by Ted Diamond, Susan Price, and Raman Chandrasekar
1. Introduction
Search engines are commonly used today, ranging from general purpose web search engines such as Google and Bing, to specialized academic search products such as Dialog (Dialog 2013) or the Summon® web-scale discovery service (The Summon® Service 2013).
In the early stages of information retrieval (IR) systems, studies were typically conducted using a test collection consisting of a static set of documents, a static set of queries, and a set of “gold standard” relevance judgments generated by a human expert. This approach to studying IR is often referred to as the Cranfield paradigm after the studies performed at the College of Aeronautics at Cranfield by Cyril Cleverdon (Cleverdon 1967). The series of annual Text REtrieval Conference (TREC 2013) events follow a similar methodology on a somewhat larger scale. Such studies emphasized finding ways to improve document-ranking algorithms based on document properties, such as term frequency, or collection properties, such as inverse document frequency and Page Rank (Brin and Page 1998). Returned documents were considered either relevant or not, and the user was largely left out of the picture. The Cranfield approach stands in contrast to surveys and user-oriented studies that focus explicitly on the user experience and users’ feedback. Ingwersen and Järvelin (Ingwersen and Järvelin 2005) provide a detailed discussion of the interplay between lab-oriented and user-oriented studies in IR. More details about document ranking algorithms can be found in classic textbooks such as those by Salton (Salton and McGill 1986) or Manning (Manning et al. 2008).
With the proliferation of web-based search systems, it is now possible to aggregate information from a large number of user queries and actions. For example, studies have reported on the average query length and the most common terms and topics in queries (e.g. Jansen et al. 2000; Jansen and Spink 2005; Kamvar et al. 2009). Log data enables us to study IR in the context of users while allowing us to analyze user behavior across a much larger number of queries and a much larger number of users than would be possible in a controlled experiment for which users are recruited, observed, and possibly assigned search tasks. Log data is often a more reliable signal than data produced by either simulations of users (submitting batch queries in a test system) or experiments that observe users in a lab because log data is about what people actually do rather than what we think they do or what they say they do. With a significant volume of logs, we can garner useful quantitative insights into our search systems. Furthermore, we can learn from this data. We can change search systems in response to our findings, and measure the effects of our interventions.
This paper is precisely about this – a description of how we use query logs and click-through logs to gain insights about users’ (actual) search behavior, in order to help us provide a continually improving search experience for our users.
Section 2 outlines the context of this work, to ground the discussion that follows. However, it is important to note that while the work is described in terms of our implementation on a web-scale discovery system, the discussions and conclusions are not specific to our environment. Much of what we describe applies to any similar large-scale search system with significant query and click traffic in which all users search the same body of content and the data being searched shares a common schema.
Section 3 describes the Relevance Metrics Framework (RMF) that we developed to aggregate and learn from logs. We start by listing our goals for this framework, as well as two concepts that are at the foundation of this framework. We then outline the dataflow in the framework, and the metrics and statistics we compute.
In Section 4, we describe some insights that we have gained from the RMF that have helped us improve the Summon user experience, basing our changes on real user data. There is, however, more work to be done to improve the framework, and Section 5 outlines some challenges and assumptions in the current system, and how we can obviate some of these issues. We conclude in Section 6 with a look at work ahead.
2. Web-scale discovery systems
In this paper, we describe a framework to analyze logs from a large-scale search engine. Much of what we describe here, and the conclusions we reach, would apply to any such search system with significant query and click traffic. However, in order to keep the discussion grounded, and to provide real examples that can be interpreted, we describe the specific search engine that we are using, the Summon® discovery service.
The Serials Solutions Summon® discovery service provides a hosted Software as a Service (SaaS) solution for searching all of the resources in a library’s collection and, optionally, resources beyond the individual library’s holdings. Behind the scenes, Summon uses a single unified index that is created after matching and merging records that originate from multiple sources. The Summon index includes well over a billion items from a wide variety of publishers and vendors. Figure 1 shows a sample Summon result page.
