*Note from the editor: The author has invited representatives from the reviewed products to provide comments on the article. These comments have been attached as the first comments of the publication.
Background and Goals
At Johns Hopkins Libraries, we decided to explore the creation of an improved, more integrated article search experience for our users. The motivation for this work was driven by negative user feedback from our current offerings, staff observation, and reports by other academic libraries investigating patron article search behavior and preferences.
We naturally considered the relatively new generation “discovery” products in the library market, such as SerialSolutions Summon, Ex Libris Primo, EBSCO Discovery Service (EDS), and (to some extent) OCLC WorldCat Local. All of these products include their own extensive index of articles and scholarly citations, as well as being marketed as a potential public catalog interface (with integrated article search). But rather than assume a complete replacement of our catalog discovery with such a product we considered the approach taken by some of our peer institutions using custom designed software that provided catalog search and article search in separate sections of the result page, a layout that’s been called “bento style” (for its visual resemblance to Japanese bento lunchboxes) by library technologist Tito Sierra. Examples include:
We decided that a bento-style search was worth serious consideration: leaving catalog search powered by our existing infrastructure, but adding an article search section powered by a yet-to-be-determined third party service. Additional details about the reasoning and evidence that led to this direction of pursuit, including local evidence and citations to findings from other peer institutions, can be found in a position paper on the author’s blog [1].
The question arose as to how to evaluate available third-party services that might be used to power an integrated ‘article search’ feature. Focusing on article search presented in a bento-style interface, we also realized that some traditional Abstracting & Indexing services might also be worth considering, in addition to more recently introduced ‘discovery’ products.
We wanted to find a way to apply a user-centered empirical investigation to this evaluation. I realized that the same capabilities that would allow one to embed an article search in a local applications bento-style interface (essentially, a sufficiently powerful API), would also allow us to create a ‘blinded’ survey instrument, where we displayed results from two different searches and asked the participating users to tell us which they liked better [2].
We decided to pursue this idea utilizing a blinded survey instrument to evaluate the users’ perceptions of results from different services. An additional benefit of this approach is that the implementation of the blinded survey instrument required a developer to use the same techniques that would be used in implementing the potential final product. Therefore, this approach allowed for review of the quality and capabilities of the various product APIs, and also served as a ‘proof of concept’ of the ‘bento style’ approach with each product, developing some software building blocks that could be re-used for implementation of a final product. These advantages helped motivate our course of action.
Others before us have done article search or discovery product comparisons where users were given pre-selected research questions, and/or results were evaluated for quality by librarians [3]. We wanted to try instead letting the users bring their own research questions and queries, and evaluate for themselves which tool they preferred. We thought this might allow us to find out the actual preferences of users for their actual needs (something we were interested in), without having to figure out for ourselves if we had the right ‘typical’ research questions, or if we evaluated results the same way our patrons did. This was our goal and motivation; we had somewhat mixed success.
Products included in Study
In order to be included in our blinded study, a product needed to have a sufficient API for the blinded instrument, which are essentially the same API features required for a ‘bento style’ implementation.
While we decided for purposes of the study instrument not to include links from articles to full text, a production implementation would need a way to link to full text and/or to a local link resolver. We decided to only include services in our evaluation that could support such linking.
Products included in evaluation:
- EBSCO Discovery Service (evaluation access)
- EBSCOhost ‘Traditional’ API (http://support.epnet.com/eit/ws.php) with existing licensed EBSCO databases (usable with our existing licenses) (set up to search approx 55 of our most used EBSCO databases)
- Ex Libris Primo (evaluation access)
- Serials Solutions Summon (evaluation access)
- Scopus (Elsevier) (usable with our existing licenses) (http://api.elsevier.com/content/search/#d0n17066)
Securing access to these products and their documentation — both ones we needed trial access to as well as products we already licensed — was a time-consuming process, and comprised a significant portion of the total calendar time to complete our evaluation.
Products initially considered but not included in the study due to lack of fitness:
- Google Scholar: The service has no API, and has terms of service that disallow screen-scraping; it can only be used in Google’s own native interface.
- Microsoft Academic Search: While it does have an API, the terms of service are prohibitive (including a requirement to include all links delivered by the API, in the order they are delivered, even if they lead to paywalls you do not license). Additionally, while the MS Academic Search product itself includes sufficient metadata for an OpenURL (as revealed, for instance, in the RIS export), the API response does not actually include this data with sufficient semantic granularity.
- Thomson Reuters Web of Knowledge: While the product did seem to have a sufficient API (for instance as used by our existing Metalib installation), and we believed our existing license ought to give us access to this API — we were unable to secure access/permission/documentation in time to include in the study, despite several months of attempts.
- Our existing Metalib-based, Xerxes-enhanced product, using its default/general search. We initially hoped to include this as a baseline/control, but writing the evaluation tool that could accommodate Metalib’s extreme slowness would have significantly increased the development time, and we ultimately decided that we did not need it.
The survey instrument
Users would enter a query and be presented with side-by-side ‘blinded’ results from two products chosen at random from the five services being studied. The participating user could choose which results they preferred, or select a neutral choice of “Can’t Decide/About the Same”.
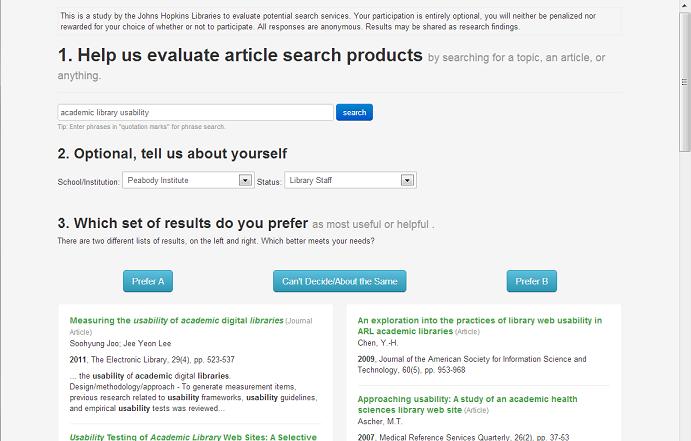
Technological Implementation
The survey instrument was implemented as two Ruby on Rails projects, both licensed open source.
The first, bento_search [4] is a general purpose abstract layer for querying third party search engines. It is designed to:
- Let you quickly implement search functionality in your own custom application, for any of its supported adapters;
- have a potentially shared implementation of working around the gotchas and undocumented features of certain search services; and
- let you switch out one service for another in an existing application with as little trouble as possible (to avoid lock-in).
bento_search currently supports adapters for the five evaluated services, plus adapters for Google Books, WorldCat and Google Site Search.
One of the motivations for undertaking this particular research was that the code required to write the survey instrument could largely be repurposed for an actual production application; the bento_search gem was designed from the start to support both use cases. It supports fielded search entry, pagination, and sorting in an abstract standardized way, but does not yet support multi-field/advanced search or facets/limits. bento_search also supports a standardized rendering/display of search results, across search providers — a necessity for the survey instrument.
The survey instrument itself is a Rails application called bento_battle, also available as open source. bento_battle, built with bento_search functionality, is only a few hundred lines of generously commented/whitespaced ruby.
We believe it’s important that the complete implementation of our experimental instrument is available, both so people can see exactly how the experiment was conducted, and so people can use our implementation to re-run the experiment, either identically or with changes, to investigate reproducibility of our findings.
The exact version of the bento_battle application used for the experiment is tagged at jhu-study-10Sep2012 [5]. Mid-way through the study, a new version was deployed with some bugfixes and enhanced reporting features, at jhu-study-17Sep2012 [6]. The nature of a ruby application using bundler means that the exact version of all gem dependencies, including the bento_search gem, is recorded and fixed in these tagged snapshots.
