By Terry Catapano, Joanna DiPasquale, and Stuart Marquis
Introduction
Columbia University Libraries (CUL), like many institutions, has a huge backlog of archival collections about which our patrons may not know. These collections are variously presented in finding aids (paper or electronic), collection overviews, or online exhibits, or some combination thereof. Although most collections are cataloged in our OPAC, CLIO, they did not have a special or easily-linkable presence on the Libraries’ public website. Searching for a collection was not transparent. In many cases, it was not clear that related or similar-interest items may reside in a different repository on campus. In other cases, the sheer number of results — including books, audio, and archives — overwhelmed the user. Additionally, the web presence of these collections varied greatly. While some had associated scanned paper or electronic finding aids, others had collection overviews, pictures, or occasionally more fully developed online exhibits. The result was the Libraries had a large amount of archival collections and no uniform way to find them, effectively hiding some of our most significant resources.
In Spring 2007, the Libraries presented a challenge to the authors of this article; design and implement a single web space allowing users to seamlessly access our varied archival collections. We were tasked with finding new technology, developing a website, and establishing a workflow to solve some aspects of this problem. Our goals were to make the search and retrieval of archival collections completely transparent, trustworthy, uniform, and feature-rich. We also needed a solution that used the campus architecture of Solaris and Apache, worked with the Libraries’ MARC data, and generated standards-compliant information for display, harvesting, etc. The solution needed to be scalable, adding new repositories as needed (we have six libraries contributing their collections), and flexible, offering each repository its own areas of customization. Finally, we knew we could make a search engine and web pages, but we also wanted to “do better”. We knew we could present our nicely-structured data in a better format for our users through key new technologies.
We believe our work to combine already-existing tools, such as MARC, with newer software like Solr and Lucene resulted in a method and product of interest to the library information technology community. This article provides our rationale for technology choices, discusses our basic framework for providing a search interface, and addresses metadata issues for the creation of search engine records and collection-level pages.
Rationale and Design
The first challenge in the Archival Collections project was to assemble and relate all of the descriptive data the Libraries’ archival collections. Columbia University Libraries includes several units which hold archival and manuscript material. The distribution of collections across repositories is uneven as are the methods and degree of intellectual control over them. Ultimately, we aimed to convert the data to Encoded Archival Description (EAD) for internal maintenance and external exchange. Full scale conversion to EAD would be difficult, however. EAD had not been previously well-supported at the Libraries and cataloging methods as well as stylistic conventions for existing finding aids varied across, and even within, repositories. The greatest variety of practice involved the “container lists,” an information layer used to describe the arrangement of the constituent components (e.g., series, subseries, folders, etc.) of the archival collections. This made it very difficult to convert these items to EAD at the level of the “Description of Subordinate Components,” or <dsc>, element. However, there was a great amount of highly consistent description at the collection level. Cataloging of archival collections in MARC has been underway at Columbia for over a decade. To illustrate, the repository with the largest number of archival and manuscript collections, the Rare Book and Manuscript Library (RBML), had roughly 90% of its collections represented in MARC. For this reason it was decided we would initially focus on description at the collection level. Further, as the largest, finest-grained, and most-uniform collection data available was in MARC, we quickly established our OPAC as the best data source for collection information.
While it was felt EAD provided the most appropriate schema for the portal, MARC and the significant resources and infrastructure deployed around it offered greater opportunities for development of a workflow. Rather than developing an EAD document management system from scratch, we could simply leverage existing systems and skills already deployed in our OPAC. Collection records would be created and updated in MARC. These could be extracted as MARC XML and converted to EAD (at the collection level at least) using XSLT. The EAD files could serve as the source for further XSLT conversions to produce the data and outputs needed for the portal. Also, the collection-level EAD records could serve as the basis for full EAD finding aids when the CUL could devote sufficient time and resources to the development and support of a comprehensive EAD based program for archival control.
Our next challenge was to work with existing infrastructure to provide a “portal” into our archival collections, develop uniform pages for each item, and smoothly process the data. As we searched for software to build the Archival Collections Portal, we wanted to fit any possible solutions into Columbia University Libraries’ current setup. To this end, we knew Lucene would be our search engine’s foundation. [1] Lucene’s extensive set of APIs had proven useful for many other CUL projects, and was flexible, speedy, and well-established. However, it required additional Java class development and did not contain particular features, such as faceted searching, right out of the box. As we investigated how to incorporate new features into our current Lucene setup, we discovered Solr, a lightweight framework sitting atop Lucene, which provided an administrative interface, an easy configuration, and — excitingly — a faceted search feature. [2] These features would make development of the Portal much easier, because it shifted the production focus from back-end to front-end development, allowing us to focus on customization. Most importantly, it produced result object sets and metadata that were widely interpreted; it provided outputs in JavaScript Object Notation (JSON), Python, XML, and Ruby. We quickly decided to install and test Solr.
