Download', 'Click-' + extension, filePath]);
if (jQuery(this).attr('target') != undefined & jQuery(this).attr('target').toLowerCase() != '_blank') {
setTimeout(function() { location.href = baseHref + href; }, 200);
return false;
}
});
}
});
});
}
</script>
The result is you get code like this injected onto your links:
_gaq.push(['_trackEvent', 'External', 'Click', extLink]
Site Search
Another useful option we can enable is search tracking, and this is covered pretty well by the online documentation. Here’s an example of our configuration for tracking site search.
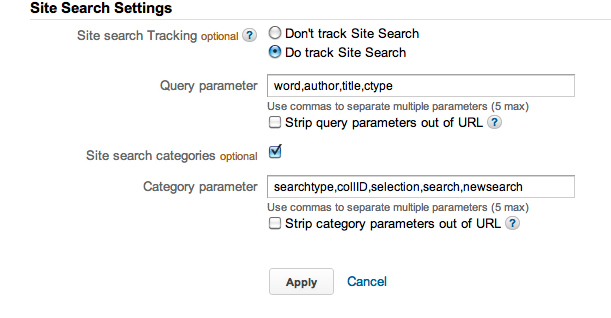
Figure 2.
Site search configuration.
Collect Data
Once everything is set up correctly, you will need to wait as activity is collected. Google Analytics has some very nice dashboard utilities to view the results of the site in real-time. Below are a couple of images of the results that I will discuss further in the Analysis section: top pages by events and search results.
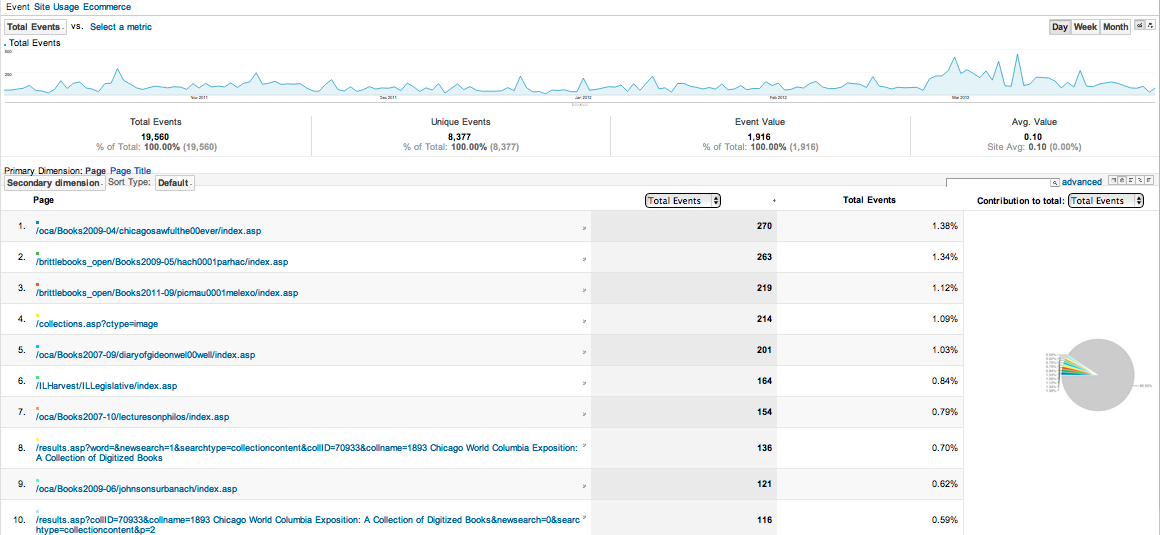
Figure 3.
Report of top pages with events from October 1 2011 to April 1 2012.