Per-product configuration and implementation choices
There are some inevitable choices to be made in both configuring how to search a given product, and implementing how the product will be searched and how results will be displayed. These choices could affect the experimental results, but need to be made anyway, in some cases to implement anything at all, and in other cases to try and show the products in their best light.
Display
Our standard template shows an abstract or other summary where available. If the product supported showing a query-in-context summary with highlighted search terms, this was used instead of a straight abstract. Summon supports a Google-style query-in-context snippet from full text, where available — this was used in display in preference over straight abstract. Primo and EDS both supply only abstracts, but do query term highlighting within the abstract — this capability was used in the survey instrument in these cases. All three products do query-term highlighting in the item title, and this too was used in the survey instrument’s output. EBSCOHost offered only a straight abstract, so this was used for EBSCOHost output. In all cases, abstracts/snippets were truncated to just the first few lines.
For purposes of the survey instrument and study, we decided not to provide any links from presented search results to full text or additional information, instead only presenting side by side results with no links to click on.
Search Input
In order to provide a standard query input syntax across all search products, the bento_search library discussed above supports a normalized standard input format across all products: Basically a simple ‘Google style’ input, that supports a simple list of terms and phrases (using double-quotes to indicate phrases). bento_search translates this to the most appropriate query the developer could determine for each product, to find results matching that list of terms and phrases with appropriate relevancy ranking.
For instance, in the case of EBSCOHost, bento_search translates the user’s input to an explicit boolean ‘AND’ expression; in the case of Summon, bento_search passes the user’s input through to Summon more or less unmodified.
The bento_search gem does not presently support standardized boolean operators or expressions.
Holdings Limiting — Not Used
The three ‘discovery’ tools (Primo, Summon, EDS) all have features were you can limit search results to ‘items held by your institution’ — sometimes this means electronic full text access, sometimes it includes print holdings. In order to do this, you of course need to communicate your holdings to the service in some way.
Configuring our holdings with each such product would have taken additional setup time, and introduced an additional point for mistakes to be made and inconsistencies introduced. We also weren’t certain whether we (or our users) would want the ultimate production tool we were considering to default to such a holdings limit, or to instead return unrestricted results.
Considering overall cost vs. benefit to run this study, we chose not to make use of any ‘limit to holdings’ in our tests — all searches were unlimited as to institutional holdings.
Authorized user
Some of these products produce different results depending on whether the end-user is currently authenticated as a member of the institution or not. Other products only allow results to be shown to authenticated users. As our test instrument authenticated users before allowing any access, all product API access was configured to assume an authenticated user.
Content Type Filtering
We noted that many peer institutions implementing a discovery service supply a default pre-set limit to exclude Newspaper Articles, or to focus exclusively on Journal Articles — they had found that non-scholarly content in the results was negatively impacting their quality and service.
This could have an even more devious effect on a study like this, if left uncontrolled. If users did prefer not to have newspaper articles in their result set, and rated one product poorly for including such results, when that product could have been configured to exclude them, this would be to some extent a misleading result.
Our choice not to limit to local holdings also resulted in many types of content being included in results that seemed of questionable utility (such as television transcripts and web page text), but which would have ended up excluded by a local holdings limit. I suspect several products have been optimized by their vendors for ‘limit to local holdings’ use. Adding some compensatory configuration to exclude these odd content types, where possible, seemed necessary to show each product at its best.
We also kept in mind that our original goal was to analyze these products for a basic, simple, article and scholarly citation search — not necessarily for use cases involving other types of content.
All these considerations led us to configure the searching for each product to try to exclude non-scholarly citations and focus on articles. Where possible, we chose not to limit only to ‘journal articles’, but instead to exclude certain product-specific categories that seemed to create ‘noise’ in the result set, as this generally seemed to produce optimal results.
While these configuration choices, specific to each product, were subjective and might influence study results, we still decided they were necessary to present each product at its best to study participants.
Exact configuration choices made can generally be deduced from the configuration file in the git repository for the test instrument.
EBSCOHost Traditional
The EBSCOHost ‘traditional’ API allows you to search from 1 to all of your existing licensed EBSCO databases simultaneously, returning a single merged result set. We license nearly 100 EBSCO databases (although some of them are strict subsets of others). Trying to search all of our databases at once through this API resulted in unacceptable performance.
We looked at our usage logs for EBSCO, and took the top-most used databases. We then adjusted the list a bit by hand to broaden disciplinary coverage as far as we could within our EBSCO licenses, and to remove databases focused on formats we weren’t interested in (image databases, or video databases). The ‘EBSCOHost traditional’ option was configured to search the resulting list of approximately 40 databases. The exact list of databases used can be seen in the git repository for the bento_battle instrument implementation code [7].
Promotion and Response
Our evaluation tool was open to users from September 10th 2012 until October 2nd. Login to our enterprise sign-in system was required to access the evaluation tool, in order to comply with all relevant contracts and agreements for included products.
Promotion was via:
- Links on library home pages inviting participation
- A link on our Metalib-based JHSearch results page, inviting participation — which would execute the user’s already entered query in the search instrument.
- A similar query-preserving link in the Johns Hopkins Welch Medical Library Multi-Search tool (also Metalib-based).
- A library blog post.
- Bulk email to librarians, who then re-publicized the study to their liaison departments. (Library staff was also welcome to participate in the study).
- At the Eisenhower library, placards were placed next to reference/information desk stations with the URL, for staff to participate in during any free time.
- Other JH Libraries may have publicized the tool to their patrons in various ways.
It was somewhat more challenging to attract participation than we expected. During the period the study was up, we received 414 total preference responses. This is not as large a sample as it might initially sound, as with 5 total products and 414 total responses, any given pairing of products (say Primo vs. Summon) were only matched on average 41 times each.
We don’t know how many unique people participated; for instance, 40 people doing 10 choices each, or 400 people doing one choice each. We also don’t know which participation events came from which promotion venue.
In addition to the 414 registered selections, there were another 214 occasions a user loaded the evaluation tool results page, but abandoned it without making any selection at all. So about 1/3rd of the time an evaluation page was displayed, it was abandoned without a selection.
Demographics
We had an optional area for participants to identify their affiliated Hopkins school/institution, and their role/status. As this was optional, many participants chose not to fill it in. In retrospect we still think making demographics optional was the right design choice, to maximize participation.
The plurality of responses did not self-report their demographic characteristics, and we decided that we lacked sufficient sample size in any of the demographic groups to justify reporting or comparing results between or within the individual groups.
Limitations
Any experimental design has limitations: both things not being studied and potential limitations in the validity of what is being studied. It is important to understand the limitations of our experimental design before we move on to looking at our findings.
- We only evaluated the article search function. Some of these products come with other functions or features that may be of use, but are not being evaluated here.
- Evaluation was limited to a basic, simple style of article search; a usage pattern where a user enters some search terms and looks at the first page of results. Our study did not include or evaluate advanced/fielded searching, faceting, looking past the first page of results, etc. Some products may do some of these things better than others. Our experimental design did not attempt to explore this.
- Our experimental design only reveals relative preferences. If two providers are pitted against each other 100 times, and one tool is selected as better 90 times — it’s quite possible that users considered both providers great, or considered both providers awful. We have no way to distinguish. Our experimental design only tells us they liked one better than the other, only a relative preference between the two.
- Our experimental design only measures consistency of relative preference, not strength. If two providers are pitted against each other 100 times, and one tool is selected as better 90 times, this means our participant population very consistently preferred that tool — it does not tell us if they thought it was a lot better, or just a tiny bit better. Our design reveals consistency of preference, not strength of preference.
- We do not know why participants preferred one tool to another, or if different participants had different reasons at different times. Although it would be nice to know more details about what users want in a search tool, answering this question was not a goal of this research.
