by Timothy A. Thompson, James Little, David González, Andrew Darby, and Matt Carruthers
Introduction
In recent years, with the emergence of the GLAM-Wiki initiative (galleries, libraries, archives, and museums with Wikipedia) [1], cultural heritage institutions have begun to share their resources and expertise with the global audience of Wikipedia. Data are already beginning to show that GLAM-Wiki collaboration is making information more accessible to researchers (Szajewski 2013). One particular focus of GLAM-Wiki collaboration has developed around authority control, an area that has been an important part of the traditional role of libraries. Authority control is essentially the process of establishing and maintaining lists of official (“authorized”) and alternative names for different entities in order to uniquely identify them. In recent years, this process has been greatly enhanced by the pairing of name strings with URIs.
Tools like OCLC’s VIAFbot [2] have helped integrate library authority data into Wikipedia (at web scale) by automatically adding over 250,000 reciprocal links from the Virtual International Authority File (VIAF) [3]. As these initiatives progress, however, there is also a need for GLAM-Wiki projects that balance robust data-sharing with the curatorial attention to detail that has been another traditional strength of the cultural heritage sector.
Whereas libraries have typically focused on maintaining name authority files, the archives community has produced a body of detailed biographical descriptions that help provide access to the broader archival context. In an effort to help archivists disseminate the information they have compiled about the people and organizations whose documents they preserve, a team of librarians and programmers at the University of Miami Libraries has developed the Remixing Archival Metadata Project (RAMP).
RAMP is a lightweight web-based metadata tool that lets users generate enhanced archival authority records and gives them the ability to publish the content of those records as Wikipedia pages. The RAMP editor first extracts biographical and historical data from archival finding aids to create new authority records for persons, corporate bodies, and families associated with archival and special collections. It then lets users enhance those records with additional data from sources like VIAF and WorldCat Identities [4]. Finally, it transforms those records into wiki markup for direct publication to Wikipedia through its API.
Background
For decades, archivists have devoted considerable effort to describing the collections they curate and creating finding aids to help users navigate through their content. The Encoded Archival Description (EAD) standard was created to store and present this information online in machine-readable format. EAD, in combination with the More Product, Less Process (MPLP) methodology (Greene and Meissner 2005), has enabled many more finding aids to be made accessible online, greatly increasing the availability of collections and information for researchers around the world.
These archival collections, however, do not exist in a vacuum. Understanding the circumstances surrounding the creation of a collection and its contents can help researchers gain important knowledge about the primary sources they are studying. The EAC-CPF (Encoded Archival Context–Corporate Bodies, Persons, and Families) metadata standard was designed to aggregate contextual information about collection creators and provide a unified access point for associated archival materials (Wisser 2011). EAC-CPF is a relatively new standard, endorsed by the Society of American Archivists in 2011. The EAC-CPF user community is growing steadily, spurred on by projects such as Social Networks and Archival Context (SNAC), an initiative of the National Archival Authorities Cooperative (NAAC) [5], and “Connecting the Dots: Using EAC-CPF to Reunite Samuel Johnson and His Circle,” a collaboration between Yale University Libraries and Harvard University Libraries [6].