From a single search box, users can search over both metadata and full text records, find resources from multiple publishers, and receive a single unified set of search results. In addition to supplying a simple query consisting of one or more terms, a user can apply a variety of filters and facets to the search, or use advanced functionality to search particular fields or apply Boolean or other specialized operators. The final list of search results is compiled based on a sophisticated set of algorithms that calculate the relevance of various documents to each specific query.
 Figure 1. Sample Summon result page (current version)
Figure 1. Sample Summon result page (current version)
The Summon® discovery service serves a growing list of over 600 customers and supports native searching in 17 languages. Clients may either use our hosted service to retrieve results and to render these results, or retrieve results from the Summon API and render the results themselves. Because it is a hosted service, and because queries are centrally processed, Summon is able to track all queries. In addition, clicks on results can be logged from pages rendered by Summon. Thus, unlike systems that federate queries to different engines, Summon is able to acquire and aggregate logs, and use these aggregated logs to continuously improve the user experience.
The discussions and conclusions in this paper will apply to any similar engine and environment.
3. The Relevance Metrics Framework
We constantly strive to improve the quality of our users’ research experience. As part of this effort, we built the Relevance Metrics Framework (RMF) as a tool to help us understand how our customers use Summon and enable us to assess the quality of the search results we return. We have three main goals for RMF.
3.1. RMF Goals
With the RMF, we wanted to define and develop a framework that would permit us to:
Observe and log user actions.
We collect data about each query submitted to Summon. For the RMF, we define a query as a single request from the user to the Summon system. A query consists of the search terms plus any filters or facets used to limit the results and any advanced syntax or operators used to define the request. We do not consider a request for additional pages of results for the same request to be a new query, although we log the total number of results and pages that are displayed to the user. We log the query terms entered, filters applied, facets chosen, and advanced syntax or operators used. We also collect data about clicks on search results. Our focus with the RMF is relevance, not the user interface (UI), so we do not instrument UI elements or measure UI feature usage. Figure 2 has some sample queries submitted to Summon. Note that in the sample we have queries in different languages, some with filters (green fixed-width font), and some with facet restrictions (blue italicized font). For example, the query publicationtitle:(BBC Monitoring Former Soviet Union) s.fvf=ContentType,Journal Article,f, s.rf=PublicationDate,2007:2007 represents a request for documents with the following terms in the title: BBC Monitoring Former Soviet Union and limited to the facet journal articles and filtered to those published in 2007.
The data in the RMF is anonymized. We know when a query was submitted, and to which customer-library’s interface, but we do not store information that could identify the end-user who submitted the query.
Compute the quality of search results.
We compute various metrics to assess the quality of our search results, based on user interaction with the results returned. We discuss the metrics, and underlying assumptions, in Section 3.4 below.
Analyze data to improve the Summon product.
We analyze the data we collect to improve search results and, more broadly, to enhance the user’s research experience. By observing the queries that users submit, we can glean information about query styles (e.g. length and specificity of queries; use of natural language vs. terse phrasing; or inclusion of terms that would appear in different metadata fields, such as title plus author name or pasting an entire citation from a reference list into the search box) and user intent. Measuring relevance helps us identify the types of queries that tend to result in good results and the types of queries that return results that are not as good; this helps us identify areas for intervention and improvement.
Records of user behavior during day-to-day use provide concrete evidence regarding how a product is used, and real-life feedback regarding how well the product meets users’ needs. We obtain enough data to draw inferences about typical performance on classes of queries.
- anniversary 9/11
- kidney stone
- moore vs mack
- moore vs mack trucks
- Armee Deutschland Rolle in Einheit
- body art in the workplace
- the moplah rebellion of 1921 john j. banning
- ?????
- 9780140027631
- “boundary dispute” Title:(india)
- SubjectTerms: “???”
- TitleCombined: (Analytical Biochemistry) s.fvf(ContentType,Book Review,t)
- Hawthorne, Mark. “The Tale of Tattoos: The history and culture of body art in India and abroad.”
Figure 2. Sample Summon queries
3.2. Useful Underpinnings
Two concepts have proved enormously helpful for interpreting user behavior in the RMF: the notion of search sessions, and the use of clicks as an indicator of relevance.