A good experimental design tries to control as much as possible, and isolates a very specific phenomenon to be studied. We tried to do this, focusing on the usage pattern/style we were prioritizing: User preferences between products, for a basic, simple, article search functionality. And we wanted to discover which product, of products as they actually exist available to us now, our users would prefer. We tried to design an experiment to efficiently answer this question.
However, there are also some limitations to the validity of even what we tried to measure:
Participants, in the artificial environment of our experiment, may not express preferences that match what their real world preferences would be.
When I experimented with the evaluation tool, I found that if I just entered a hypothetical query, I really had no way to evaluate the results. I needed to enter a query that was an actual research question I had, where I actually wanted answers. Then I was able to know which set of results was better.
However, when observing others using the evaluation tool, I observed many entering just the sort of hypothetical sample queries that I think are hard to actually evaluate realistically. We tried to include links from existing tools to find articles, to capture participants in the middle of the research process with actual queries — but we did not track what portion of participation came via these avenues.
This issue does not apply to known-item searches, where either the item you are looking for is there at the top of the list, or it isn’t. Looking through the queries entered by participants, there seem to be very few ‘known item’ searches (known title/author), even though we know from user feedback that users want to do such searches. So the study may not adequately cover this use case.
Findings
In summary, the study, largely, did not show significant preferences between products. While this could be due to lack of sufficient sample size, there are reasons to think that is a valid result, at least under this experimental design. The rest of this section and the subsequent Interpretation section will explain how we arrived at this conclusion and what we think it means.
Our complete data set from is publically available at: http://jhir.library.jhu.edu/handle/1774.2/36246 . Others may want to analyze that data themselves, or check our findings against the actual dataset.
Somewhat Unruly Data Set
The experimental design resulted in a somewhat unruly data set. 414 total 1-vs-1 selections, with each selection being between two of five possible products. On average, each product was presented in a selection 166 times ( (414*2) / 5 ), but since options to present were chosen randomly, some products were presented slightly more and others less (from 155 times to 171 times). On average, any two products were presented as paired ‘competitors’ 41 times each. (If N=5 is the total number of options, and M=414 is the total number of presentations, this is ( M / (N-1)! )). However, random variation means that actually the number of presentations for each pairing ranged from 35 to 48.
You can see that even with 414 total preferences selected, we get relatively few preferences expressed for any given individual pairing: For instance, Summon was only matched against Primo 48 times, and of those 18 times “About the Same/Can’t Tell” was chosen, so a preference was only expressed 30 times. This ends up being a fairly modest sample size.
The one-sample Z test
To explain the statistical analysis method used, let’s quickly explore an analogy.
Let’s say you were taste-testing colas. Coke or Pepsi, we’re not telling you which is which, which do you like better? But let’s say you misled the participants, and it was really Coke in both glasses. If you gave 100 people this taste test, you would expect glass on the left (coke) to win about 50 times, and glass on the right (coke) to win about 50 times. Because they are the same. Of course, it might not be exactly 50/50, just as when you flip a fair coin 100 times you might not get exactly 50 heads, but it will usually be close, maybe 48/52 etc.
But let’s go back to an actual taste test, where one glass really is Coke and another Pepsi, and we don’t tell the participants which is which. Let’s say we have 100 participants, and 57 choose Coke and 43 choose Pepsi. How do we know if this is an actual expressed preference, or is this just random variation approaching 50/50?
One way is to use a one sample Z-test for proportions, with a null hypothesis of 0.5. If we use that test with an alpha value of .05 (less than 5% chance of happening through random variation), then in the particular example above we find that with a sample size of 100, 57/43 is not in fact a statistically significant difference from the 50/50 null hypothesis.
We can apply exactly this test to each individual pairing in our results, say all the times Summon was presented against Primo and a selection was made, to see if the preferences differ significantly from a 50/50 no preference.
But what do we do with the “Can’t Decide/About the Same” choices? I decided that they give us no information about preferences between two products, they are essentially an ‘abstention’ in helping us determine user preferences, and should not be counted.
For overall rankings, we can look at all the times a given product, say Summon, was included in the choices and a selection was made, across all the different products it could be paired with, and look at overall what Summon’s ‘victory rate’ is (proportion of times it was chosen). We can use the one-sample z-test again to determine if its victory rate differs significantly from the 50/50 null hypothesis of no preference.
We did not come up with any way to actually test overall comparisons between products — only an overall score for each product differing significantly (or not) from 50%, and each individual pairing.
I am fairly inexperienced at statistical quantitative analysis (as are library technology departments in general, I think). Although I am happy with our approach here, there may be a better way to analyze these results; if a reader knows of one, please do share.
Okay, the Actual Findings
Overall
Please note again that few of these numbers were statistically significant.
|
engine |
num participating |
wins |
losses |
ties |
Victory rate |
| summon | 168 | 76 | 54 | 38 | 58% |
| ebscohost | 165 | 64 | 51 | 50 | 56% |
| eds | 155 | 58 | 52 | 45 | 53% |
| primo | 169 | 62 | 66 | 41 | 48% |
| scopus | 171 | 51 | 88 | 32 | 37% **(significant)** |
Each row was analyzed with a one-sample z-test, alpha of 0.05, null hypothesis of 0.50 — ties were excluded as giving no information on preferences, the ‘victory’ rate is just wins / (wins + losses).
Only Scopus differs significantly from the 50/50 no preference (with Scopus being less preferred compared to alternatives). All the other rows are essentially statistically non-distinguishable from a straight 50/50. (**Summon does get close** to being significantly different than 50/50 in the positive direction; if one more Summon choice had been received, and no more anti-Summon choices, it would have crossed into statistical significance).
In order to look more deeply, we have to look at individual pairings: Okay, Scopus is significantly unliked in general, but in particular is it less preferred than some alternatives, while no less preferred (or even more preferred) than others?
Individual pairings
We can look at a cross-tabulation of each individual possible pairing. Summon vs. Primo, Summon vs. Scopus, etc. And we can analyze each pairing for statistical significance using the one-sample z-test again.
| vs. | eds | scopus | ebscohost |
|---|---|---|---|
| eds | * | total:44tie:10scopus win: 11eds win: 23scopus:0.32 significant | total:38tie:20ebscohost win: 13eds win: 5ebscohost:0.72 |
| scopus | total:44tie:10eds win: 23scopus win: 11eds:0.68 significant | * | total:43tie:12ebscohost win: 17scopus win: 14ebscohost:0.55 |
| ebscohost | total:38tie:20eds win: 5ebscohost win: 13eds:0.28 | total:43tie:12scopus win: 14ebscohost win: 17scopus:0.45 | * |
| primo | total:38tie:8eds win: 16primo win: 14eds:0.53 | total:40tie:6scopus win: 13primo win: 21scopus:0.38 | total:43tie:9ebscohost win: 20primo win: 14ebscohost:0.59 |
| summon | total:35tie:7eds win: 14summon win: 14eds:0.50 | total:44tie:4scopus win: 13summon win: 27scopus:0.33 significant | total:41tie:9ebscohost win: 14summon win: 18ebscohost:0.44 |
| vs. | primo | summon |
|---|---|---|
| eds | total:38tie:8primo win: 14eds win: 16primo:0.47 | total:35tie:7summon win: 14eds win: 14summon:0.50 |
| scopus | total:40tie:6primo win: 21scopus win: 13primo:0.62 | total:44tie:4summon win: 27scopus win: 13summon:0.68 significant |
| ebscohost | total:43tie:9primo win: 14ebscohost win: 20primo:0.41 | total:41tie:9summon win: 18ebscohost win: 14summon:0.56 |
| primo | * | total:48tie:18summon win: 17primo win: 13summon:0.57 |
| summon | total:48tie:18primo win: 13summon win: 17primo:0.43 | * |
While 414 total responses may seem like a healthy number, it results in a very small sample size for each pairing. For example, Summon was matched up against Primo only 48 times in which the user made a selection. Of those 48 times, Summon was chosen 17 times, Primo 13 times, and 18 ties (“Can’t Decide/About the Same”).