<?xml version="1.0" encoding="UTF-8"?>
<eac-cpf
xmlns="urn:isbn:1-931666-33-4"
xmlns:ead="urn:isbn:1-931666-22-9"
xmlns:xlink="http://www.w3.org/1999/xlink">
<control>
<recordId>RAMP-27-48-102</recordId>
<otherRecordId localType="UML">CHC0339.48.r27</otherRecordId>
<otherRecordId localType="WCI:DBpedia">http://dbpedia.org/resource/Lydia_Cabrera</otherRecordId>
<otherRecordId localType="WCI:LCCN">lccn-n80-98243</otherRecordId>
<otherRecordId localType="WCI:VIAF">79081464</otherRecordId>
<maintenanceStatus>derived</maintenanceStatus>
<publicationStatus>inProcess</publicationStatus>
<maintenanceAgency>
<agencyCode>FMU-N</agencyCode>
<otherAgencyCode localType="OCLC">FQC</otherAgencyCode>
<agencyName>University of Miami Libraries</agencyName>
</maintenanceAgency>
<languageDeclaration>
<language languageCode="eng">English</language>
<script scriptCode="Latn">Latin</script>
</languageDeclaration>
<maintenanceHistory>
<maintenanceEvent>
<eventType>derived</eventType>
<eventDateTime standardDateTime="2013-10-11"/>
<agentType>machine</agentType>
<agent>XSLT ead2eac.xsl/libxslt</agent>
<eventDescription>New EAC-CPF record derived from EAD instance and existing EAC-CPF record.</eventDescription>
</maintenanceEvent>
</maintenanceHistory>
<sources>
<source xlink:type="simple" xlink:href="http://proust.library.miami.edu/findingaids/index.php?p=collections/findingaid&id=48">
<sourceEntry>Guide to the Lydia Cabrera Papers</sourceEntry>
</source>
<source xlink:href="http://worldcat.org/identities/lccn-n80-98243/identity.xml" xlink:type="simple"/>
<source xlink:href="http://viaf.org/viaf/79081464" xlink:type="simple"/>
</sources>
</control>
<cpfDescription>
<identity>
<entityType>person</entityType>
<nameEntry>
<part>Cabrera, Lydia</part>
<authorizedForm>lcnaf</authorizedForm>
</nameEntry>
</identity>
<description>
<languagesUsed>
<languageUsed>
<language languageCode="spa">Spanish;Castilian</language>
<script scriptCode="Latn">Latin</script>
</languageUsed>
</languagesUsed>
<localDescription localType="650">
<term xml:id="fst00821914" xmlns:xml="http://www.w3.org/XML/1998/namespace">Authors, Cuban</term>
</localDescription>
<biogHist>
<abstract>The Lydia Cabrera Papers contain the personal and research papers of 20th century Cuban anthropologist, writer, and artist, Lydia Cabrera.</abstract>
</biogHist>
</description>
<relations>
<cpfRelation xlink:arcrole="associatedWith" xlink:href="http://id.loc.gov/authorities/names/n78095648" xlink:role="http://rdvocab.info/uri/schema/FRBRentitiesRDA/Person" xlink:type="simple">
<relationEntry localType="editor">Hiriart, Rosario</relationEntry>
</cpfRelation>
<resourceRelation resourceRelationType="creatorOf" xlink:href="http://proust.library.miami.edu/findingaids/index.php?p=collections/findingaid&amp;id=48" xlink:role="archivalRecords" xlink:type="simple">
<relationEntry>Lydia Cabrera Papers, 1910-1991</relationEntry>
</resourceRelation>
<resourceRelation resourceRelationType="creatorOf" xlink:href="http://merrick.library.miami.edu/cubanHeritage/chc0339/" xlink:role="archivalRecords" xlink:type="simple">
<relationEntry>Lydia Cabrera Papers (Digital Collection)</relationEntry>
</resourceRelation>
</relations>
</cpfDescription>
</eac-cpf>
Figure 1. Sample XML illustrating the basic structure of an EAC-CPF record.
EAC-CPF contains both administrative and descriptive information, intended to allow for the management of the record as well as the description of the entity the record is about. The administrative portion of the record is located within the
The descriptive portion of EAC-CPF is broken down into three main components: <identity>, <description>, and <relations>. The <identity> portion is concerned with uniquely identifying the entity being described. The
The real power of EAC-CPF comes in its <relations> section, which provides the ability to associate the entity being described with other entities or resources. These links help create a web of contextual information that could potentially have a substantial benefit for researchers. Currently, it can be very difficult to locate all archival resources related to an individual or entity, especially if collections are geographically dispersed or held by different institutions. There is not yet a central authority file or database for the creators of archival collections that could link out to all of these related resources. With EAC-CPF and national initiatives like NAAC, the archival community is now beginning to encode this authoritative information.
As with any new metadata standard, there are barriers to implementing EAC-CPF within the archival community. Full EAC-CPF records can potentially contain hundreds or thousands of lines of description, making the manual creation of records very time consuming. Often, research must be performed to collect enough information about the entity being described to create a full EAC-CPF record. Another issue arises with the dissemination of the information contained within the records. There are not currently many avenues for publishing this information or making it available to users, outside of prototype systems such as SNAC’s customized XTF platform.