At the time, Columbia University’s servers did not support Python or Ruby, so we needed to rely upon XML/XSLT or JSON/JavaScript to write our front-end search interface. While we found Solr’s XML output handy, parsing large result sets was slow. In contrast, JSON parsing was quick, flexible, and effective. JSON output became our output of choice.
Meanwhile, the new developments in MIT’s Exhibit software piqued our curiosity. [3] Exhibit’s available API parses a JSON object and creates beautiful and feature-rich websites from the data. We decided to experiment with Solr’s functions and these ready-made JavaScript classes. We immediately ran into a stumbling block; Exhibit requires a “ready” JSON object to parse, which meant we needed to create a wrapper function to serve up the search results. Without a readily available scripting language like PHP on our Tomcat server, we would need to rely on JSP. We created a basic JSP page to start. It worked fine, but created an additional layer of complexity, which made us unhappy. Additionally, Exhibit proved less readily customizable than we had hoped. Its myriad features were more than we needed, while its CSS classes proved somewhat difficult to integrate into our own web documents. We realized we wanted to change enough about Exhibit to meet our archivists’ and our data needs that we decided to write our own front-end code. With these decisions in place, we began our implementation phase.
Implementation
Back-end processing and metadata workflow
The Portal data compilation begins with an extraction from the OPAC of MARCXML versions of collection records, written to directories for each repository. The script performing the extraction selects all records cataloged at the collection level (i.e., with a “c” character at leader position 07). Six files of MARC records, one for each repository are written to a directory on our Unix server.
A Perl script controlling the processing of the data for the portal likewise runs daily, after the export of MARC data from the OPAC. The procedure is illustrated in Figure 1 and runs as follows:
- Split each “repository” MARC file into individual MARC records, one for each collection, then write to the corresponding directory for the collection’s holding repository.
- For each new or updated collection MARC file, run an XSLT stylesheet and output an EAD file.
- For each new or updated EAD file, run an XSLT stylesheet to create a static HTML “collection page” and post to a directory on the CUL web server.
- For each EAD file, run an XSLT stylesheet which outputs a single file containing all the data for the Lucene index.
- HTTP POST the file containing the data to Solr.
- Commit the changes and optimize the index.
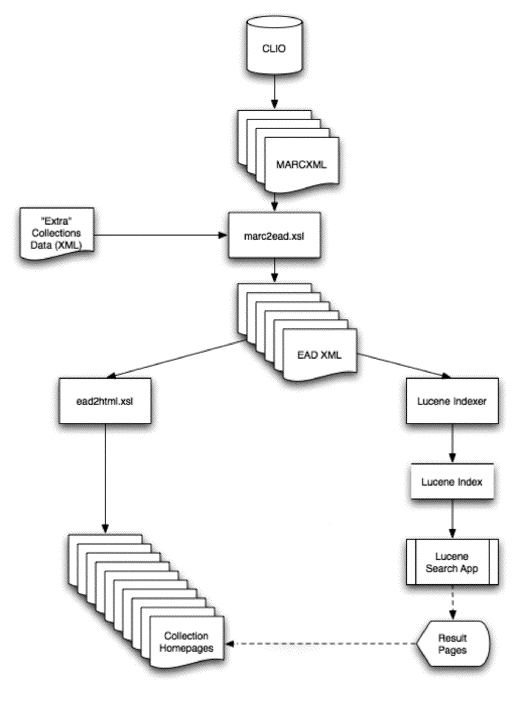
Figure 1 – Flow chart [View full image]
This script can be run in batch mode or via the command line. In batch mode, it searches for new records or updates and initiates the processes in Figure 1. Run on the command line, it gives us a significant set of functions to fine-tune our application. For example, this method allows us to build a collection on one or more server instances (development, test, or production), only run specific XSL transformations, reindex Solr, and re-process individual collection pages. We can trigger processing on one item or a range of items, one or many repositories, etc. This additional set of tools provides us the ability to isolate items for troubleshooting and make modifications without harming other areas of the Archival Collections Portal.