We want to know if choices in an individual pairing represent a significant indication of preference, or just random variation; we again use the one-sample Z test with an alpha of 0.05, calculated for each pairing, with .5 as the null-hypothesis (no preference), and considering only active selections. Using this analysis, the only pairings that achieve statistical significance are:
- A preference for EDS over Scopus
- A preference for Summon over Scopus
That is, the only statistically significant preferences we detected both overall and in individual pairings were a negative preference against Scopus.
Interpretation
One obvious question is whether we have a finding of no user preference of our users, collectively, thinking all the products are about equal, or if our findings are simply inconclusive. I suspect the answer is a bit complex. While small sample size made it hard to show statistical significance in some cases, I suspect a larger sample size would still have the products clustering fairly tightly. As our experiment progressed with more responses submitted, the rankings became closer to each other. The significant number of “ties” in every pair-up (generally from 25%-33% of selections) gives us another reason to suspect that indeed different products perform ‘about the same’.
I think there’s a larger issue though with the nature of the experiment. If used over time in production, some products may very well satisfy users better than others — but when asked to express a preference for a small handful of searches in the artificial context of the experiment, users may not have the capability to adequately judge which products may be more helpful in actual use. I think this is quite possible, especially if users were not using their own current real research questions to test.
Some users, especially beginner/undergraduate users, may simply be unconcerned with relevance of results, being satisfied by nearly any list of results. In a survey-based study receiving 523 responses at a ‘mid-sized Midwestern university’, James P. Purdy [8] reports:
“Only six students explicitly identified relevance as a reason a research resource was their favorite. In other words, only six students favored a resource for its ability to return sources relevant for their topic and/or assignment… That students valued quality over relevance indicates students may define research as meeting particular task criteria, rather than generating knowledge. For example, they may see good research as referencing five scholarly sources rather than conversing with topically relevant sources.”
If the findings in the Purdy study are generalizable, what this means for library practice is still unclear — does that mean that the relevance/topical quality of results does not matter for our users and we need to pay no attention to it either? Or does it mean that to maximize quality for our patrons, we need to care about factors that our users themselves don’t, and can not rely on user’s own evaluations to guide us?
Librarians might possibly be more expert/capable at choosing the right queries to search and judging based on a few sample searches — unfortunately, with only 64 preference selections from self-identified ‘Library Staff’, we don’t think we have a large enough sample to look at the preferences of that demographic on their own.
Despite these limitations, we can imagine there could surely be a product so bad that it would have had a significant negative preference. For an extreme example, we can imagine creating a ‘product’ which simply returned random citations from a list, unrelated to the query. Surely that would have performed poorly even in this experiment. In retrospect, it would in fact have been useful to include such a ‘service’ in the study as a control.
That few significant preferences were demonstrated in this study, can, I think be taken as at least some evidence that all products tested (with the possible exception of Scopus) perform ‘well enough’ for supporting basic search usage scenarios across our population served.
Individual pairings
While few of the individual pairing results rose to the level of statistical significance, possibly in part due to small sample size in each individual pairing, it is worth looking at them for trends suggestive of further research and possibly valid tendencies not captured with statistical significance.
- Scopus ‘lost’ to every other product it was paired with — and produces the only statistically significant pairings, losing to both EDS and Summon with statistical significance.
- EBSCO ‘traditional’ api, the other ‘traditional’ (rather than ‘next generation discovery’) product, does surprisingly well, holding its own — winning (although by a slight and not statistically significant amount) when matched with every other product included!
The three ‘discovery’ products are fairly tightly clustered, although there are some trends.
- Primo lost to every product it was paired with, although by fairly small not statistically significant margins.
- Summon won, but by a small and not statistically significant margin, against every product it was matched against — except EDS, where it was an exact tie (14 vs. 14 with 7 ties).
- EDS has very mixed success — it beats Scopus with statistical significance, but Primo only by a very slim non-significant margin (16 to 14 with 8 ties); ties with Summon; and is beat by EBSCO ‘traditional’.
What criteria do participants use to judge?
The study gives us no direct evidence of what criteria any individual participant made in selecting a preference. We can categorize hypothetical criteria for preferences into two groups:
- Differences in items in result sets, due to different corpuses or different ‘relevance’ ranking algorithms across products.
- Differences in presentation that could not be normalized out in implementation — primarily presence or absence of abstracts and query-in-context highlighting, and in the case of EDS in formatting of citation details.
Valentina Artemieva at the Montgomery County Campus of Sheridan Libraries (Johns Hopkins Libraries) did in-person observed run-throughs of the experiment with 5 separate students (4 grad students, one undergrad). She specifically asked them to tell her why they chose the preference they did — all five independently said that they decided based on preferring results with ‘more information’, such as including abstracts. We don’t know for sure if this is representative — but it could indicate that, at least for students, just about any set of reasonable results are ‘good enough’, and they focus on presentational issues.
To the extent completeness of presentational context was valued, it could explain why Scopus did poorly. Scopus is the only product which had no abstracts at all available. (Scopus as a service certainly has abstracts, but their API does not provide them, and their terms of service for federated search in fact prohibit presenting them). It’s possible this harmed Scopus in participant preferences, although I think it’s probably also true that actual items in result sets were a factor as well:
EBSCO ‘traditional’ API, while it does provide abstracts, is the only other product in addition to Scopus that lacked ‘query in context’ bolded highlighting of search terms. Interestingly, this does not seem to have harmed EBSCO ‘traditional’ in participant preferences.
Comparing EBSCO ‘traditional’ and EDS is particularly interesting, as they are from the same vendor. EBSCO traditional is essentially a subset of the EDS corpus — EDS searches everything our EBSCO traditional API setup does, and more. They probably use similar ‘relevance’ rankings.
One would expect EDS to do substantially better than EBSCO traditional, being a newer product, with many enhancements and more coverage, from the same vendor. Yet, this did not happen. EBSCO ‘traditional’ in fact was preferred substantially more than EDS — 13 to 5, not a statistically significant level in part due to small sample size, but striking nonetheless. This pairing of two products from the same vendor, perhaps unsurprisingly, also had a higher number of ‘ties’ (20, 52% of all selected preferences!) than any other pairing.
EDS does offer a version of query-in-context highlighting, while EBSCOHost ‘traditional’ offers only abstracts; EDS was not preferred over EBSCOHost despite this. EDS is also theonly product that does give us sufficient granularity in the API response allow us to format citation presentation in a standard way; it’s possible users reacted negatively there. It’s also possible the smaller coverage of EBSCOHost ‘traditional’ was actually to its advantage in this test – it’s a smaller corpus, but also a more focused one, perhaps giving better results for topic searches. If our participants had been searching for known-item titles (they largely were not), the smaller corpus may have been more detrimental.
Speed of response between products
The deployment of the study gave us a rare opportunity to compare the speed of response of the various products, side by side. The bento_battle blinded survey instrument was written to record the duration it took to retrieve and prepare the responses for each query. This measurement is of total end-to-end time, including software parsing and normalization of the response — however, spot checks suggest that the time waiting on HTTP responses from third party service is the great majority of total time elapsed. It should be kept in mind that these results could vary at different network locations, with different software implementations, or as the various products under testing continue to evolve. However, it still seems useful to share our findings with those caveats, as any head-to-head speed of response comparison would be otherwise very difficult to come by for interested potential customers.