Development Process and Technology
RAMP brought together curators, programmers, and cataloging and metadata librarians, each of whom had a unique perspective on the project and its goals. Finding aid data was initially drawn from two repositories: the University of Miami Libraries’ Special Collections [7] and its Cuban Heritage Collection [8]. Curators from these collections were the project’s primary stakeholders. The development process itself was guided by the agile Scrum methodology [9]. Over the course of three two-week sprints, team members adopted the various Scrum roles: the “product owner” (played by Matt Carruthers, Metadata Librarian) gathered user stories about the desired functionality and clarified these stories for the developers; the “scrum master” (played by Andrew Darby, Head of Web & Emerging Technologies) facilitated the process; and the three developers (played by David González, Digital Programmer; Jamie Little, Digital Programmer; and Tim Thompson, Metadata Librarian) broke the user stories down into programming tasks and got to work.
The development team began each sprint day with a 10–15 minute stand-up meeting to outline the previous day’s accomplishments and set goals for the coming day. At the end of each two-week sprint, colleagues and stakeholders were invited to see a demo of the functional (but incomplete) application.
One of the goals of RAMP was to make the software accessible to other institutions. With this in mind, the project utilizes the common LAMP stack. On the back end, PHP is used to facilitate XSLT transformations, XML validation, and database access. Much of this functionality is exposed as lightweight services that can be accessed with JavaScript. Client-side, jQuery is used to communicate with those services.
Project Workflow
In the RAMP workflow, data passes through three stages: first, EAD-encoded archival finding aids are ingested into the system and biographical data is extracted to produce authority records for collection creators. This initial step utilizes two XML metadata formats: EAD for finding aids and EAC-CPF for authority records. Second, users select individual records for editing. At this stage, the RAMP tool can do basic named entity recognition and pull in data from external sources like VIAF and WorldCat Identities. The user is presented with a list of potential matches and can select which ones to add to the EAC-CPF record to create relation elements. Third, a relevant subset of the enhanced EAC record is transformed into wiki markup. The tool can then check to see if there is an existing Wikipedia page for a given person or organization. If there is no entry, a stub page is created containing custom Wikipedia metadata, the entity’s VIAF ID (if available), a biography, and sections for references, works by, and external links back to the local finding aid and any associated digital collections. If there is already an entry, that wiki markup is pulled in for potential integration and presented alongside the locally created markup. Finally, RAMP allows users to publish this new or updated entry directly to Wikipedia with the push of a button.
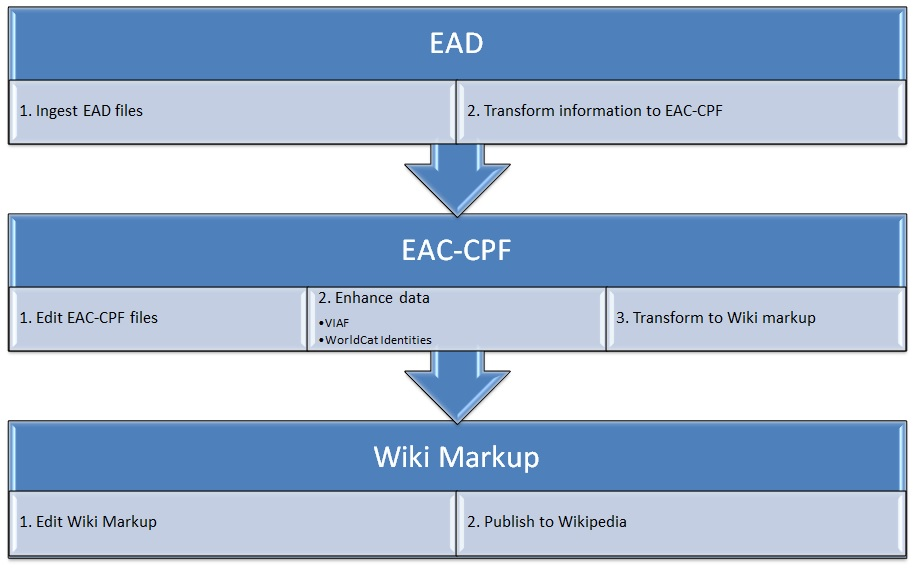
Figure 2. Process diagram of RAMP workflow. (Click to enlarge)
Data Transformations
EAD to EAC-CPF
The availability of archival management systems like Archon, Archivists’ Toolkit, and now ArchivesSpace has facilitated the processing and description of archival and special collections. Our current local system, Archon, contains separate modules for creating both finding aids for archival collections and authority records for creators. Archon also includes a batch export utility that outputs EAD/XML records for finding aids and basic EAC-CPF/XML records for creators.