Metadata Issues and Remediation
During the development of the portal workflow, several issues involving the quality and adequacy of available MARC data arose. Not surprisingly, the MARC cataloging in our OPAC was not perfect. Many records, for example, were incorrectly cataloged as collection records (i.e. ‘c’ leader position 07). Most frequently the culprits were records for individual manuscripts. Likewise, some thought was given to using the leader position 08 (Type of Control) to determine if a record was of archival material. Combined with leader position 07, this would have made for a simple method to select only archival collection records. In practice, however, only 388 of 7490 archival collection records employed the “a” value (archival) in leader 08. Selection then would depend on a combination of location codes and the leader position 07.
Cataloging practices and OPAC functionality also proved inhibiting in the handling of hyperlinked content. There appears to be a widespread misunderstanding that all hyperlinking from a MARC record must be from an 856 field. If and when this is not a misunderstanding, limited OPAC functionality enforces the practice. In Columbia’s case, only 856 fields were configured in our Voyager catalog to generate hyperlinks when displayed. As often is the case, practice followed function and catalogers placed all hyperlinks in the 856 field, regardless of the role of the linked content. In fact, MARC permits hyperlinks in several fields. Particularly relevant to our concerns are the 555/Cumulative Index-Finding Aids Note and 540/Terms Governing Use and Reproduction Note fields.
As part of an earlier initiative by the Libraries Digital Program Division, most of the hard copy finding aids from the Rare Book and Manuscript Library had been scanned and converted to PDF. Other projects resulted in the creation of EAD, HTML, and MS Word finding aids which were posted on the Libraries website. The Portal aimed to bring together these digital finding aids with the collection data in the MARC records. Additionally, in some cases archival material had been digitized and this content too was to be integrated with other collection information in the portal. Relying on the 856 field alone to contain hyperlinks semantically overloaded the field. For example, it was difficult to simply create the proper link text for a URL (“Online Finding Aid” or “Related Digital Content”) on the HTML collection page. Using the 555 field for links to finding aids, the 540 field for linked HTML permissions policy statements, and the 856 for links to related content would not only be perhaps more bibliographically proper, but would also greatly simplify processing.
Another problem had to do with strict adherence to cataloging rules. Most of the MARC collection records followed the rules set forth in the Archives, Personal Papers, and Manuscripts (APPM) cataloging manual. Section 1.1B4 of APPM recommends the use of such terms as “Papers,” “Records,” and “Collection” for the Title proper of an archival collection. Combined with a main entry in a traditional catalog display typical of an OPAC, this might produce a rough hewn, somewhat understandable heading such as “Smith, John 1822-1907. Papers, 1814-1902.” However, isolated from its record context, or repurposed in even the most simple way (to, say, generate a heading for a web page), the APPM rule falters. The recently released Describing Archives: A Content Standard (DACS) provided an alternative to the APPM style titles. [4] The DACS rules allow greater flexibility, permitting the creation of more readable and independently meaningful titles for archival materials.
Initially the solution for adding or overriding data in the MARC records was to use a separately maintained table containing the additional metadata for the collections. The table was maintained as a spreadsheet and was converted to XML for use as a lookup table by the MARC to EAD XSLT stylesheet. Rather than wait for all the catalog records to be updated, a runtime lookup could add the additional data. The spreadsheet’s primary purpose was to map each MARC record ID (i.e., the 001 field) to the filename of the corresponding digital version of the collection’s finding aid. Since the scanning of the hard copy finding aids for the Rare Book and Manuscript Library took place after and aside from the creation of collection records, some means to link the two was required. Other options were to have staff at RBML manually enter the URL for each PDF to each MARC record, or to have the Library Systems Office develop some automated procedure to load the data in batch to the OPAC. As these involved personnel working in other departments, with their own priorities and commitments. The less disruptive and resource intensive spreadsheet/lookup table emerged as the solution. As the lookup would be performed anyway, the spreadsheet/table was used as the solution to the ungainly APPM Title proper issue. In addition to the URL for the linked finding aid, the table contained “preferred” titles for each collection provided by RBML staff. (See an example of a collections page. [5])
Due to the leveraging of the OPAC as the data repository and add/update system for the Portal, remediation of the repositories’ MARC records began soon after the Portal’s initial development. The MARC to EAD stylesheet had to be adjusted to handle both updated and unchanged records. For example, the stylesheet used the following logic for handling links to finding aids, use policies, and related content :
- when (record contains 555$u):
- then: EAD /otherfindaid/p/extref = 555$u value
- otherwise:
- when (MARC 856$u starts with “Finding aid”):
- then: EAD /otherfindaid/p/extref = 856$u
- otherwise:
- Look up record of collection in table
- EAD /otherfindaid/p/extref = value of finding aid URL in collections table
It perhaps would have been preferable to write back the results of the transformation’s disambiguation to the source data. However, the process we designed was not bidirectional. Enabling modification to the MARC records would have involved coordination with the Libraries Systems Office and likely more commitment of time and resources than were available. The remediation of the source MARC records went quickly, and increasingly the need for the lookup stylesheet waned. Our workflow now entirely draws from the OPAC records. (See Appendix A: Mapping between MARC, EAD, and Lucene index.)