Over the month the study ran, every time a query was made to a third party service, the elapsed time to retrieve and prepare results was recorded. There are more timing results recorded for a given product than actual user preference selections involving that product, because some portion of participants chose to abandon the task after doing a search but before selecting a preference.
|
product |
count |
mean |
median |
90th percentile |
95th percentile |
max slowest |
| ebscohost | 265 | 2658 | 2388 | 3983 | 5273 | 33118 |
| eds | 252 | 3738 | 2826 | 5899 | 8418 | 27719 |
| primo | 277 | 2356 | 1611 | 4545 | 5878 | 16280 |
| scopus | 261 | 961 | 939 | 1340 | 1474 | 3123 |
| summon | 261 | 961 | 670 | 1853 | 2384 | 7465 |
Response time descriptive statistics, by product, in milliseconds
Of the ‘discovery’ solutions, Summon was definitely the fastest with a median response time under one second — and consistently fast. Even its 95th percentile slowest response was still a fairly reasonable 2.3 seconds. Summon, like all the products, did exhibit some extremely slow responses (possibly due to network hiccups, or cold caches on the vendor’s side), but not very many and even its slowest response was faster than other products’ slowest responses.
EDS was by far the slowest of the ‘discovery’ solutions, and while its median response time was a barely acceptable 2.8s, it had some really pathologically terrible response times in 90th percentile and slower (10% of all responses!). This is likely due to the cumbersome and multi-step authentication process required by the EDS API. In even the typical query, two HTTP requests were required to EDS (one to get a session token, one to actually execute the query), and in the worst case four http requests are required. EDS’s cumbersome and slow authentication process is discussed below in the API Review section.
Primo performed somewhere in between Summon and EDS.
Of the non-discovery solutions, Scopus’s response time was comparable to Summons, while EBSCOHost traditional API’s performance will vary based on the number of EBSCO databases you choose to query. However with the set of around 40 we chose to include, EBSCOHost traditional was surprisingly slightly faster than EDS, perhaps because it did not require the multi-layered authentication process.
Further research directions?
All code used to do this experiment is open source and designed to be easily re-usable. Others could do repeat experiment to validate or reproduce; or repeat with changed configuration to see if that changes the results.
Although I’m interested in how configuration and limiting choices may have changed our results, I suspect a trial done much like this one — with 5 or more products compared — would probably still result in no significant preferences detected. It might be more useful to limit the options considered to only two products, to increase the sample size of that single pairing with the same overall participation.
Alternately, it might be useful to do a comparison only with librarians participating — it may be that patrons are just not able to predict their actual long-term preferences or benefits from an artificial experiment like this. As an example of a comparison using only subject-specialist librarians, see Bietila and Olson, “Designing an Evaluation Process for Resource Discovery Tools” in Planning and Implementing Resource Discovery Tools in Academic Libraries, IGI Global 2012. Or the slides from a NISO presentation by Bietila, available open access at: http://www.niso.org/news/events/2012/nisowebinars/discovery_and_delivery/
If there were a way to creatively design the study to be more confident you were eliciting more realistic queries for actual real world research questions and research needs (including known-item searches), it would produce results one could be more confident in. It’s not entirely clear how to do this, although making existing search tool results pages the exclusive entry point to a study instrument might be beneficial.
Whether focusing on subject experts or not, whether in an experiment similar to this one or not, libraries will continue to have a need to evaluate and compare discovery and article search products. And often, especially if a product’s API’s will be used to create a local UI, it will be beneficial to focus on search results rather than presentation — to compare in a normalized presentation (whether blinded or not), rather than using vendors’ native interfaces with very different UI’s. The bento_search rails gem is intended to be useful in allowing rapid development of testing or prototyping environments for such examinations.
Another option possible with the bento_search tool would be deploying multiple products in an actual production application, using an “A/B Testing” approach to give provide different users with different search products, and tracking analytics to try and determine which product seemed more useful (say, which product resulted in more clicks on results).
One could also imagine this preference comparison approach (or an A/B approach) being useful to test multiple configuration options for a single tool one already has licensed access to.
One of the biggest barriers to do any kind of comparison between products is the difficulty of getting access to evaluate a product. Libraries are increasingly, and rightfully, attempting to gather more evidence before making major decisions (such as purchasing an expensive ‘discovery’ product). Ideally, vendors would make it quicker and easier for libraries to get evaluation access in order to do this.
Conclusion
Many of us working with library technology would like to incorporate more user-centered assessment into our planning and decision-making process, including quantatitive investigations where appropriate. One barrier that can keep us from undertaking such investigations is how overwhelming it can be to “get it right”, and our worry that it’s not worth doing unless it’s done perfectly with absolutely minimized limitations.
I do think it’s important to spend some time understanding the limitations of any research we do (and any research has limitations). But I think it’s better to do more assessment even with limitations, than to do minimal assessment out of desire to only do perfect assessment. If you are aware of the limitations of your conclusions, than almost any assessment can give you some additional information to make better decisions than you would have without it. Any time you incorporate assessment into your planning, you gain experience to do it better (and more efficiently) next time.
On those grounds, I consider our research here to be a success. We made a foray into incorporating user-centered assessment into our planning, becoming more comfortable with that process and increasing our experience and ability to do it. We believe this research has been valuable despite its limitations, and that additional time spent perfecting the research design would not have had a proportional benefit to our findings.
The way this research project allowed us to become familiar with the various projects being investigated–both on a technical and a functional level–was also invaluable in helping us to be more comfortable in our decision-making involving some potentially expensive purchases and projects. The technical implementation aspects of the study were intentionally designed to serve as a proof-of-concept of one possible production implementation path, and an opportunity for technical review of the various products. I consider this aspect of this project a complete success, and will definitely try to find opportunities in the future to efficiently undertake that kind of evaluation as part of planning processes. I think it’s absolutely vital to get full evaluation/trial access to expensive products being considered for licensing, and to find ways to take advantage of that trial access for in-depth technical evaluation, not just a quick surface-level perusal.
The actual conclusions we were able to make from the quantitative empirical portion of the study are limited, with few statistically significant differences between products demonstrated. In the absence of such demonstrated preferences, we think there is some reason to believe that end-user’s own preferences with regard to core search functionality truly will not significantly differ between these products, and we can focus mainly on other factors in our decision-making.
We are considering moving ahead with an initial deployment based on a product we can use with our already existing licenses, such as the EBSCOHost ‘traditional’ API. Our ability to quickly pivot to another article search results provider increases our confidence in this approach. The ‘bento style’ interface choice is part of what makes this kind of switch-out feasible, especially powered by the ‘bento_search’ ruby gem which aims to support this kind of switch-out. We will try to set expectations at the start of implementation to allow for such a quick switch-out, based on librarian and user response to the initial implementation in real-world practice. Our initial implementation plan will include the commitment to do more assessment of how well the service is working within several months of initial roll out.
Appendixes
Notes
[1] http://bibwild.wordpress.com/2012/10/02/article-search-improvement-strategy/
[2] Only after our study was well underway did we notice that Microsoft is promoting a very similarly designed side-by-side comparison for Bing marketing purposes: http://www.bingiton.com .
[3] For example: Asher, Duke, and Wilson. “Paths of Discovery: Comparing the Search effectiveness of EBSCO Discovery Service, Summon, Google Scholar, and Conventional Library Resources”. Forthcoming in College & Research Libraries, Anticipated Publication Date: July 2013, online pre-print available now: http://crl.acrl.org/content/early/2012/05/07/crl-374.short.
[4] http://github.com/jrochkind/bento_search
[5] https://github.com/jrochkind/bento_battle/tree/jhu-study-10Sep2012
[6] https://github.com/jrochkind/bento_battle/tree/jhu-study-17Sep2012
[7] https://github.com/jrochkind/bento_battle/blob/jhu-study-10Sep2012/config/ebsco_dbs.rb
[8] James P. Purdy. “Why first-year college students select online research resources as their favorite”. First Monday 17(9). http://www.firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/4088/3289)
Disclosure
Participating vendors were given the opportunity to review a pre-print draft of this article and provide feedback to the author. Additionally, vendors were invited to submit public comments on the article.