RAMP uses XSLT 1.0 stylesheets to transform EAD records into EAC-CPF records and then EAC-CPF records into Wikipedia markup. Preliminary stylesheets created in the early stages of the project had been written in XSLT 2.0, but the continued absence of any XSLT 2.0 transformation engine that does not require Java meant that these stylesheets needed to be rewritten. One of the benefits of using external XSLT 1.0 stylesheets is that a large portion of the core functionality of RAMP can be repurposed using other programming languages that support XSLT, or through workflows based on desktop XML editors.
An effort was made to create stylesheets that were as generalizable as possible. For example, several global parameters were created to allow users to specify local data in an external configurations file (conf/inst_info.php). When the transformation is called, the values for these parameters are passed into the stylesheet from PHP. Notwithstanding, the potential for interoperability is somewhat limited by the idiosyncrasies of individual archival management systems like Archon and the way they format EAD and EAC-CPF records on export. For example, although the EAD metadata standard includes elements for encoding chronologies and references to related material, Archon does not support this level of structured markup in its data entry interface. When finding aids did include chronologies or related reference sections, this data was often marked up in simple <p> or <emph> tags. Markup limitations were compounded by inconsistencies in the way data had been entered over time. The EAD-to-EAC stylesheet tries to parse out as much relevant information as possible, but this code would most likely need to be adapted to work with markup from other institutions.
The need to account for one-to-many relationships between creators and collections, and vice versa, also presents a major challenge for data transformation. At present, RAMP’s file import routine generates a single EAC-CPF record for each EAD finding aid. In the future, this process will need to be improved to enable information from related finding aids and any existing creator records to be merged into a single EAC-CPF instance. Much of the work for merging multiple EADs into EAC-CPF records has already been accomplished by the SNAC project, and its code, soon to be publically released, may help resolve this issue. As a temporary workaround, a shell script and XSLT 2.0 stylesheet were developed to merge our local EAD and EAC-CPF files as part of a separate preprocessing stage prior to import into RAMP.
EAC-CPF to Wiki Markup
By comparison, the transformation from EAC-CPF to Wikipedia markup (an intermixture of a unique plain text format and HTML tags) presented fewer challenges. Wiki markup is meant to be an abstraction from HTML that allows for easier editing of Wikipedia articles. At first glance, Wikipedia’s markup has a simple syntax, but in practice Wikipedia articles rely on a multitude of templates that can be quite complex.
One of the goals of RAMP was to include an Infobox for each person or organization (at present, RAMP’s EAC-to-Wikipedia stylesheet does not transform records for families). Infoboxes are essentially metadata about an entity that is displayed as a sidebar on the public page, and they contain dozens of associated properties [10]. The stylesheet outputs a subset of Infobox properties that a user can fill in manually, and it also attempts to extract basic information from the EAC record to pre-populate certain Infobox fields such as those for birth and death dates. Whereas Infoboxes are intended for display, Wikipedia pages contain an additional metadata template called Persondata, which includes a limited set of properties and is used only for machine processing [11]. RAMP’s EAC-to-Wikipedia stylesheet employs the same methods used in creating Infoboxes to output and attempt to pre-populate Persondata templates.
For other data, top-level sections are created according to the following basic crosswalk:
| EAC-CPF tag name / XPath | Wiki markup section / template |
| biogHist/p | Biography (persons) / History (organizations) |
| chronList/chronItem | Chronology |
| localDescription/term[@localType=’6xx’] | Category |
| resourceRelation[@resourceRelationType=’creatorOf’ and @xlink:role=’resource’]/relationEntry | Works or publications |
| cpfRelation/relationEntry | See also |
| sources/source[1]/sourceEntry | Notes and references |
| resourceRelation[@resourceRelationType=’subjectOf’ and @xlink:role=’resource’]/relationEntry | Further reading |
| resourceRelation[@xlink:role=’archivalRecords’]/relationEntry | External links |
|
sources/source/@xlink:href[contains(.,’viaf’)] otherRecordId[@localType=’WCI:LCCN’] |
Authority control |
Figure 3. Basic EAC-CPF-to-Wikipedia crosswalk.
Inline XML Editor
RAMP utilizes the open source Ace Editor [12] for editing XML records. The Cloud9 online IDE [13], GitHub [14], and the UNC Libraries [15] are currently using this editor. The editor is written in JavaScript and includes many features, such as syntax highlighting, that users of desktop XML editors would expect. In addition to the editor, RAMP includes a validation service that checks to see whether the XML being edited is well formed and valid as the user edits the XML. If the XML is valid and well formed, a green icon is displayed. If the XML contains errors, the validation service returns specific error information.
