by Kyle Banerjee and Maija Anderson
Introduction
Archival photograph collections are often the centerpiece of digital initiatives. Compelling images create powerful visual ties to institutional history, impressing administrators and funders while serving purposes ranging from public relations to intensive academic research. Collected in analog formats or as born-digital objects, they come to the archives via institutional departments and individual donors by the hundreds and thousands.
Photographs appeal to diverse user groups, and researchers expect archival collections to be easily discoverable and keyword-searchable online. Using traditional methods, providing this access requires specialized staff with knowledge of archival collections who are skilled in creating original metadata as well as historical research. When dealing with a collection of hundreds or thousands of photographs, balancing the expectations of researchers with staffing realities is challenging.
Without judicious project planning through all stages of digitization, projects to digitize archival photos become bottlenecked at the point of metadata creation. Even managers experienced with other digitization projects often underestimate the time it takes to create specialized metadata for archival photographs — leading to a backlog of scanned images without descriptive metadata [1]. Backlogs may also be generated through scanning for in-house use, exhibits, or researcher requests. Backlogs of born-digital images grow as donors contribute collections of digital photographs, often with no description beyond a filename. To be made accessible, these scanned images require complete metadata as well as hosting on a public platform. Without this support, images are stored on servers, external hard drives, networks, or staff computers where they are effectively hidden from staff as well as researchers.
We suggest there are opportunities for archivists and systems staff to collaborate in automating metadata creation and harvesting metadata more efficiently. This article demonstrates how staff with modest technical skills can use simple automation techniques to leverage existing metadata in digital and digitized photographs and information obtained from facial recognition software to assign metadata more quickly, accurately and completely.
Things you need to know
Most systems that libraries use to store digital photographs do not take advantage of metadata within the digital image files. Rather, this information is managed in an external database. However, even for institutions that use systems that depend on external metadata, there are several advantages to utilizing and creating metadata directly within the files themselves:
- Automatic extraction of technical metadata such as creation date, dimensions, resolution, and bit depth
- Automatic assignment appropriate access points such as subject and location to groups of photos
- Images are more discoverable via search engines
- Information associated with the image travel with it including use restrictions with the image however it is used
- Enhanced portability of collections. Migrating images to new digital asset management systems is simpler
- Metadata can be created, edited or deleted for many images per second which is orders of magnitude faster than opening them individually in image processing programs such as Photoshop and Gimp. Consequently, it is practical to use processes that focus on individual metadata elements across many images at once
Image metadata
Image metadata is stored directly in the image file. While format and location of metadata in binary files can vary depending on image format, it can often be read simply by viewing the image in a text editor. The following is an excerpt from the top of an image file:
II???@d??F?(1?2?? ??]BI?? ?Ci?Black and white photograph of Esther Pohl
Lovejoy and Doctors Elliot and Moskovetz in Athens in
1923.??['??['Adobe Photoshop CS2
Windows2012:04:10 14:16:16<?xpacket begin="?" id="W5M0MpCehiHzreSzNTczkc9d"?>
[lines deleted]
<rdf:Description rdf:about=""
xmlns:tiff="http://ns.adobe.com/tiff/1.0/">
<tiff:ImageWidth>6046</tiff:ImageWidth>
<tiff:ImageLength>4880</tiff:ImageLength>
[more lines deleted]
<dc:subject>
<rdf:Bag>
<rdf:li>Lovejoy</rdf:li>
<rdf:li>Moskovetz</rdf:li>
</rdf:Bag>
</dc:subject>
[more lines deleted]
</rdf:Description>
Notice that the metadata is stored as plain human readable XML. Though not visible in this example, metadata using several different schemes were stored in this photo. When this happens, it’s clearly labeled, so you can easily identify components you’re interested in.
By familiarizing yourself with three complementary image metadata standards, you can maximize the portability of your metadata and develop better photo processing routines. It’s important to be aware that these standards are relatively new so they are inconsistently implemented across platforms. Nonetheless, they are still very useful for processing and planning for the future.
The most reliably supported image metadata format is Exif (Exchangeable Image File Format). Virtually all scanners and digital cameras populate images with Exif metadata which provides extensive technical information and supports geolocation as well as a number of TIFF (Tagged Image File Format) attributes (Exchangeable image file format for digital still cameras … [updated 2012]). Standard archiving procedures for digital photographs include recording numerous details including height, width, color depth, and resolution. Since this information is typically embedded directly in the file, there is no reason not to simply extract it using a utility like ExifTool.