About the Author
Jonathan Rochkind is a software engineer at Johns Hopkins libraries, focusing on the libraries’ user-facing web presence. He blogs professionally at http://bibwild.wordpress.com. Library-focused open source projects in which he is a committer and has made significant contributions include Umlaut, Blacklight, and Xerxes. He can be reached at rochkind at jhu edu.
Acknowledgements
Thanks to the various vendors who gave us trial access where needed, and technical support in all cases, to include their products in our evaluation.
Thanks to David Kennedy, Head of Systems, and Deborah Slingluff, Associate Director for Library Services and Collections, both at Johns Hopkins Milton S. Eisenhower Library, for recognizing the value of this study to our organization, and supporting its undertaking.
Thanks to our local Article Search Study Committee for advising on study design and helping to market and promote the study. All mistakes are mine, however.
Developer Review of Products
Developers in the library sector know that library market vendor API quality can vary. Often an API may look acceptable for desired use cases from the marketing, documentation, or even an initial look at a live demo. But sometimes, when developing for actual use cases, you can discover that an API is buggy, difficult to work with, or functionally incapable of achieving your aims.
The implementation of the blinded survey instrument required development of code against the products’ APIs, and provided the opportunity to review those APIs for developer ease of use and functionality. The ‘proof of concept’ against the actual API’s was perhaps equally as valuable as the study itself.
As few developers have the opportunity to compare these APIs side by side, sharing what we’ve learned seems a valuable service. However, it should be noted that this review is one developer’s subjective opinion based on his perspectives and concerns and the information available to him.
One common thread among all products was the lack of documentation of the quality and completeness a developer would want. Most products offered some level of documentation, but most were incomplete, leaving out important details related to error responses, input formats, or content limitations.
Also, in general the ‘discovery’ products all offer some form of “limit to my libraries holdings” and “limit to items available in online full text”, but this aspect was not explored. The traditional A&I products (Scopus and EBSCOHost ‘traditional’) do not offer such features. The discovery products also, unlike the traditional A&I products, typically offer a did-you-mean/spellcheck feature, but I did not investigate the quality or ease of development use for this feature in any products.
EBSCOHost Traditional
This is not a discovery layer and lacks ‘discovery’ features, but the API is actually quite reasonable and easy to work with for what it is, as well as reasonably well documented.
In using EBSCO ‘traditional’ API, you are cross-searching a variety of EBSCO databases licensed to you. Different EBSCO databases can use different controlled vocabularies for such values as format, and metadata completeness may vary between databases.
With APIs that come bundled with licenses mostly used for native HTML app access, there can sometimes be a worry that the API is an afterthought not fully supported — especially for ‘last generation’ products like EBSCOHost (rather than EDS). However, the EBSCO ‘traditional’ API seems fairly mature, and basic questions on the API through EBSCO’s usual support mechanisms were generally answered satisfactorily.
Notable Features
- For records where it’s available, you can ask for complete fulltext as HTML in the response. This is a fairly unique feature, although I do not have concrete uses for it in mind.
- Peer-review limit is available, although not all databases may record this info.
- While extremely limiting ‘facet’-like functionality is available from the “GetCluster” API call, when cross-searching multiple databases, the facets are limited, and in all cases they don’t actually have facet counts. The API faceting functionality is not equivalent to that of the native interface.
- There is sufficiently granular citation metadata to create an OpenURL or export a citation, and it’s rare that a record is missing proper data for these purposes.
- API response does clearly indicate if full text is available for a particular record on the EBSCO platform for your institution’s licensed entitlements (and whether it is in PDF or just full text), and provides a link to pass the user on to the EBSCO platform record-level page. (Links directly to PDF take an additional per-record API call to retrieve, which is inconvenient.)
- Abstracts are included.
Limitations or Issues
- Licensed databases are not automatically available for searching through the API. Rather, one needs to explicitly configure each database for inclusion in your EBSCOHost API profile.
- If a database formerly available becomes unavailable (due to licensing or platform changes), and your API requests still ask to search it — it’s a fatal error and no response is returned, even from remaining available databases.
- The fact that you are cross-searching multiple databases can lead to some data normalization issues since Content Types are not particularly consistent across databases.
- The query syntax is poorly documented. < is not the same as <>. Some changes to query parsing may be available by asking EBSCO support to enable a different mode on your profile, but not by a self-editable field in the admin interface. Some kinds of query syntax errors (such as “a and b”) can result in a zero hit response, without an error message.
- While there is a language tag in output, it seems to quite frequently be empty or improperly set to “English” even for non-English articles.
- Relevancy ranking is decent, but can sometimes be slightly odd. A single phrase-quoted search on a title can result in the article matching that title exactly being number 2 or 3 on the result list instead of 1.
- Unlike the ‘discovery’ products, there is no “query in context” search term highlighting whatsoever.
API Authentication
- Account/password passed in ordinary URL query parameter.
End-user authentication
As an ordinarily A&I type database, we assume we are not allowed to show results except to end-users that have been authenticated as affiliated with our institution.
Documentation
There actually is a fair amount of documentation on the public web, although it’s scattered in several places and can be hard to locate. EBSCO also maintains an extensive support knowledge base that includes entries on API issues as well.
As is typical for all these products, response formats are mostly undocumented and need to be reverse-engineered, but a DTD is provided for the XML response (http://support.ebsco.com/eit/docs/DTD_EIT_WS_searchResponse.zip), which is better than nothing, although insufficient at documenting semantics.
Some notably useful pages:
- http://support.ebsco.com/eit/ws.php
- http://support.ebsco.com/eit/ws_faq.php
- http://support.ebsco.com/eit/ws_howto_queries.php
- http://support.epnet.com/knowledge_base/search.php?keyword=&interface_id=1082&document_type=&page_function=search
- http://eit.ebscohost.com/Pages/MethodDescription.aspx?service=/Services/SearchService.asmx&method=Search
- http://support.epnet.com/knowledge_base/detail.php?id=5397
EDS
The EDS API presented a number of challenges, chief of which was dealing with authentication. While EDS is provided by the same vendor as the older more basic EBSCOHost ‘traditional’ API, EDS was in many ways more challenging to work with than EBSCOHost. The EDS API does offer some of the ‘discovery’ functions missing from EBSCOHost traditional API, but it lacks the granular citation metadata found in the EBSCOHost Traditional API product.
Notable features
- There is a sophisticated query syntax that should support fielded search and complex boolean expressions. While it’s not clear if it’s suitable for exposing directly to the end-user, it’s reasonably okay to work with in software.
- There are several different ‘modes’ of query parsing which you can select via API. It’s somewhat confusing what the differences are and which you might want.
- There is a convenient multi-parameter query style that would be useful for sending multi-field queries entered by users in separate text boxes.
- A ‘peer reviewed’ limit is available.
- There is a query-in-context highlighting function, but it’s very cumbersome to use, and only applies to certain metadata fields (Google-style fulltext snippets not available).
- Faceting is available, including on content type and langauge, but I did not investigate this extensively.
Limitations or Issues
- See API authentication section below, there are some significant challenges.
- The citation metadata (journal name, volume, issue etc) are offered only in a single text field meant to be displayed directly to the user. There are no granular metadata elements allowing OpenURL generation or citation export, though you can configure the API to provide a pre-configured OpenURL in the response.
Oddly, this single text field provided in API response isn’t an end-user presentable literal string, but includes undocumented XML-like tags which must be stripped before presentation to end users.
- This single text field of citation information is missing from some items, even when the underlying platform is able to provide an accurate OpenURL for the item.
- Other data elements that are available for facets or limits are not available in the API response for an individual element. A notable example would be the language of the article. The per-record API response is very limited.