The XML records edited in RAMP are not stored on the file system, but in a database. Although RAMP may seem like the ideal project to utilize an XML database, it uses MySQL because of its ubiquity and XML capabilities. Individual EAD and EAC-CPF records are stored in the database along with basic metadata about the file. MySQL versions beginning with 5.1 allow queries to contain XPath statements, and this functionality is utilized by RAMP to extract names for display. In future iterations of RAMP, it may be possible to extract more information directly from XML stored in the database.
Diff Functionality
RAMP incorporates PHP Diff [16], a library that displays differences between text, and jQuery Merge for PHP Diff [17], a JavaScript-based library that lets users perform a merge based on the differences generated by PHP Diff. This functionality was included to cover situations where users may need to incorporate changes or updates made to local EAD records. During RAMP’s import process a user will be presented with a merging interface for files that have changed:
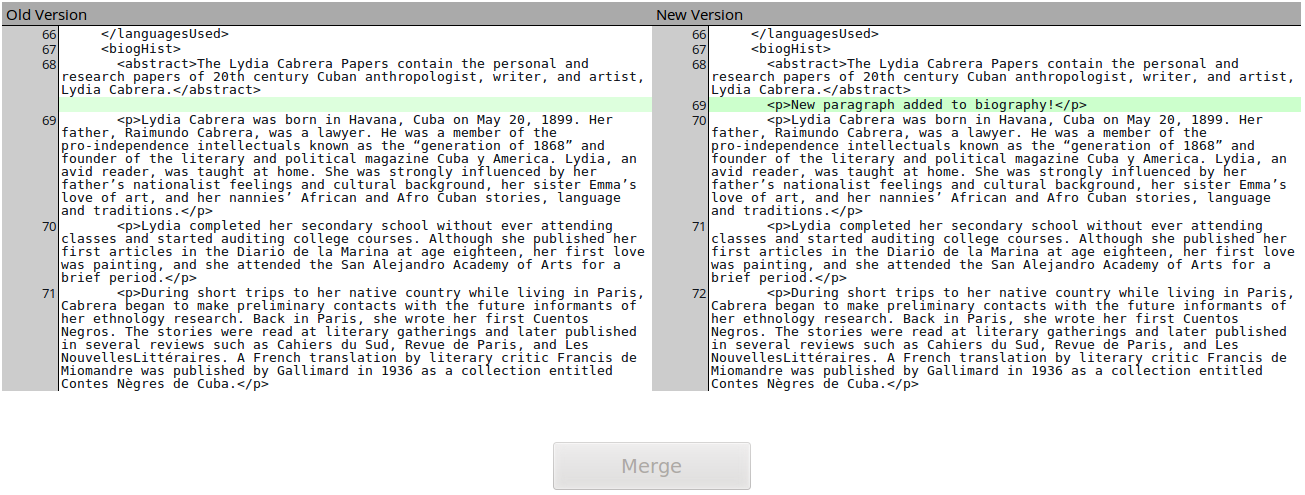
Figure 4. Diff functionality in the RAMP import interface. (Click to enlarge)
API Lookups
RAMP currently uses the VIAF [18] and WorldCat Identities [19] APIs to ingest new information into the EAC-CPF record. RAMP’s API functionality was designed to be extensible, and other data sources, like GeoNames.org, may be incorporated in the future. RAMP uses the PHP cURL [20] library to connect and communicate with these APIs, and XML DOM [21] to manipulate all XML it encounters. Data from VIAF lets RAMP create new <nameEntry> (with authorized and alternative forms of names) and relation elements, and data from WorldCat Identities provides associated subject headings, works by and about an entity, and data about relations to other entities. With these data sources, RAMP can ingest a considerable amount of information about an entity to enhance the EAC-CPF record. Most importantly, it provides an easy method for harvesting URIs, which can be leveraged in future linked data applications. Although the task of assigning VIAF IDs to Wikipedia articles is already being ably handled by the VIAFbot, RAMP provides a mechanism for ensuring that this data is stored and associated with records for locally held resources.