3.2.1. Search Sessions
When a user interacts with a search engine, whether it is a library discovery tool such as Summon, or a web search engine such as Google or Bing, it is not unusual to enter multiple queries to satisfy a particular information need. These iterations of the user’s request, each one involving adding, subtracting, or changing terms, filters, or advanced operators in the query, are not independent. A search session that ends in a satisfied need is a success, even if the search session requires multiple queries. In general, though, satisfying the need with one query is better than requiring multiple queries. We find the notion of a search session to be a useful abstraction for describing the use of multiple queries to find information for a single information need. By analyzing the data for both individual queries and search sessions, we get a broader perspective on user behavior and the ability of the system to meet users’ needs. However, it is not easy to automatically identify search sessions in query logs. We heuristically define a search session as a set of one or more queries with no more than a 90-minute gap between queries, and lasting no more than eight hours in total.
Search sessions are also useful for limiting the effect of noise and query spam on relevance metrics. As noted later in the paper, we see some query patterns that clearly do not reflect the efforts of serious end-users trying to perform research or other information gathering tasks. In some cases we have seen thousands of queries being issued over a small period of time, most likely through a script. Grouping these queries into a single session mitigates the effect such queries might have on our metrics, and makes the RMF more robust in the presence of noisy data.
3.2.2. Clicks as a Proxy For Relevance
In classical information retrieval experiments, relevance is measured using a known set of queries against a known set of documents for which relevance judgments have been made available. These relevance judgments are not easy to garner for large-scale search engines, and any such judgments may not necessarily reflect whether a document satisfied the particular information need underlying an individual user’s query. Ideally each user would tell us which document(s) satisfied their need and which document(s) do not, but of course such information is not available.
Instead, we have to make inferences based on user behavior, and the most readily available signal we have is click data. Not every document a user clicks on is relevant. Not every potentially useful document in the search results gets clicked-on, even if it is returned on the first page. However, documents that are not clicked on are generally not useful to the user (with occasional exceptions, such as when the metadata or a snippet contains an answer to a specific question). So we can consider click data to be an upper bound on relevance. If there were no clicks, the search was probably unsuccessful. If there were n clicks, then up to n documents were useful (relevant). Over a very large set of data, clicks provide a useful, if imperfect, proxy for relevance judgments.
3.3. Dataflow in RMF
Data in the RMF comes from two sets of logs: (1) the logs from the search servers, which produce the search results that are returned to users in response to queries, and (2) click logs that record data about result links to documents that are clicked-on by the user. The search logs, which contain a browser session id, a timestamp, the url corresponding to the query, and other information about the query and the results list are fed into a Query Summarizer component. The Query Summarizer extracts the data of interest for each query, such as time of submission, the customer library receiving the query, search terms, filters, number of results found, and number of results displayed (i.e. number of pages viewed multiplied by number of results displayed per page) into a Query Summary object. Data from the click logs is associated with individual queries using the browser session id and timestamps. Query Summary objects are grouped into sessions by first using the browser session id and then applying our own heuristics to segment browser sessions into multiple search sessions when appropriate. The Session Summarizer component extracts data about each session into a Session Summary.
The query summaries provide data input to a Query Metrics Calculator component, which calculates various query-level metrics. The metrics are input to the Query Statistics Calculator, which uses the query metrics to calculate statistics based on aggregated query data. Similarly, the Session Metrics Calculator calculates session-level metrics, which are used by the Session Statistics Calculator to produce statistics based on aggregated session data. Query data, query metrics data, session data, and session metrics data are loaded into a relational database for storage and easy retrieval.
3.4. Metrics Computed in RMF
We calculate a number of metrics at the session and query level. For example, at the session level we track abandonment (defined below), and the number of queries to the first click or to abandonment. At the query level, we track abandonment and measures of how well relevant documents are ranked. We describe each of these metrics in more detail below.