Solr development and front-end functionality
With the data issues resolved, we had content available to use within our indexing tool and front-end search-and-display mechanisms with Solr. Solr’s indexing features provide a set of tools helping us process and display our data. We can select fields to tokenize, control data replication, provide stemming, and enable sort orders through XML configuration files. This easily modified set of files allowed us to add facets, for example, on fields that we did not initially think we needed to facet. Since we could control the search engine’s power independent of the front-end application, we had another area where we could isolate problems, change functionality, and build new features.
Once we indexed our metadata, we needed to provide a search interface. Solr allows us to search over standard HTTP and specify a specific format for our result set. At the time, the most useful result format for us was JSON. Because JSON is easily evaluated to be object-oriented, it was easy to obtain and parse the resulting objects and provide a quick interface. The code to do this is fairly straightforward; Solr runs as a web service, so we simply needed to “talk” to it via HTTP:
- open an AJAX query,
- receive the response, and
- parse the data.
Our basic code took a URL from a GET request, performed some error-checking and query cleaning, did a Solr lookup, and called a parsing function, abbreviated here:
***********************************************************************
* function xmlhttpPost
*
* Takes a URL, opens an XMLHttpRequest, receives data, and sends it back.
*
* Parameters:
* strURL - the concatenated URL that asks for a JSON object
*
************************************************************************/
function xmlhttpPost(strURL) {
// Set graphic
document.getElementById("working").innerHTML =
'<img src="http://www.columbia.edu/cu/lweb/images/icons/searching.gif"
alt="Searching..."/>';
var xmlHttpReq = false;
var self = this;
if (window.XMLHttpRequest) { // Mozilla/Safari
self.xmlHttpReq = new XMLHttpRequest();
} // if mozilla
else if (window.ActiveXObject) { // IE
self.xmlHttpReq = new ActiveXObject("Microsoft.XMLHTTP");
} // if msie
try {
var queryCheck = checkQueryString(strURL);
var queryString = '/findingaids/results.html?' + queryCheck;
self.xmlHttpReq.open("GET", strURL, true);
} // end try
catch (e) {
alert(e);
} // end catch
self.xmlHttpReq.setRequestHeader('Content-Type',
'application/x-www-form-urlencoded');
self.xmlHttpReq.onreadystatechange = function() {
if (self.xmlHttpReq.readyState == 4) {
// call function to update HTML page
updatepage(self.xmlHttpReq.responseText);
} // if 4 / ready
} // onreadystatechange
// clear
self.xmlHttpReq.send(null);
} // end FUNCTION xmlhttpPost
An abbreviated returned JSON object looks like this [6]:
"response":{
"numFound":36,
"start":0,
"docs":[
{
"id":"ldpd_5466921_ead",
"filename":"ldpd_5466921_ead.xml",
"repository_code":"nnc-m",
"audience":"external",
"unittitle":"Henry W. Bellows letters,",
"sort_title":"Henry W. Bellows letters,",
"origination":"Bellows, Henry W. (Henry Whitney), 1814-1882.",
"unitdate":"1861-1863.",
"beginDate":"1861",
"endDate":"1863",
"bioghist":"Unitarian minister; President, United States Sanitary
Commission during the Civil War.\n",
"scopecontent":"Four autograph letters signed by Bellows. Three, dated
July 12 and 31, 1861 and April 1, 1863 are to Samuel B.