RAMP automates and centralizes the process of integrating data from a VIAF or WorldCat Identities record. It first uses the APIs’ search query to provide the user with a list of search results, with links to the record for each result. From this list, the user can choose the appropriate record to ingest. After the user chooses the desired result, RAMP queries the API again to retrieve the actual record and then parses the response to collect the desired data (for example, the VIAF ID from a VIAF record and associated subjects from WorldCat Identities). Once this data has been collected, it needs to be converted into objects that can be easily mapped to DOM elements in order to facilitate ingest into XML. The following snippet of data from WorldCat Identities illustrates how these objects are structured (JSON formatted) and represented in XML:
{
"cpfRelation": [
{
"attributes": {
"xlink:arcrole": "associatedWith",
"xlink:href": "http://id.loc.gov/authorities/names/n78095648",
"xlink:role": "http://RDVocab.info/uri/schema/FRBRentitiesRDA/Person",
"xlink:type": "simple"
},
"elements": {
"relationEntry": {
"attributes": {
},
"elements": "Hiriart, Rosario"
}
}
}
]
}
Figure 5. WorldCat Identities sample object as JSON.
<cpfRelation xlink:arcrole="associatedWith"
xlink:href="http://id.loc.gov/authorities/names/n78095648"
xlink:role="http://RDVocab.info/uri/schema/FRBRentitiesRDA/Person"
xlink:type="simple">
<relationEntry>Hiriart, Rosario</relationEntry>
</cpfRelation>
Figure 6. WorldCat Identities sample object as XML.
This data mapping allows for an easy transition from objects (either PHP or JavaScript) to DOM elements. After conversion into objects occurs, RAMP then prompts the user with a list of elements so that he or she can choose which ones should actually be inserted into the EAC-CPF record.
Before generating <nameEntry> elements using the VIAF API, RAMP also attempts to extract other named entities from the local file, prompting the user with a list of possible matches. Currently, this extraction is performed by applying a regular expression to the text of selected fields in the EAC-CPF record (<biogHist> and <resourceRelation>) and in the original EAD record (<unittitle>), which is now stored in the database. Matching strings are output and presented to the user for selection (see Figure 7).
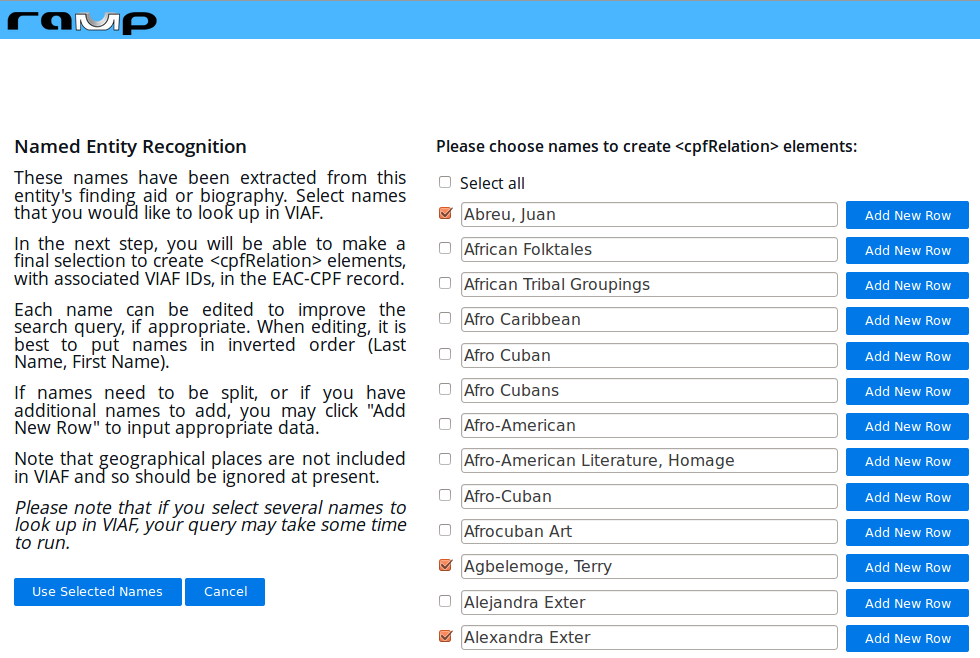
Figure 7. Partial results of RAMP named entity recognition for the Lydia Cabrera Papers. (Click to enlarge)
Once appropriate matches have been chosen, a subsequent lookup is triggered and, if there are potential matches in VIAF, new results are presented for final selection (Figure 8). To help users determine whether a result from VIAF is an appropriate match, links to the corresponding VIAF pages are provided, preceded by the original matching string. Selected results are then inserted into the EAC-CPF record as <cpfRelation> elements that store the value of the VIAF ID in an @xlink:href attribute.