- Abandonment
When a user submits a query but does not click on any of the search results, we refer to that behavior as query abandonment. Abandonment usually indicates a failed search. There are some rare exceptions to this, e.g. where the user’s information need can be satisfied by the results display itself. For example, the question “Who wrote the book The Mythical Man Month?” can be answered by entering the query “Mythical Man Month” and seeing “by Frederick P Brooks” in the display for the first result, without having to click on the item.
When a user submits one or more queries in the same search session and does not click on any search results, we refer to that behavior as session abandonment. We calculate both average query abandonment and average session abandonment. Low values of abandonment suggest (but are not proof of) better user satisfaction whereas high values of abandonment almost certainly indicate user dissatisfaction.
- Number of queries to first click
Consider a session where the user enters one or more queries, and scans the results to see if there are any results that look sufficiently relevant to warrant clicking on the result to view the document. The value of number of queries to first click indicates how much effort (in terms of the number of queries issued) was required before the likely-to-be-relevant item was selected with a click. While not every clicked document is relevant, over a large number of queries, having a lower value for the number of queries to the first click generally indicates a better search system than a higher value does.
- Mean Reciprocal Rank (MRR)
We want a search engine to return the most relevant results at the highest rank, i.e. at the top of the list of search results. MRR considers only the rank of the “best” (lowest ranked) clicked result. MRR is computed as
1/(rank of the top-ranked clicked result). If the first result is clicked, MRR = 1/1 = 1. If the first clicked result is at result rank 5, MRR = 1/5 = 0.2. In general, higher MRR is better. If no results are clicked we define MRR to be 0.
- Discounted Cumulative Gain (DCG)
Users frequently click on multiple search results. Sometimes that is because the first result turns out not to be what the user was looking for. For an informational query, many documents may be relevant to the search, and the user may want to find multiple resources. DCG is a metric that provides a single number to describe the goodness of a search result with potentially multiple relevant results. The intuition is that the right (relevant) results should be ranked in the right order. DCG awards a ‘gain’ (score) to each relevant document, but the highest gain is given to documents ranked at the top of the results list. Gain is progressively discounted, as results appear lower in the results list. The degree of discounting can be adjusted by changing a parameter in the calculation. Gain is cumulated across all relevant documents for a query. Hence the term discounted cumulative gain. In general, a higher DCG indicates a better result set. Appendix A has an explanation with examples about how DCG is calculated.
4. Gains from RMF
We have seen in the sections above how we acquire log data, and the metrics and statistics we compute from the logged data. In this section, we provide a few examples of our analyses and our use of data from the RMF.
Broadly, we use the RMF both as a data source for tools that improve the search experience, and as a source of insights about user behavior that inspire new features.
4.1. Data source for tools
We use query data from the RMF to automatically generate suggested completions of the query as the user starts to type in the search box, as illustrated in Figure 3. Once the query has been submitted, we not only return search results, but we also display suggestions for related queries. These suggestions are also derived from query data from the RMF.
 Figure 3. Query Autocomplete, based on users’ queries
Figure 3. Query Autocomplete, based on users’ queries
4.2. User behavior and Insights
4.2.1 Patterns of search use
In general, whereas the number of query sessions varies regularly with the day of the week (more query sessions during the week and fewer query sessions on the weekends), the average number of queries per session is quite stable. Figure 4 illustrates the pattern over a six-week period that is near the beginning of the fall term for many academic institutions. The X-axis shows the number of days since the start of this sample. The Y-axis denotes the number of sessions per day, as well the average number of queries per session (on a different scale). We have omitted the numbers on the Y-axis. However, the Y-axes cross the X-axis where y=0 so the shapes of the curves indicate the trends and their relative magnitudes. The search volume is highest in the middle of the week and lowest on weekends while the average number of queries per session does not vary much by day of week. The growth of overall search volume is probably due to a combination of the progression of the academic term and overall growth of Summon usage.