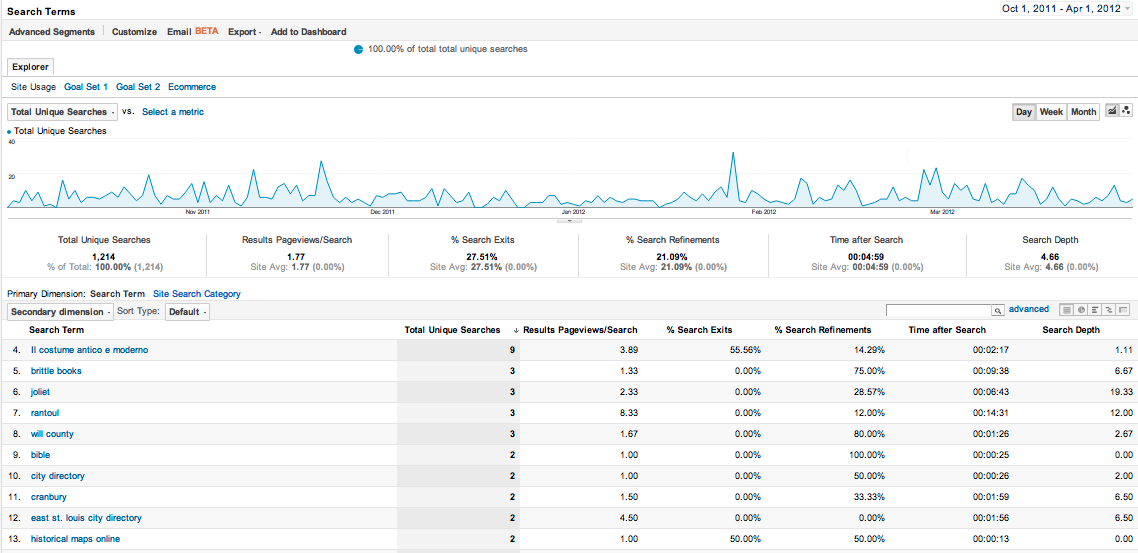
Figure 4.
Report of search queries from October 1 2011 to April 1 2012. Browse results not displayed.
Export Data
By only using the dashboard utility, I found that I wasn’t getting the answers I wanted–especially for downloads. The downloads reports either were too granular (by extension) or too broad (all events), and they couldn’t answer one important question: what wasn’t being used? Google provides an API to extract data into whatever format you like; since our data is stored within a MS SQL database I wanted to export it into a table so I could correlate the results to all items in a particular collection. I found it easier to do with java; other programming languages are supported.
Code example: Java class for extracting data
/**
* Retrieve data from the Google Analytics API.
*/
public class GoogleAnalytics {
// Credentials for Client Login Authorization.
private static final String CLIENT_USERNAME = "xxx";
private static final String CLIENT_PASS = "xxxx";
private static final String[] eventDates; //define as needed
// Table ID constant
private static final String TABLE_ID = "ga:123456789";
public static void main(String args[]) {
try {
// Service Object to work with the Google Analytics Data Export API.
AnalyticsService analyticsService = new AnalyticsService("gaExportAPI_acctSample_v2.0");
// Client Login Authorization.
analyticsService.setUserCredentials(CLIENT_USERNAME, CLIENT_PASS);
// Get data from the Account Feed.
getAccountFeed(analyticsService);
// Access the Data Feed if the Table Id has been set.
if (!TABLE_ID.isEmpty()) {
// Get profile data from the Data Feed.
getDataFeed(analyticsService);
}
} catch (AuthenticationException e) {
System.err.println("Authentication failed : " + e.getMessage());
return;
} catch (IOException e) {
System.err.println("Network error trying to retrieve feed: " + e.getMessage());
return;
} catch (ServiceException e) {
System.err.println("Analytics API responded with an error message: " + e.getMessage());
return;
}
}
/**
* @param {AnalyticsService} Google Analytics service object that
* is authorized through Client Login.
*/
private static void getAccountFeed(AnalyticsService analyticsService)
throws IOException, MalformedURLException, ServiceException {
// Construct query from a string.
URL queryUrl = new URL(
"https://www.google.com/analytics/feeds/accounts/default?max-results=50");
// Make request to the API.
AccountFeed accountFeed = analyticsService.getFeed(queryUrl, AccountFeed.class);
// Output the data to the screen.
System.out.println("-------- Account Feed Results --------");
for (AccountEntry entry : accountFeed.getEntries()) {
System.out.println(
"\nAccount Name = " + entry.getProperty("ga:accountName") +
"\nProfile Name = " + entry.getTitle().getPlainText() +
"\nProfile Id = " + entry.getProperty("ga:profileId") +
"\nTable Id = " + entry.getTableId().getValue());
}
}
/**
* @param {AnalyticsService} Google Analytics service object that
* is authorized through Client Login.