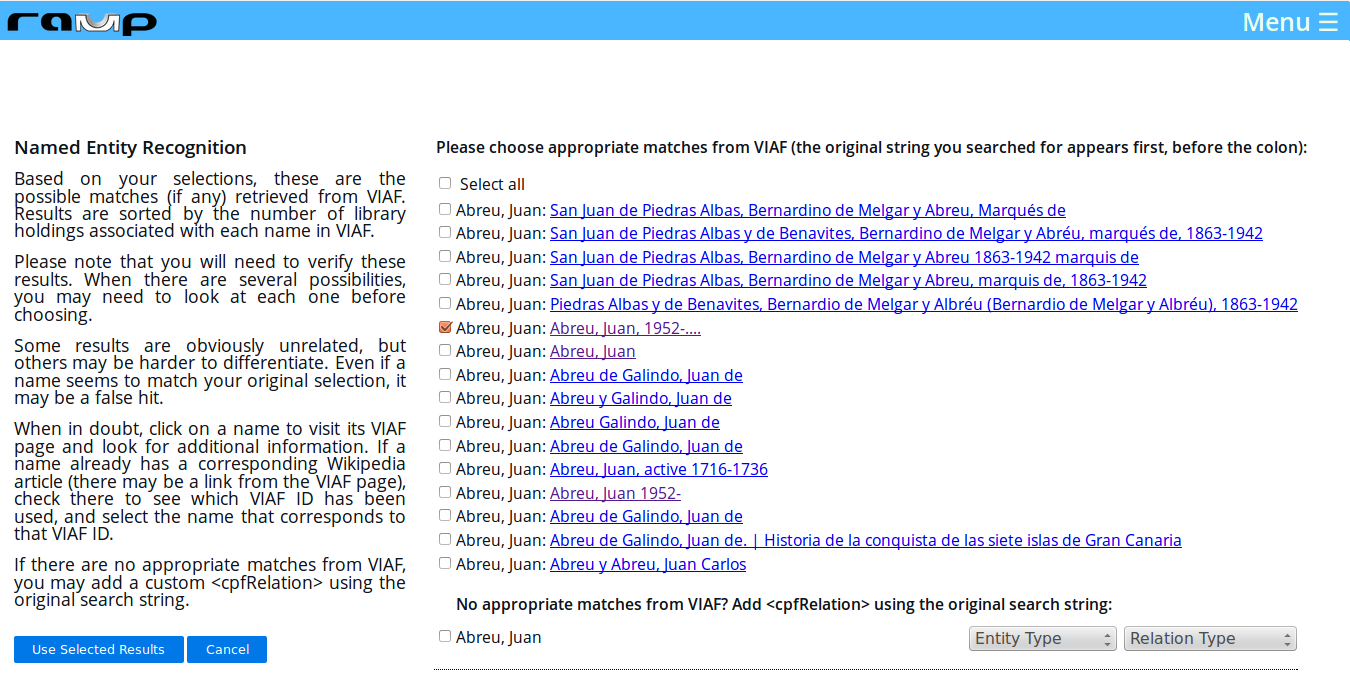
Figure 8. Results of VIAF lookup of named entities in the Lydia Cabrera Papers. (Click to enlarge)
This method does have its shortcomings: it retrieves a relatively high number of false hits and does not catch name variations that do not match the pattern, which is based on sequences of capital letters (so “Lydia Cabrera” would count, but “lydia Cabrera” would not). It also requires users to verify the accuracy of the matches pulled in from VIAF.
Future integration of a named entity recognition program or API would greatly improve this functionality. Notwithstanding, the ability to extract relationships from unstructured text and match names to URIs is already a significant step toward tying local resources into the emerging Web of Data (van Hooland et al. 2013).