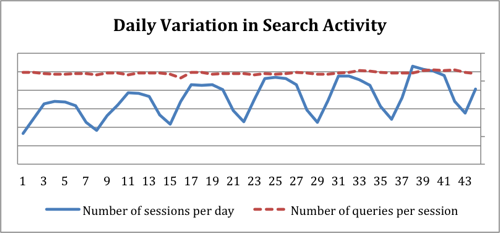 Figure 4. Patterns of Search usage
Figure 4. Patterns of Search usage
4.2.2. Optimizing default results per page
When we display a larger number of results on each page, the user needs fewer page navigation clicks to scan a large a number of results from his search. However, if the number of results displayed per page is larger, more data must be transferred to the user, and hence there is a longer latency between query submission and the display of the results page. Many users may prefer shorter latency, but some users will want to see a larger number of results on a page. Summon offers the flexibility to return 50, 25, or 10 results per page (RPP), depending on the preference of the user or library. The RMF provided insights for setting the ideal default RPP. From an analysis of RMF data we determined that most clicked documents appear in the top 10 results. That data gave us confidence that, for most users, the benefit of improved performance would outweigh the cost of reducing the RPP from its original default of 25 to a new default of 10. After we made the change, we monitored several metrics, but we did not see a decline in relevance metrics. It is still possible for users to change the default results per page (and some do), but we have found that most users do not change the RPP, suggesting they are satisfied with the new default.
4.2.3 The nature of user searches
We have found that users typically start with simple searches, and only occasionally make use of advanced search features. Summon offers both a basic search interface (simple text box, similar to that offered by Google and Bing) and an advanced search interface that allows the user to specify that particular terms should appear in specific fields, such as Author, Title, or ISBN. Advanced syntax may also be used directly in the simple search text box. For example, advanced search operators are available, such as Boolean operators (AND, OR, NOT), wildcard expansion (child* matches child, children, and childs) and sloppy phrases (terms in a phrase may be separated by a specified number of positions).
Not surprisingly, we find that most queries use only the simple search and no advanced syntax. Less than 6% of queries specify one or more search fields, with the most commonly searched fields being Author and Title. Less than 4% of the sessions start with a query using search fields. So we believe most users start with a simple search, and only add fielded search if they cannot find what they are looking for. Even fewer searches make use of advanced syntax features, with only a little over 2% of searches using one or more advanced operators.
On the other hand, filter usage is quite common. Various types of filters are available that allow a user to easily restrict the results of his query to make the query more precise. For example, Summon offers filters for over 90 different content types (e.g. books, journal articles, newspaper articles). Examples of other filter types are filters to restrict the results to particular publication date ranges, or to documents indexed with particular subject terms. Over 40% of queries use at least one filter, and a little over a third of sessions start with a query using at least one filter. We know that some of our clients set the default search to include one or more filters, so not all the filters are applied directly by the end user. The most commonly used category of filters is ContentType, with Full Text and Limit to Scholarly Publications being the next-most common filters.
We are using this information to improve our UI and our default settings, to ensure that our users have the best search experience.
4.2.4 Query length and Abandonment
We also investigated the relationship between query length (the number of terms in the query) and query abandonment. As shown in Figure 5, users are much more likely to abandon queries after issuing a short query. Short queries are often vague, not fully representing the real information need of the user, and such queries often return many results that may or may not be useful. While very unusual words may result in fairly specific and useful results, we see that some of our most common queries are single words, such as leadership, psychology, or marketing. Suggestions for related queries can help a user specify in more detail what aspect of a topic is of interest.
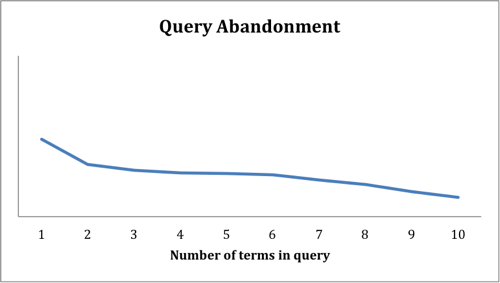 Figure 5. Query Abandonment as a function of the number of terms in the query
Figure 5. Query Abandonment as a function of the number of terms in the query
Sessions that begin with short queries are also more likely to end in abandonment than sessions that begin with longer queries. Figure 6 shows session abandonment for sessions beginning with queries of various lengths. Unlike query abandonment, which continues to decline as queries get longer, session abandonment rates are fairly stable if the first query consists of four or more terms. As in Figure 4, we have omitted the scale from Figures 5 and 6, but because the Y-axis crosses the X-axis at zero, the relative size of the difference in abandonment rates with change in number of search terms is evident.