Ruggles. The 1861 letters concern the affairs of the
United States Sanitary Commissions...\n",
"subject_t":[
"United States--History--Civil War, 1861-1865--Medical care.",
"United States Sanitary Commission."],
"corpname":["Columbia University,Health Sciences Library,
Archives & Special Collections."],
"corpname_t":[
"Columbia University,Health Sciences Library,
Archives & Special Collections."],
"persname":["Bellows, Henry W. (Henry Whitney), 1814-1882.",
"Bellows, Henry W. (Henry Whitney), 1814-1882.",
"Opdyke, George, 1805-1880.","Rossiter, Thomas Prichard, 1818-1871.",
"Ruggles, Samuel B. (Samuel Bulkley), 1800-1881.",
"Strong, George Templeton, 1820-1875.",
"Opdyke, George, 1805-1880."],
"bioghist_t":[
"Unitarian minister; President, United States Sanitary
Commission during the Civil War.\n"],
"unittitle_t":[
"Henry W. Bellows letters,"]
} // etc.
With a results set of structured data in hand, we could then parse the data, update an HTML page display, provide faceting, and allow users to paginate through the results. There are two usable methods to parse these JSON objects: first, the standard JavaScript eval() function will parse a JSON output into an object-oriented format, and second, a function called parseJSON(). [7] Both are recursive, and both are easily implemented.
Once parsed, the JSON object above can be referenced and used on a web page. For example, to reference the biographical history (bioghist) field in the object above, we can simply say:
document.write(responses.response.docs[0].bioghist);
// prints "Unitarian minister; President, United States
// Sanitary Commission during the Civil War."</code>
</pre>
<p>We can also update an area of an HTML page with this data:</p>
<pre><code>document.getElementsById("biographyArea").innerHTML =
"<p>" + responses.response.docs[0].bioghist + "</p>";
By iterating through our result set and selecting particular fields to display, we can present a basic search results screen. However, the tools to move beyond this presentation are inherent in the Solr framework, and we took advantage of many of its features. Solr’s API supports pagination, highlighting, sorting, and faceting, making our user interface very rich in functionality. [8] Faceting, in particular, provided helpful end-user and internal features. For example, through our subject facet, users can perform a search and learn about the types of subjects in their result set. Columbia archivists found this feature very useful as well for internal quality assurance, using the facets to see where subjects were inconsistent, needed de-duplication, or needed augmentation.
Future Plans
Incorporation of Full EAD Instances
The Archival Collections Portal and its associated workflow currently makes light use of EAD. The collections data is created and maintained in the OPAC, and the EAD produced is at the collection level. In 2008 CUL will begin development of a supported and standardized workflow for the Rare Book and Manuscript Library to produce full EAD for new and newly revised finding aids. These will for the time being continue to be treated as further collection information linked from the 555 field of the corresponding MARC record. We will, however, begin to consider how best to incorporate the full EAD into the search application itself. For the intermediate term, at least, the portal will contain data for many collections only at the collection level, while an increasing number of others will have data at lower levels. The incongruity of size among collection descriptions will certainly have consequences on overall retrieval recall and precision. We will have to determine with archives staff what would be the most acceptable search behavior.
The relationship between the MARC records and full EAD instances will also complicate further development. In principle the MARC collection record should be based on the EAD finding aid which would be the primary, most authoritative record for a collection. As mentioned earlier, the current workflow, however, operates in one direction from the OPAC and MARC. For the time being, the maintenance of authoritative data will likely be cumbersome. If we were to enable the capability, certain EAD files could take primacy, with revisions written to derived MARC records for inclusion in the OPAC. Meanwhile, descriptions of the many other collections lacking full EAD instances will continue to be maintained in MARC.
Replacing JavaScript with PHP
After we released the Archival Collections Portal, our central IT department provided us with space on their LAMP servers. Around the same time, Solr developers created a response writer that parsed PHP and serialized PHP. We now had PHP at our disposal, which we used for our next Solr projects. While the general steps to search and display Solr data are the same (send parameters to the Solr engine, and parse what comes back), the advantages of PHP over JavaScript are clear. First, response times are much, much faster: while it takes the same amount of time to fetch the data (assuming both data sets are equal), the power of server-side scripting allows more data to be written to the screen in significantly less time. Second, because parseJSON() and eval() are recursive, large sets of data cause severe browser lag times, and in some cases, outright browser crashes. In contrast, PHP’s curl functions and unserialize() (for serialized data sets) quickly retrieve and make sense of result sets. Solr developers recently released a PHP for Solr module that works well for PHP 5.2+.