Exif does not provide tags for many access points that are important to libraries, so this information is generally best included using IPTC (International Press Telecommunications Council) or XMP (eXtensible Metadata Platform) extensions. IPTC metadata is built largely around the needs of professional photographers so it provides a number of useful fields such as named individuals in photos. IPTC does not provide a number of fields needed by archivists and librarians, but XMP provides great flexibility including the ability to create previously undefined tags.
Working with multiple standards may sound confusing. However, the process of writing each type of metadata to images is nearly identical as will be demonstrated later. The main thing to remember is to use Exif for what you can (mostly technical information), then IPTC for some descriptive and administrative information not covered by Exif, and XMP for everything else.
Utilizing facial recognition with archival photographs
A number of facial recognition technologies exist and describing them is beyond the scope of this article. There is variation in the accuracy of these technologies, but differences in lighting, facial expression, and viewing angle are problematic for all two dimensional forms of facial recognition (Grother et al. 2011). Having said that, accuracy is still high enough for facial recognition software to be of significant assistance to those processing digital photographs.
Facial recognition is useful for a number of reasons:
- For many photos, identifiable people represent the most important access point
- By its nature, it provides authority control and prevents multiple variations of the same name from inadvertently being used in a collection
- Identification of individuals can help staff determine when and where a photo was taken as well as the subject matter of the photo
- Even when the software cannot determine who is in the image, extraction of faces simplifies manual identification and organization
- Non-specialist staff can do more metadata work
A variety of software applications and services that perform facial recognition are available — even most smartphones have this functionality. For purposes of assigning metadata in a library setting, Google’s Picasa works well because it is free, fast, and stores information about people in two files that can easily be read. However, any facial recognition software that stores information it finds in a parsable format would be practical in a library setting. Staff will want to recognize things as well as people, so be aware that facial recognition is designed to work with people. It is not effective for animals, geographic features, buildings, and artwork.
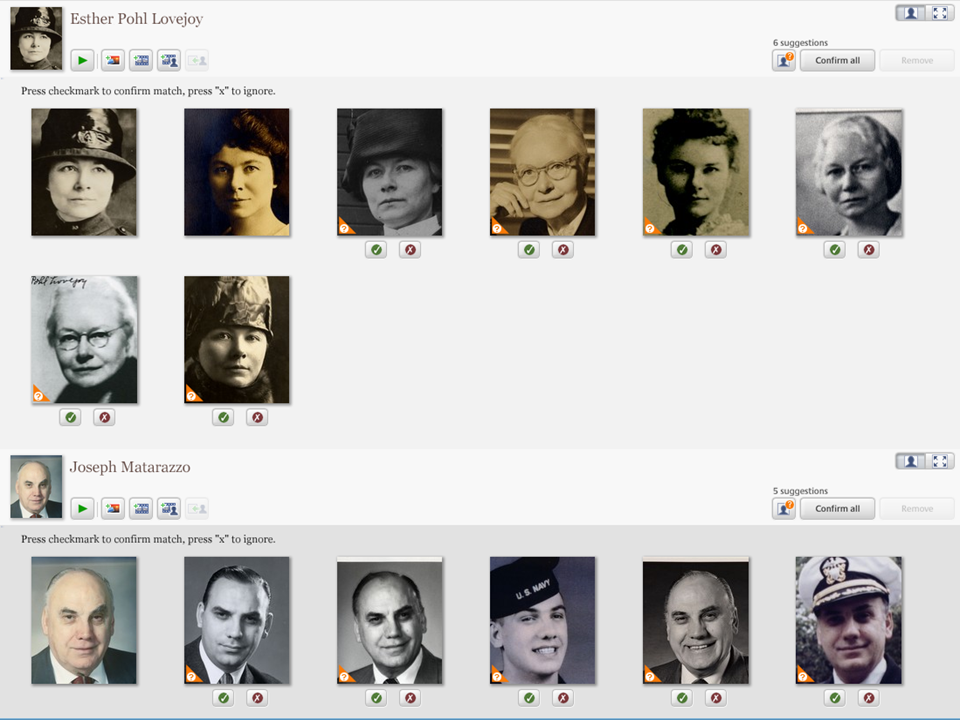
Figure 1: Picassa Facial Recognition
Figure 1 demonstrates the mechanism Picasa uses to identify people. An algorithm detects faces which are matched against known individuals. When a probable match is found, Picasa provides checkboxes that allow staff to confirm or reject the match. Matching becomes more accurate as Picasa learns more about each person. Staff can assign rejected matches and previously unknown faces to any name desired.