*/
private static void getDataFeed(AnalyticsService analyticsService, String[] eventDates)
throws IOException, MalformedURLException, ServiceException {
StringBuffer skippedRecords = new StringBuffer();
int skipCount = 0;
// Create a query using the DataQuery Object.
for(String eventDate : eventDates){
DataQuery query = new DataQuery(new URL(
"https://www.google.com/analytics/feeds/data"));
query.setStartDate(eventDate);
query.setEndDate(eventDate);
query.setDimensions("ga:eventlabel,ga:eventcategory,ga:pagePath");
query.setMetrics("ga:totalevents,ga:uniqueevents");
query.setSort("-ga:totalevents");
query.setMaxResults(500);
query.setIds(TABLE_ID);
// Make a request to the API.
DataFeed dataFeed = analyticsService.getFeed(query.getUrl(), DataFeed.class);
}
}
Analyze Data and Next Steps
One of the things that I wondered about with Illinois Harvest on my first day was did we have any users at all? The basic statistics showed over the previous 6 months a total of 15k unique users visited the site. On average, those users visited about 4 pages, with a bounce rate (a.k.a. a single-page visit) of approximately 35%.
Figure 3 shows that we had many users clicking on external links and download links – the top 3 pages were digitized book landing pages, while the 4th page for the collection summary contains many external links. Specifically, the reason the top page had so many hits is it’s one of the references for a Wikipedia page about the Iroquois Theatre fire.
Figure 4 shows an interesting yet disturbing result – after removing browse results, the site search is rarely used. Traffic to the site lands deep into the website, either at a location determined by an external search engine, the library catalog, or other direct links. The site was designed about 6 years ago when portals were considered important and it doesn’t appear to be working for users who arrive from a search engine.
By exporting the data and comparing to our item level records, I was able to see that most items were never used, where use being defined as a click to an external link or downloaded a file. Figure 5 shows one of our collections, and while a couple of links get a fair amount of clicks, the vast majority of items in this collection of about 23k items are never clicked or downloaded. The disparity between the size of a collection and use my colleagues Harriet Green and Richard Hislop have termed ‘Effective Collection Size’ or ECS, is something we are continuing to investigate as part of larger datasets.
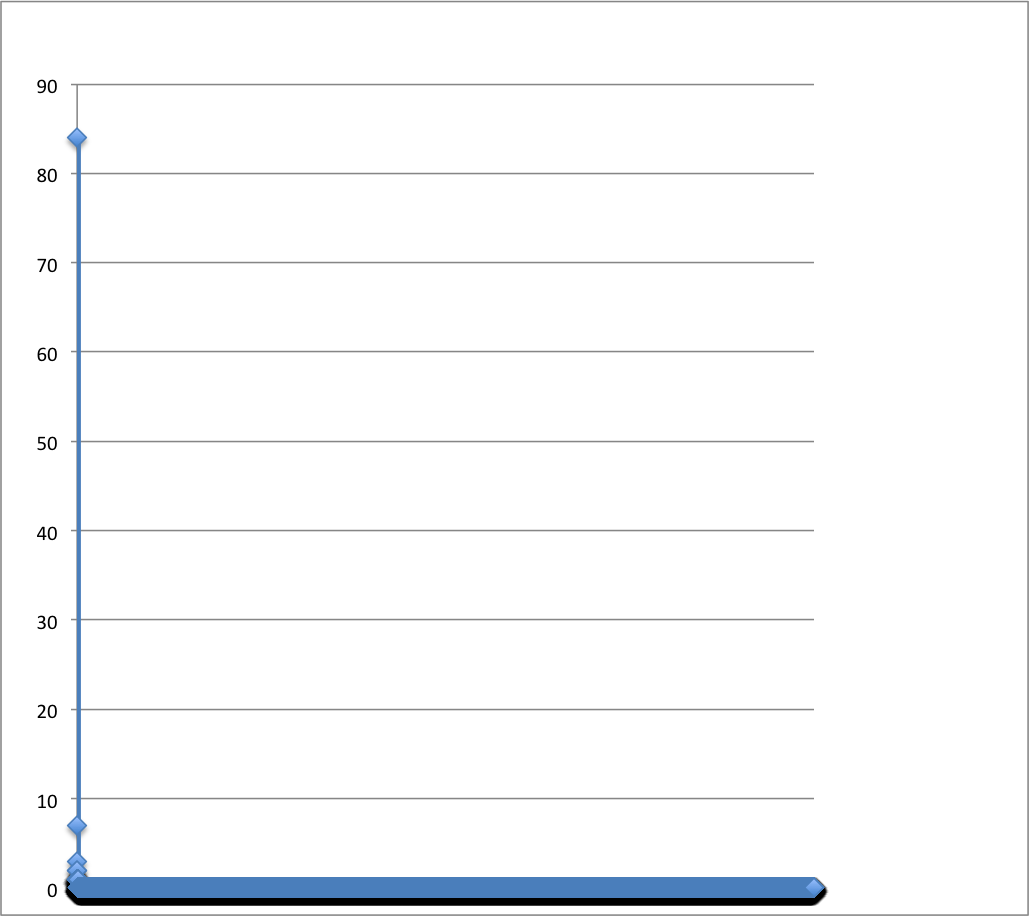
Figure 5.
Graph of item usage from IDEALS collection on Illinois Harvest, July 1 2011 – November 1, 2011
Next Steps
The Illinois Harvest user interface will be redesigned in 2012 and hopefully some of these lessons will be part of those efforts. Specifically, I think site search needs to be examined more closely, probably as a full HCI study, to make sure it’s useful for users.