Moreover, the nature of JavaScript with AJAX, in an educational setting, also causes problems. The browser’s “back” button does not work as expected in an AJAX application, because each followed link is really a function call on the same page rather than a page reload. This is an extraordinarily useful technique in many cases, but did not necessarily suit our overall purposes. As a result, we spent some development time ensuring unique, “bookmarkable” URLs existed in the Archival Collections Portal, not only as a feature but as a “best practices” for our institution. Accessibility compliance is also problematic, as on-the-fly redrawing of a screen and dynamically updated HTML pages do not render a page that is readable by JAWS or other screen-reading software. Screen readers will have no actual content to read when the page loads, for there is nothing on the page to be “read” until the response is written out client-side. This is a large barrier to implementation. Now that PHP is available on Columbia University servers, we will most likely rewrite this JavaScript application in our LAMP environment to provide better accessibility compliance and faster, easier searching.
Test exposure of data
One of our goals for the Archival Collections Portal was the creation of a site map, generated by Perl or XSLT, that was indexable by the major search engines (as well as Columbia’s own search engine). Once we created the Portal, we created a Google Sitemap for this application from one of the flat-file by-products of our Perl script. We also wanted to be sure these search engines received the most recent data. We chose to point Google to a file that receives continually updated information through our workflow. Because we had a readily-available data set to list, it was easy to make it conform to Google’s specifications and point its search engine to us. We now have a file that can be easily modified for harvest in other search engines too. This will allow us to expose our site to the greatest number of constituents and will become much more important as we fold in more finding aids and make that data searchable as well. As we create subject lists, we will be able to apply the same intelligence to series and subseries of the finding aids to create a robust, indexable list of data.
We have also begun experimenting with incorporating RDFa into the HTML collection pages. [9] The RDFa metadata would add some semantics to the otherwise generic HTML encoding. For example, the collection page for the Hart Crane Papers collection could contain code such as:
<div xmlns:dc="http://purl.org/dc/elements/1.1/"
style="padding:5px;"
about="http://www.columbia.edu/cu/libraries/inside/dev/archival/collections/ldpd_4079683">
<h2 property="dc:title">Hart Crane Papers ca.1909-1937.</h2>
...
<span property="dc:creator">Crane, Hart, 1899-1932.</span>...
This enables interoperability with RDFa aware applications. Interestingly, any attempts to have the RDFa enhanced collection pages to serve as GRDDL (Gleaning Resource Descriptions from Dialects of Languages) source documents proved difficult. For example, the W3C GRDDL service failed to extract the RDF from our pages. [10] The service will successfully process only well-formed XML. While the HTML code produced by the EAD to HTML transformation is well formed, the resulting pages reference server-side includes containing not well-formed XML. This highlights the benefits exposing well-formed XML, but also the naivete and fragility of the existing W3C service in having low tolerance for sloppy HTML code. This and any such application intended to operate on existing, “in the wild” HTML would do well to employ a tool such as the Tag Soup parser as a preprocessor to output well- from ill-formed HTML. [11]
The use of RDFa represents a “pull-based” approach to interoperability and exposure. Another is the addition of records to the CUL OAI repository, for which there are plans. We could also (although we have no firm plans to do this now) take “push” approaches as well. It would not be difficult to post descriptions and links on services like del.icio.us so that the collections could be discoverable in other environments and contexts.
Summary
As we developed the optimal setup, programming, and workflow techniques for our Libraries’ digital data, we realized to what extent the combination of Apache Tomcat, Solr, MARC, and XML led to a rapid development of stable, ready-to-use services. From the first indexing of our data, to the final interface prototype, our development took approximately six weeks. (This, of course, does not include front-end design tweaks, committee work, and final site launch.) Solr, in particular, generated the most time savings: sitting atop a search engine we knew well (Lucene), Solr allowed us to shift the mechanisms of search and retrieval to front-end user-interface development rather than back-end programming. Concepts such as highlights, facets, and even results lists did not have to be customized and interpreted through Java classes; basic changes did not require recompilation or reindexing. Thus we were able to separate layers of data, design, and development. We also found that our workflow “seeded” the development for other initiatives: retroconversion to full EAD finding aids, repository-specific XSLT libraries from MARCXML to MODS, and OAI harvesting are reusable in many other digital library projects.