Accuracy of matching depends on many factors including pose, lighting, facial expression, aging, orientation of photo, image resolution, number of photos previously matched, total number of faces it must compare, and genetic similarity of people in photos. Accuracy at Oregon Health and Science University has been well over 90%. However, it is still essential to manually review matches. Picasa does not guess when it cannot determine who an image may be. Also, if it determines that a face could match multiple probable identities, it lists only those which narrow the list of possibilities staff must consider.
Like most photo management software, Picasa supports tagging. Picasa stores tagging information within the Exif metadata in the image itself so other programs can utilize this information. However, Exif provides no mechanism to indicate where people appear in photographs and who they are so Picasa stores this information in .picasa.ini and contacts.xml.
As the name implies, contacts.xml keeps track of people. For the example in Figure 1, the corresponding entries in contacts.xml are as follows:
<contact id=”c0ef2256901bfbb6” name=“Esther Pohl Lovejoy”
modified_time=”2012-11-26T09:48:04-08:00″ local_contact=”1″/>
<contact id=”c2c65f903b3150cb” name=”Joseph Matarazzo”
modified_time=”2012-11-30T15:02:10-08:00″ local_contact=”1″/>
The identifier in red text is used as a key to identify the individuals in .picasa.ini. In the examples above, the key is only linked with a name for the person. If more extensive information is added to the contacts database, it will appear here.
The .picasa.ini file contains information describing which individuals were identified in photos and where they appeared. Consider the example entries below:
[lovejoy-esther_portrait_nd.jpg]
faces=rect64(135a175de074cd8b),c0ef2256901bfbb6
backuphash=23375
[matarrazo-joseph_2001.jpg]
faces=rect64(3407026fe607ac00),c2c65f903b3150cb
backuphash=33
Each entry begins with the filename in brackets. The faces entry are four 16-bit hexadecimal entries which define the points of a rectangle containing the face. The backuphash tag is not relevant for purposes of inserting information about people into photo metadata. The important thing to notice that that every person identified in a photo receives an entry in .picasa.ini that points to an individual in contacts.xml. This makes creating a list of all files and associated people trivial in virtually any language, though there is free software that can do this for you (Picasa face detection to lightroom … [updated 2010]).
Incorporating facial recognition data into image metadata
The easiest way to interact with metadata in image files is using ExifTool, a free Perl library that supports a wide variety of open and proprietary metadata standards (Harvey … [updated 2013]). During the authors’ tests, it consistently read, modified, and wrote metadata as expected. Other software can be used to interact with image metadata, but all programs should be tested with local procedures to ensure no undesirable modification occurs.
Adding metadata headings to photos is simple. For example, if we want to add a person, we can use an IPTC extensions because Exif does not define a person tag but IPTC does:
exiftool -XMP-iptcExt:PersonInImage+=”Doe, John” myimage.tif
To add a Dublin Core (DC) subject to a photograph, we use an XMP extension because neither Exif nor IPTC defines a subject tag:
exiftool -XMP-dc:Subject+=‘My new heading’ myimage.tif
In addition to having a command line interface, bindings for ExifTool can be found for many programming languages. ExifTool is very useful for synchronizing metadata that is managed by an external image with metadata within the image.
Extracting image metadata for use in external systems
Most image management systems do not use image metadata. Rather, they store this information in an external database. Most libraries encode technical metadata (dimensions, size, color space, etc) by having staff open images manually and extracting this data. This process is slow and error prone. If useful metadata within the file is automatically transferred to spreadsheets or XML files that can be loaded, processing speed will improve while reducing error rates.
Extracting information from files using ExifTool such as technical metadata is simple.
Labeled display can be extracted with:
exiftool filename
XML output can be obtained with:
exiftool –X filename
Tab delimited can be generated with:
exiftool –T filename
Embedded metadata within images lacks elements that many libraries want, so it’s best to use it as a starting point to populate spreadsheets, templates, or simply be made available to staff via copy and paste.