By analyzing a sample set of 40k items held by our Literature and Language Library, we’ve found a similar disparity between the size of a collection, in this case both physical and digital items, and use. We’re going to be exploring how to improve ECS in a collection by examining a much larger data set of 22 million items indexed in the University of Illinois Library catalog. Based on the network analyses resulting from this project, we will begin development of an enhanced recommender system for library catalogs and digital libraries that retrieves richer search results from a library collection search based on network analysis of subject relevancy, circulation data of items, and usage data for items that share interrelated subjects.
Notes
[1] About Us. Digital Analytics Association. Available from http://www.digitalanalyticsassociation.org/?page=aboutus
Appendix: Resources
Tools Used
- JavaScript
- jQuery
- Java
- MSSQL
- Code examples are available on GitHub
Further reading about Google Analytics and Libraries
- Prom, Christopher J. Using Web Analytics to Improve Online Access to Archival Resources. American Archivist, Spring/Summer 2011, Vol. 74 Issue 1, p158-184
- Marshall Breeding, “An Analytical Approach to Assessing the Effectiveness of Web-based Resources,” Computers in Libraries 28 (January 2008): 20–22
- Feng Wei, “Using Google Analytics for Improving Library Website Content and Design: A Case Study,” Library Philosophy and Practice (July 2007), http://digitalcommons.unl.edu/libphilprac/121
About the Author
Kirk Hess (kirkhess@illinois.edu) is Digital Humanities Specialist at the University of Illinois Urbana-Champaign, and holds a MLIS from the University of Illinois Urbana-Champaign. back

New Code4Lib Issue Out | Learn@The Corkboard, 2012-06-25
[…] Discovering Digital Library User Behavior with Google Analytics […]
Judah, 2012-06-28
Great article. Very interesting to learn that search was so under-utilized.
Weekendvitaminen #33 « Zeemanspraat, 2012-07-06
[…] Kirk Hess, Discovering Digital Library User Behavior with Google Analytics (Code4Lib, Issue 17) […]
UX and SEO — Scott W. H. Young, 2015-04-27
[…] The role and impact of SEO has been a focus of study for some time now. The conversation around SEO is dominated by digital marketers and others with commercial interests, but librarians have been drawn to this discussion after observing Google’s impressive abilities and accomplishments (to the point of near-total domination of search traffic). Our own library dean has published a paper addressing the low indexing rate of institutional repository content in Google Scholar. Others within libraries have explored social traffic for digital collections, SEO for library web content, and the use of Google Analytics for understanding user behavior. […]