Finally, for those interested in development and use of open-source programs in conjunction with robust library standards, we found that the combination of Solr, JSON, and MARC, residing in an Apache Tomcat environment, proved robust, scalable, inexpensive, and quick. While there are many libraries beginning — or fully implementing — initiatives to use MARC, XML, and Solr with their OPACs and data sets, we believe that these tools are extraordinarily helpful in the digital library realm as well. Together, we have found that they create a useful platform upon which to build many individual projects.
Appendix A: Mapping between MARC, EAD, and Lucene index
This table outlines how MARC fields were mapped to EAD elements and ultimately to fields in the Lucene index. Some of the fields are not indexed.
| MARC Field | EAD | Lucene Fields |
|---|---|---|
| 008/07-10 | unitdate@normal | chars 1-4: beginDate; chars 5-8: endDate |
| 100 | origination/persname | origination |
| 110 | origination/corpname | origination |
| 130 | origination/title | origination |
| 245$a$k | unittitle | unittitle |
| 245$f | unitdate | unidate |
| 300 | physdesc/extent | |
| 852 | repository | |
| 041 | langmaterial/language | |
| 001 | unitid@type=”clio” | id |
| 090 | unitid@type=”call_num” | |
| * | unitid@repositorycode | repository_code |
| 520 | scopecontent | scopecontent |
| 545 | bioghist | bioghist |
| 351 | arrangement | |
| 600 | controlacess/persname | persname |
| 610 | controlacess/corpname | corpname |
| 630 | controlacess/title | tit |
| 650 | controlacess/subject | subject |
| 651 | controlacess/geogname | geogname |
| 655 | controlacess/genreform | genreform |
| 656 | controlacess/occupation | |
| 657 | controlacess/function | |
| 700 | controlacess/persname | persname |
| 710 | controlacess/corpname | corpname |
| 730 | controlacess/title | |
| 506 | accessrestrict | |
| 524 | prefercite | |
| 530 | altformavail | |
| 540 | userestrict | |
| 541 | acqinfo | |
| 544 | relatedmaterial | |
| 555 | otherfindaid | |
| 561 | custodhist | |
| 856 | dao | |
| * | eadid | filename |
Links
[1] Lucene – http://lucene.apache.org/
[2] Solr – http://lucene.apache.org/solr/
[3] Exhibit – http://simile.mit.edu/exhibit/
[4] DACS (Describing Archives: A Content Standard) – http://www.archivists.org/catalog/pubDetail.asp?objectID=1279
[5] Sample collections page – http://www.columbia.edu/cu/lweb/archival/collections/ldpd_4079136/
[6] Full JSON result object – http://app.cul.columbia.edu:8080/findingaids/
select?q=railroads AND repository_code:nnc-*;origination asc,sort_title
asc&wt=json&indent=true&facet=true&facet.field=subject&facet.field=
repository_code&facet.field=persname&fl.audience=external&facet.mincount=
1&hl=true&hl.fl=all_text&hl.fragsize=50&hl.snippets=5&hl.formatter=simple&
hl.simple.pre=%3Cspan class=highlight%3E&hl.simple.post=%3C/span%3E&rows=20
[7] parseJSON() function – http://www.json.org/js.html
[8] Example search – http://app.cul.columbia.edu:8080/findingaids/results.html?
q=railroads AND repository_code:nnc-*;origination asc,sort_title asc&wt=json&indent=true&facet=true&facet.field=subject&facet.field=
repository_code&facet.field=persname&fl.audience=external&facet.mincount=
1&hl=true&hl.fl=all_text&hl.fragsize=50&hl.snippets=5&hl.formatter=simple&
hl.simple.pre=%3Cspan class=highlight%3E&hl.simple.post=%3C/span%3E&rows=20
[9] RDFa – http://www.w3.org/TR/xhtml-rdfa-primer/
[10] GRDDL – http://www.w3.org/2007/08/grddl/
[11] Tag Soup parser – http://home.ccil.org/~cowan/XML/tagsoup/
About the Authors
Terry Catapano (thc4@columbia.edu) is a librarian in Columbia University Libraries' Digital Program Division.
Joanna DiPasquale (jd2481@columbia.edu) is a web developer in Columbia University's Libraries Digital Program Division.
Stuart Marquis (marquis@columbia.edu) is a programmer in Columbia University's Libraries Digital Program Division.

Subscribe to comments: For this article | For all articles
Leave a Reply