If staff modify metadata in an external system in accordance with predominant library practices, these changes will not be reflected in the embedded metadata within the image unless specific measures are taken to do so. Libraries that write routines that transfer this data automatically to image files should be aware that file checksums will change, which will require integrity monitoring routines need to be modified accordingly.
Exploration and future directions
Facial recognition software is a powerful tool for archivists trying to digitize and organize large collections of archival photographs. Our case demonstrates that staff with modest programming skills can significantly accelerate creation of accurate item-level metadata using free consumer-oriented software such as Picasa.
Using facial recognition software in conjunction with creative approaches to automation offers intriguing possibilities for making social metadata a more reliable source of descriptive information. Staff and researchers alike sometimes recognize individuals who are not identified in photographs. If the user interface further engages users — game interfaces have already been shown to generate more extensive metadata than casual crowdsourced tagging (Flanagan and Carini, p. 532) — the software can be taught to recognize additional images containing that same individual.
Combining information from facial recognition software with methods to read and write metadata directly to and from images allows libraries to provide more reliable and extensive metadata for more photographs than can be accomplished with staff and crowdsourced tagging alone. By leveraging the expertise of users who have a high level of knowledge and personal engagement with collections, individuals in photographs can be identified throughout collections which in turn can improve the usability of collections.
Creating metadata for archival collections will never be an entirely automated process – the interpretation and organization of content as well as legal and ethical issues will always require an archivist’s judgment. While metadata for digital archival collections can not be entirely automated, our example illustrates that more of it can be automated than one might assume. This is a critical consideration for archives faced with large image backlogs requiring detailed item-level metadata. Archivists would be well-served to work with systems staff to identify ways in which metadata creation can be automated, giving archives staff time to focus on those areas where human judgment is most valuable.
Notes
[1] Since 2011, staff in OHSU Historical Collections & Archives have been working to create item-level metadata for a backlog of several thousand digital images. Benchmarking for this project suggests that with some automation and a refined workflow in place, creating metadata for a single image requires an average of 20 minutes of staff time.
References
Exchangeable image file format for digital still cameras: Exif Version 2.3 [Internet]. Standard of Japan Electronics and Information Technology Industries Association. Camera & Images Products Association. [cited 2013 Apr 4]. CIPA DC-008-Translation-2012. JEITA CP-3451C. 185 p. p. 9. Available from: http://www.cipa.jp/english/hyoujunka/kikaku/pdf/DC-008-2012_E.pdf
Extensible Metadata Plaform (XMP) [Internet]. [cited 2013 Apr 3]. Available from http://www.adobe.com/products/xmp/
Flanagan, Mary & Carini, Peter (2012). “How games can help us access and understand cultural artifacts.” American Archivist 75(2), pp 514-537.
Grother, Patrick J, Quinn, George W., and Phillips, Jonathon P. 2011. Report on the Evaluation of 2D Still-Image Face Recognition Algorithms [Internet]. [cited 2013 Apr 2]. [cited 2013 Apr 4]. NIST Interagency Report 7709. Available from: http://www.nist.gov/customcf/get_pdf.cfm?pub_id=905968
Harvey, Phil. ExifTool. [cited 2013 Apr 3]. Available from: http://www.sno.phy.queensu.ca/~phil/exiftool/
Is Picasa 3 silently modifying exif info and dropping exif data???!!! Google Product Forums – Picasa . [cited 2013 Apr 4]. Available from: http://productforums.google.com/forum/#!topic/picasa/32jkT3GQSOw
Metadata Games. [cited 2013 May 30]. Available from http://metadatagames.com
Picasa. [cited 2013 Apr 4]. Available from: http://picasa.google.com/
Picasa face detection to Lightroom. Gregor’s blog. [cited 2013 Apr 8]. Available from: http://blog.gregerstoltnilsen.net/2010/07/picasa-face-detection-to-lightroom/
Riecks, David. IPTC Standard Photo Metadata (July 2010) : Adobe CS5 File Info Panels User Guide [Internet]. [cited 2013 Apr 4]. Available from: http://www.iptc.org/std/photometadata/documentation/IPTC-CS5-FileInfo-UserGuide_6.pdf
About the Authors
Kyle Banerjee (banerjek@ohsu.edu) is the Digital Collections and Metadata Librarian at Oregon Health & Science University.
Maija Anderson (andermai@ohsu.edu) is the Head of Historical Collections & Archives at Oregon Health & Science University.

Subscribe to comments: For this article | For all articles
Leave a Reply