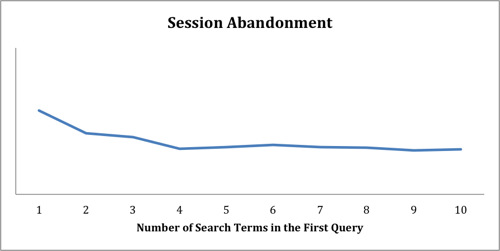 Figure 6. Session Abandonment as a function of the number of terms in the first query of the session
Figure 6. Session Abandonment as a function of the number of terms in the first query of the session
In addition to the information discussed above, we know that a significant proportion of our queries are three words or less in length. To further improve the experience for shorter queries, the Summon® service will be introducing a Topic Explorer pane along with a redesigned user interface in June 2013. The Topic Explorer identifies relevant topics from over 50,000 encyclopedia entries, guides users through the research process and exposes them to pertinent reference content in context of their query. The Summon® Topic Explorer pane also provides recommendations to relevant research guides and subject librarians. Figure 7 provides a screenshot of an early prototype of the redesigned Summon user interface with the topic pane.
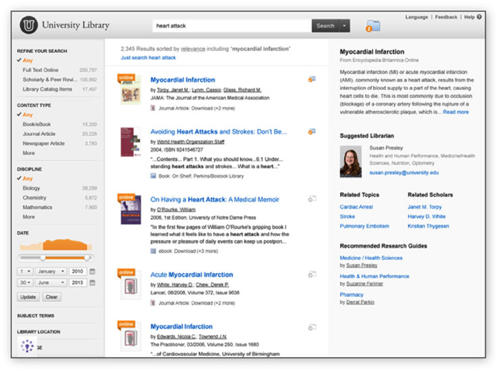 Figure 7. The redesigned Summon® User Interface with Topic Pane
Figure 7. The redesigned Summon® User Interface with Topic Pane
5. Improving RMF
The last section identified many uses of the RMF. There is still work to be done to improve the system. Specifically, we have faced challenges in two main categories: data quality and the implications of simplifying assumptions on data interpretation.
5.1. Data Quality
We log data from all queries submitted to Summon®, but not all data represents real user queries, and not all user queries are of equal interest. Some queries are submitted automatically to monitor connectivity. For example, if we examine the logs and see that the same query is submitted to the same library client four times an hour, day after day, we can surmise that the query is being used to monitor connectivity and does not represent a library user’s information need.
Occasionally we see evidence of what appears to be a hacking attempt. For example, the following does not look like a legitimate user query: ..%2F..%2F..%2F..%2F..%2F8Ud0y%2F..%2F..%2F..%2F..%2F..%2Fboot.ini%00.htm. Further analysis revealed that the session in which that query occurred contained 5906 queries, almost all of which contained the pattern 8Ud0y and many contained path symbols, such as ../. Another interesting pattern was a set of sessions over a few days that each consisted of over a thousand queries where each query consisted of title: <title of a document> and was probably generated by a script.
We have also identified attempts to scrape our content by issuing thousands of queries. Such scraping, if left uncaught, reduces the utility of the RMF.
Our main concern about such data quality issues is that they could distort the relevance metrics and lead to unwarranted conclusions about user behavior. For example, thousands of monitoring queries, none of which result in clicks, could skew our abandonment rate upward. A robot that clicks on every search result could skew our metrics such that our relevance appears better than it really is. Exhaustively identifying all bad, or suspicious, data is tedious and error prone. Once we identify the undesirable data, we have several choices for dealing with it. We could filter out suspect queries, but that will only be successful to the extent that we can proactively identify them. We know our success would only be partial and we would risk filtering out legitimate user query data. Alternatively, we could ignore the problem and hope that it is a small enough fraction of the data such that the effects on metrics are negligible. We could also retrospectively identify problem queries and sessions and tag them, so that we don’t lose data but we can omit the problematic data from our analyses.