- Data tends to be HTML, with presentational HTML tags like <b> and <i> as well as HTML character entitles. But this is somewhat inconsistent, and undocumented.
- While EDS does offer better ‘content type’ limiting and labeling than the EBSCOHost traditional API, the content type vocabulary used applies to container of the record rather than the record itself — “Academic Journal” rather than “Journal Article” — which is a somewhat odd UI. Additionally, the terms used for labeling records in results don’t exactly match the terms you need to use for limiting (singular vs plural), which can make coding a flexible UI more challenging than it should be.
- Date sorting reveals metadata inconsistencies limiting the usefulness of this feature.
- The facetting API does not allow exclusionary facets (eg exclude “Newspaper Articles”).
API Authentication
The EDS API’s authentication process is quite complex, and a significant challenge to writing client software.
- Making an HTTP request to receive an authentication token. This token will need to be repurposed for all subsequent requests to the API. Since this token will expire after a period of inactivity, all responses need to be evaluated for token expiration errors. If a token expires, the client must re-authenticate and request a new one.
- Using the authentication token, the API requires a second HTTP request to generate a per-session token. The API requires the session token to be utilized for all future API interactions for a particular session. Since it can be difficult to track end-user sessions effectively within a web application, and even if you did so a given session in an app of this type may only make one or two queries, it might make more sense to initiate a new session for every query, despite the significant performance cost of doing so.
- EBSCO’s explanation for this session token is that some of the underlying databases have licensed connection limits, so they need to keep track of how many sessions are currently accessing. However, there’s no self-service way to tell which underlying data sources may have connection limits, or what those connection limits are. It’s unclear what will actually happen if the connection limits are exceeded, and the nature of the error message returned, if any.
This cumbersome authentication/setup process significantly adds to the difficulty of writing a client for the EDS API. It also degrades the effective response time to deliver results to the end-user, as in some cases several separate HTTP requests have to be made — and each HTTP request can have a one second or more response time.
End-user authentication
EDS does allow use with both authenticated end-users, as well as public/guest end users. If you tell the API you are using public/guest access, it has a rather novel way of accommodating this. Other ‘discovery’ products typically will transparently hide some results from the result set for ‘guest’ access. EDS also suppresses some results from the result set, but not transparently — instead, in a page of 10 results, several (or more) of them may be replaced by placeholder “Can not show this result to guest user” blocks. I am not certain if this results in a better or worse UI than what the other products do, there are some arguments both ways.
Documentation
Documentation is quite limited, and behind a customers-only login, which makes it inconveniently unavailable via a Google search.http://edswiki.ebscohost.com/EDS_API_Documentation
- “Console” app at https://eds-api.ebscohost.com/Console is quite useful for debugging and exploring the API in a browser, without having to deal with the insane auth/session workflow manually.
Primo
A decent API, which allows you to do what’s needed. Getting per-record metadata from the response format can be very confusing and under-documented, although on the plus side extensive metadata is usually present.
Notable features
- Query syntax does allow fielded searches.
- It is definitely not suitable for end-user direct entry, and can require some contortions to search multiple terms/phrases. It is also unclear if complex boolean expressions are supported.
- The query parameter in request can be repeated, which is convenient for multi-field searching.
- Supports facets, including creator, language, format, subject, pub year, db source, journal title.
- Supplies abstracts
- Has a ‘peer reviewed only’ limit.
- Custom relevancy rankings based on discipline and individual status (faculty, student, etc) are available. I did not explore this feature.
- A ‘highlight’ feature is available, but is poorly documented and difficult to use. This feature seems to only highlight certain metadata fields, and does not provide Google-style highlighted full text snippets.
Limitations or Issues
- Individual record response elements have many sections with similar data presented in different ways, without much documentation of the different response elements. This makes it difficult to determine which response element will provide the best, most consistent data for a given use. These varying presentations of certain elements may in fact be powerful support for complex use cases, but lack of documentation is a barrier to doing so.
- Error messages are sometimes XML and other times HTTP status codes with HTML response bodies. Expected error response specifications are not documented.
- During the survey, we ran into at least one strange edge case bug: searching for a long phrase with a question mark in it resulted in strange error message. This is possibly due to undocumented escape requirements of query input?
- Multiple format/genre vocabularies are used in responses, but there is inadequate documentation defining expected values or semantics.
- Queries with very many terms can have exceptionally long response times. Phrase queries with very many terms seem to sometimes return false negatives.
- While granular citation metadata is provided, it can sometimes be incomplete for certain records and not sufficient to generate a working OpenURL.
- There is a management interface to specify which PrimoCentral “collections” you want to include in your search. However, these collections are constantly changing, and I believe one must manually stay on top of changes to update one’s configuration to be searching all that is available.
API authentication
API is IP-address restricted for authentication, which is certainly easy to develop for, although it can be annoying if your server IP addresses can change.
If your API request is not from a registered IP, you improperly get an HTTP 200 response, with an empty body, rather than a proper HTTP error response and/or machine-readable error message.
End-user authentication
Access is allowed by both authenticated end-users and guest users. It is not clearly documented what differences in access levels are.
Documentation
- Documentation is restricted to customer-access only, making it unavailable for non-customer evaluation. It is on one giant HTML page with somewhat hard to read formatting.
- Documentation not present for the numerous controlled vocabularies, facets or fields available for limiting, some are mentioned anecdotally like peer-reviewed controls, but there is no complete list.
- http://www.exlibrisgroup.org/display/PrimoOI/Brief+Search
Scopus
A fairly reasonably designed, full-featured API for the basic search functions you’d expect from an A&I database. There are some limitations, including restrictive Terms of Service.
Notable Features
- Uses fielded and boolean search language equivalent to the Scopus native interface, making sophisticated searches possible.
- There is an incredibly full set of search indexes, letting you craft very precise queries.
- Has sufficient granular citation metadata (volume, issue, start page, issn, etc) to build an OpenURL, or export a citation (except only first author).
Limitations or Issues
- The documentation says some very limited faceting is available, but I have not tried it.
- There is no limit to peer review/scholarly content only, although most content in Scopus probably is peer reviewed/scholarly.
- Only the first author of a multi-author citation seems to be available from the API, even though documentation suggests otherwise.
- Sorting either doesn’t work at all, or doesn’t work as documented, especially for sort orders than ‘relevance’.
- No abstracts are provided (see ToS issues below).
- Queries that produce zero hits give an error message rather than simply reporting 0 hits. This was undocumented, and discovered through ‘reverse engineering’.
- Unlike the ‘discovery’ products, there is no query-in-context search term highlighting.
API authentication
- Scopus requires your API client IP address to be registered, and an API key additionally sent in an HTTP header.
- The API key sent in the HTTP headers makes debugging or exploration of API in a browser window difficult. Other products provide a ‘console’ app of some sort to work around this, but Scopus does not.
End-user authentication
Authenticated end-users presumably required to display any results from this licensed A&I database.
Documentation
Decent documentation is on the public web, but is occasionally out of date or lacking significant details.
- http://www.developers.elsevier.com/devcms/content-api-search-request
- http://api.elsevier.com/content/search/ (scopus section)
Terms of Service Limitation
The Scopus API terms of service (under ‘federated search’ case at http://www.developers.elsevier.com/devcms/content-policies) are unusually limiting.
- Link back to Scopus is required with presentation of results.
- Displaying abstracts or citation counts in an interface is prohibited. Lack of abstracts may be particularly problematic for many use cases.
Summon
SerialSolutions tells us that their default out-of-the-box Summon interface uses the exact same API available to customers to power it’s functionality. This kind of “dog fooding” is probably unique among the products reviewed, and it pays off. While not perfect, the Summon API is by far the easiest to work with, most consistent, and most flexibly powerful of the products reviewed.