We take a pragmatic approach that is a combination of the options described. We filter out certain queries early in the data processing pipeline. Retrospectively, we examine various data characteristics to identify other “suspicious” queries. We tag such queries and sessions in the database that we believe do not represent real user queries or that represent query “spam.” We can then filter such data with our database queries. It will not be possible to identify all such queries and sessions, and clearly, time spent finding and tagging them has diminishing returns. We try to identify the most impactful instances and assume that the instances not found represent a small fraction of the untagged queries. For the data from 2012, we tagged less than three quarters of one percent of sessions and about a quarter of one percent of queries as “suspect.”
5.2. The Implications of Simplifying Assumptions
Conceptually, a query session represents the activity of a single user pursuing information related to a single information need. Practically, we do not have enough information to segment a stream of queries into sessions accurately, and so our sessions are only approximate. In a public place, such as a library, multiple users may send queries from the same machine and browser. So a session could represent queries from multiple users. Again, a single user may search for information about multiple topics, and we do not try to analyze the content of searches to identify changes in topic. Instead, we take a very pragmatic approach to try to associate the queries one user might issue in a coherent searching session and place boundaries to ensure that sessions do not become overly long.
If each user were to tell us which documents we return are relevant to his query, we could accurately measure the relevance of our search results. In practice, of course, we do not get feedback with that degree of detail. We use clicks as a proxy for relevance, recognizing that users often click on documents and find that they are not relevant. In addition, relevant documents may be returned in the results set, even on the first page, that are never clicked. Finally, users’ information needs may sometimes be sated with information in the snippet that is returned with the result, so that the user does not have to click on any result. We think of clicks as providing an upper bound on relevance and believe that, over a large number of queries, the proportion of truly relevant documents among all documents that are clicked is relatively stable so that trends in click data are meaningful over time.
As we work with this data, we hope to come up with algorithms and approaches to improving components such as our session identification and relevance identification. For now, we have to be careful to understand that any conclusions we make must be considered in the context of the assumptions we have made.
6. Conclusions
In summary, we developed the Relevance Metrics Framework for capturing, processing, and analyzing query and click log data. The RMF enables us to understand how Summon is being used and monitor the quality of our search results. It provides a data source to enable various tools that can improve the user experience and serves as a source of insight and ideas for future product enhancements. We have provided a sample of information and insights that we have garnered from the RMF and listed some ways we are already using the data, such as the autocomplete feature and the Topic Explorer, which exemplify the data-driven product design that we have been practicing. We hope that as we explore the data in RMF further, we will be able to continually improve our systems to directly benefit all our customers and users.
References
Dialog, LLC. [Internet]. ProQuest; [cited May 15, 2013]. Available from: http://www.dialog.com.
The Summon® Service. [Internet]. ProQuest: [cited May 15, 2013]. Available from http://www.serialssolutions.com/en/services/summon/.
Cleverdon C., 1967. The Cranfield tests on index language devices. Aslib Proceedings, 19, pp. 173-192, Reprinted in Jones K and Willett P, Editors. 1997. Readings in Information Retrieval. Morgan Kaufmann Publishers, Inc., San Francisco, CA, pp. 47-59.
National Institute of Standards and Technology (NIST). Text REtrieval Conference (TREC) Home Page. (Cited May 15, 2013). http: //trec.nist.gov/.
Brin S, Page L., 1998. The anatomy of a large-scale hypertextual web search engine. In: Proceedings of the Seventh International Conference on World Wide Web 7, pp. 107-117, Brisbane, Australia.
Ingwersen P, Järvelin, K., 2005. The Turn: Integration of Information Seeking and Retrieval in Context. Dordrecht, The Netherlands: Springer
Salton G, McGill M., 1986. Introduction to Modern Information Retrieval. McGraw-Hill, Inc., New York, NY, USA.
Manning C, Raghavan P, Schütze H., 2008. Introduction to Information Retrieval. Cambridge University Press, New York, NY, USA.
Jansen B, Spink A, Saracevic T., 2000. Real life, real users, and real needs: a study and analysis of user queries on the web. Information Processing and Management 36: 207-227.
Jansen B, Spink A. 2006., How are we searching the World Wide Web? A comparison of nine search engine transaction logs. Information Processing and Management 42: 248–263.
Kamvar M, Kellar M, Patel R, Xu Y. 2009., Computers and iPhones and Mobile Phones, oh my! A logs-based comparison of search users on different devices. WWW 2009, April 20-24, 2009, Madrid, Spain.
Järvelin K, Kekäläinen J. 2000., IR evaluation methods for retrieving highly relevant documents. In Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR ’00). ACM, New York, NY, USA, 41-48.
Järvelin K, Kekäläinen J. 2002., Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 20, 4 (October 2002), 422-446.
About the Authors
Ted Diamond (Ted.Diamond@serialssolutions.com) is a Senior Developer on the Summon development team at SerialsSolutions. He designed and created the first version of the Relevance Metrics Framework and has led the development of the new Topic Explorer feature in Summon.
Susan Price (Susan.Price@serialssolutions.com) is a Search Analyst on the Summon development team at SerialsSolutions where she works on collecting, analyzing, and using data to improve the Summon experience. Susan’s research for her Ph.D. in computer science entailed creating and evaluating a model for improving the relevance of search results in domain-specific document collections.
Raman Chandrasekar (Raman.Chandrasekar@serialssolutions.com) is the Software Architect Lead for the Summon development team at SerialsSolutions. Chandra has spent many years researching and working on web search systems, including work on relevance on an early version of Bing, and on query-log analysis, domain-specific search and human computation as a researcher at Microsoft Research.
Appendix A: Calculating Discounted Cumulative Gain (DCG)
A typical formula for calculating Discounted Cumulative Gain (DCG) for a set of search results (Järvelin & Kekäläinen, 2000; Järvelin & Kekäläinen 2002) is:
DCGp = r1 + ?j=2..p(rj/log2(j))
Here DCGp is the discounted gain cumulated to rank p. rj is the relevance of the result at rank j. This formula sums up the discounted gains for the relevance at all result positions, where the discount at position 1 is 1, and at other positions is (1/ log(j)).
To compute DCG, we need to know for each result, whether is it relevant or not. If we use a binary scale, we can score relevance as 1 if the document is clicked, and otherwise 0. Alternatively we could use a graded (Likert) scale corresponding to relevance levels such as not relevant, slightly relevant, fairly relevant, and highly relevant. In this case, we could use scores ranging from 0 to 3 for not relevant to highly relevant. Since we are using clicks as a proxy for relevance judgments, our relevance values are binary.
|
Search A |
|||
|
Document Rank (j) |
Relevance (relj) |
Discounted Gain (relj/log2(j)) |
Cumulated Gain |
| 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 |
| 3 | 1 | 0.63 | 0.63 |
| 4 | 0 | 0 | 0.63 |
| 5 | 1 | 0.43 | 1.06 |
| 6 | 1 | 0.39 | 1.45 |
|
Search B |
|||
|
Document Rank (j) |
Relevance (relj) |
Discounted Gain (relj/log2(j)) |
Cumulated Gain |
| 1 | 1 | 1 | 1 |
| 2 | 0 | 0 | 1 |
| 3 | 0 | 0 | 1 |
| 4 | 1 | 0.5 | 1.5 |
| 5 | 0 | 0 | 1.5 |
| 6 | 0 | 0 | 1.5 |
Figure A1. DCG for Search A and Search B
To illustrate DCG, we provide a simple example in Figure A1. Suppose a user performs two searches that we will call search A and search B. For search A, the user enters a query and clicks on documents at ranks 3, 5, and 6. The gain at rank 3 is 1, but the discount is 1/log2(3), which is 0.63. Similarly we calculate the discounted gain at each rank and keep a running total to get the DCG for search A at rank 6 as 1.45 . For search B, the user clicks on documents at ranks 1 and 4. The DCG for search B is 1.5.

Subscribe to comments: For this article | For all articles
Leave a Reply