Notable features
- Sophisticated query syntax, which is actually suitable for exposing directly to end-users if so desired, as it supports Google-style list-of-terms-and-phrases with reasonable semantics. It also supports fielded queries, and at least some level of boolean expressions. However, the search syntax isn’t documented. It appears to be based on solr-lucene query syntax, but with enhancements. Lack of documentation can make things tricky when you are machine-generating queries; it can be challening to be sure you are escaping what needs to be escaped, and in general that your machine-generated query has the intended semantics.
- Full featured faceting API, including applying ‘AND’ (conjunction), ‘OR’ (union) and ‘NOT’ (exclusive) facet limits.
- Large list of search indexes you can target and combine. This is useful for supporting finely targetted queries. However, in some cases, combined/aggregated indexes you might want are missing, such as an “any kind of subject” index as opposed to only “subject geographical”, “subject topical”, etc. Also, there is insufficient documentation as to semantics of search indexes, beyond a one phrase label.
- Both a “just scholarly” and a “just peer-reviewed” limit (not sure what the distinction is).
- A good vocabulary for ‘content type’ that matches my impression of what would be useful to users. However, mis-classification of item format is noticable, for example something classified as a “Journal Article” that is from a mass market publication nobody would consider a ‘journal’.
- Straightforward response format, with sufficiently granular data elements to generate OpenURLs or export citations, and in general has what you’d expect it to have, in reasonable places.
- The best query-in-context search term highlighting of any product reviewed, with Google-style highlighted snippets from fulltext, that works quite well.
- An interesting ‘direct link’ feature which aims to provide a URL to send the user directly to institutionally-licensed fulltext for an item, avoiding the OpenURL resolver where possible. I believe this feature supports multiple content providers, not just those owned by Serials Solutions parent company. I did not investigate this, but if it works well it could be a very useful feature. In limited experimentation, it did sometimes successfully link even to public-access pre-print copies on the web, which is a pretty neat feature. (Linking sources can be ranked and turned off in config).
- A ‘recommend a specific database’ feature, to send users to specific native database interfaces for databases matched to their query. I did not investigate the quality of results, but it is an interesting feature.
- Limits to local holdings and fulltext-available-only are based on the SerialSolutions 360 knowledge base, which would be convenient if you are already using this vendor for other products requiring knowledge base configuration.
Limitations or Issues
- While API returns a ‘language’ code labeling individual responses, it is frequently empty or labeled as English even for non-English articles.
- There were some problems applying multiple exclusive (“NOT”) facet limits. It’s not clear if I was encountering a bug in the API or if I was doing something wrong
- While there are a variety of facet groupings available, there is a lack of clear documentation of what facet groups are available. The developer has to reverse engineer from observed responses.
API authentication
You need to authenticate your API requests using a fairly complex (but technically secure and competent) algorithm involving cryptographic signatures. The requirements are actually quite similar to AWS API (although it is not identical logicImplementing a client complying with Summon’s authentication method would be a a bit challenging to implement from scratch, but libraries are provided in several languages to wrap API access, including authentication. I did not want to use the API for all requests; I prefer to stay closer to the HTTP metal and not use an extra layer of abstraction (with fairly spotty documentation) limiting my flexibility. Fortunately, the provided ruby implementation of a Summon API client was written such that I could easily instantiate and call the right classes to use the request-signing parts of the ruby gem alone in my own code, without using the rest of the gem.
End-user authentication
As is typical for the ‘discovery’ products, you can provide access both to authenticated local affiliate end-users, and ‘guests’. ‘Guest’ access has some restricted results suppressed from the result set.
Documentation
The API is reasonably documented, although it could be better in many places. As with the other products investigated, we could use more documentation of response format semantics and various controlled vocabularies. Particularly missed is sufficient documentation of the facet groupings and search field indexes.
Docs are on the web, with public access, which is great.
- http://api.summon.serialssolutions.com/help/api/search
- http://api.summon.serialssolutions.com/help/api/search/fields
- Useful ‘console’ app for debugging/exploring API in a browser window without having to deal with complex auth system manually: http://api.summon.serialssolutions.com/help/api/search/example?s.q=query

EBSCO, 2013-01-14
Jonathan, EBSCO agrees that “creating a better article search experience for our users” should be a primary goal for libraries choosing a discovery service. Your study’s focus on APIs and least common denominator metadata presentation is one data point.
Other complementary studies have been conducted this year to answer the question you acknowledged wasn’t answered by your study – “We do not know why participants preferred one tool to another”. We wanted to point out one study in particular conducted by librarians at Illinois Wesleyan (EDS) and Bucknell (Summon) – “Paths of Discovery: Comparing the Search Effectiveness of EBSCO Discovery Service, Summon, Google Scholar, and Conventional Library Resources” [http://crl.acrl.org/content/early/2012/05/07/crl-374.full.pdf]. This study focused on student search behaviors, speed to success, and quality of research in comparing a variety of services. In addition to ranking EDS first, this study came to several interesting conclusions on searching.
Nearly all of the negative issues you encountered with the technical features of the EDS API were either a result of not using best practices (which we would have suggested if your institution were a customer) or are features we have added to the API since your study began in May 2012. Details and more complete commentary: http://www.ebscohost.com/uploads/general/Johns_Hopkins_API_Comparison_EBSCO_Feedback.pdf
Serials Solutions, 2013-01-14
This study does a good job of illustrating the value, performance and ease of use of the Summon API, but doesn’t address the fact that library discovery services must do more than simply provide a single search box for article content. With its unified index architecture, powerful relevance-ranking and ability to present precision results in a clean, intuitive and user-friendly interface, the Summon service moves users beyond searching siloes of content. The Summon service increases usage of more than just popular aggregator packages by mapping content from all providers to a common schema to ensure equal treatment of content and therefore boosting visibility and access to underutilized collections. And, as this study suggests, user experience and results presentation are paramount to users’ perceptions of a discovery tool’s effectiveness. User experience is a critical factor when evaluating discovery solutions. [see external report] The Summon service provides layers of contextual research assistance and opportunities for librarians to impact the research process to optimize user experience—all without using the API. This is why the vast majority of customers who do use the Summon API for building custom applications also present users with the full-featured, “out-of-the-box” interface to meet a variety of user needs and expectations.
Emily Lynema, 2013-01-16
Jonathan, I’m so excited that you did this study. I remember talking about it at Code4Lib last year. I’ve only skimmed this report and look forward to reading it in more depth. Awesome job highlighting the statistical significance (or insignificance) of the results. But I’m not highly surprised about the results. Student rankings are often fairly indifferent in terms of relevance. It would indeed be interesting to include some librarian rankings in this set for comparison.
It also emphasizes that some of the differences in these tools have little to do with relevance of result sets — things like the usability of the interface and the scope of content included also play a big role.
We’ve been doing a periodic re-evaluation of the playing field here, and I’m forwarding this on to our staff for digestion. Thanks again!
Dmitry Green, 2014-11-26
Hello,
Thank you for this article.
As a physics phd (Yale 2001), like many people, I have been frustrated with many of the search interfaces. Here’s a tool that I have been building with my team:
Arximedes.org is a new interface that helps professional researchers separate the wheat from the chaff. At the moment we are focused on physics & technology (it is not a social network and we don’t spam), having integrated NASA ADS and ArXiv.
In addition to getting a laundry list of papers, as in standard search engines, we’ve built another processing layer on top. You can see which authors are driving research within the topic you are searching, visualize publication rates, and track who is citing whom. A newsfeed automatically organizes daily updates to your searches.
We’ve also built a simple way for you to rate papers. Unless you are an expert in a very narrow field, it is hard to make sense of the literature. At the same time, most professional researchers “know it when they see it”, quickly.
You can take register and use it for free.
Here is a brief video: http://youtu.be/kj_Q7iqNq8o and pdf overview: http://arximedes.org/static/project/images/arx_overview.pdf.
Thank you