In-Tool Wiki Editing
RAMP’s wiki markup editing interface is shown below (Figure 9):
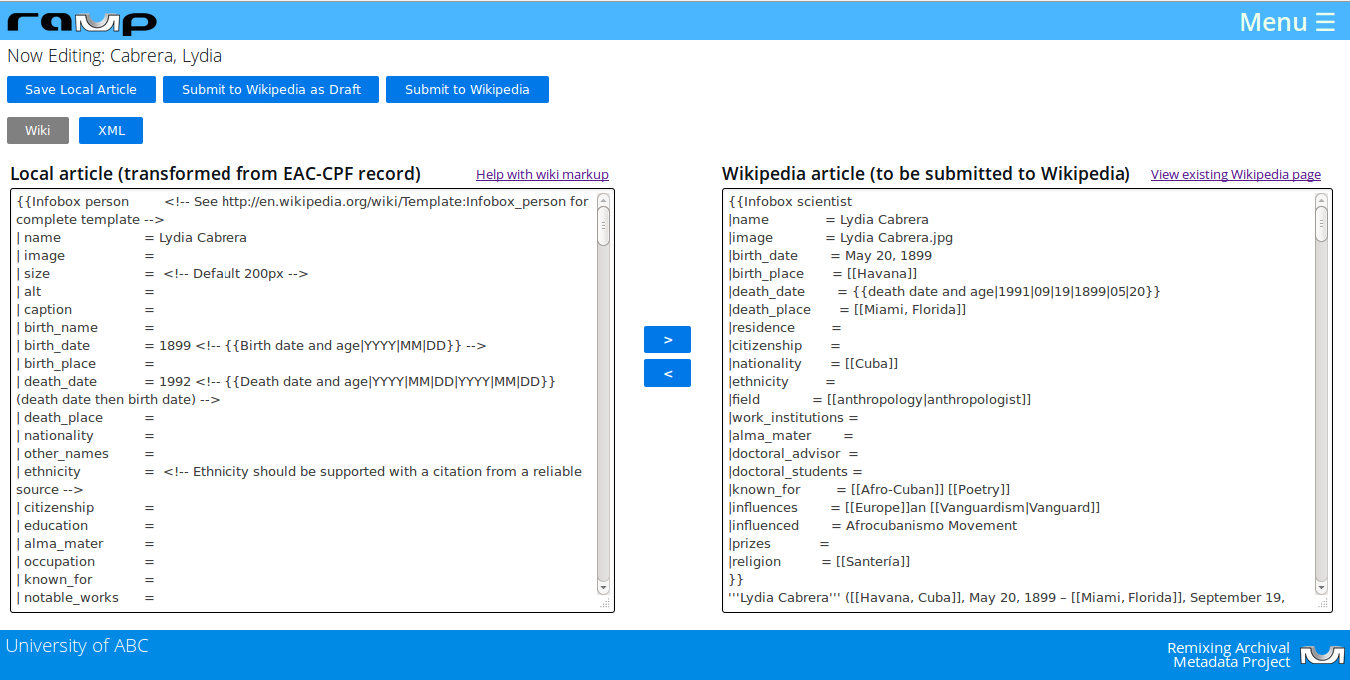
Figure 9. RAMP wiki editing interface. (Click to enlarge)
The text area on the left contains locally stored wiki markup, and the one on the right contains wiki markup that a user wants to post to Wikipedia, including any content from an existing Wikipedia page. The tool makes it easy to move content between text areas. Every time the user selects text from either text area, RAMP stores that text in memory; when the user wants to move the text to the other side, he or she need only actuate one of the arrows: “<” will move text to the focus of the left text area and “>” will do the opposite; the focus of each text area is stored by the browser, and RAMP uses that to move text between areas.
Interacting with the Wikipedia API
The Wikipedia API is both useful and versatile, allowing access to wiki features, data, and metadata. RAMP uses this API to log in, search pages, get pages, and edit pages on Wikipedia. To begin editing pages on Wikipedia, RAMP searches Wikipedia for existing pages that are relevant to the entity being described. After searching, it displays a list of results, with links, so the user can choose the desired page to edit. One problem encountered while implementing this portion of RAMP was that newly created pages are not indexed until the following day and do not appear in search results from Wikipedia’s API until then. Therefore, if a user creates a page for “Lydia Cabrera” and comes back to it later on the same day, the search results will not display the new page. A solution to this problem was to add, on top of Wikipedia’s search results, an exact match result. In the previous example, if the user searches for “Lydia Cabrera,” RAMP does a separate HTTP request to Wikipedia, constructing a Wikipedia URL with the search term as a page title. If the page exists, RAMP places that result above the search results from Wikipedia’s search API. Once a page has been selected for editing, RAMP queries Wikipedia again to get the wiki markup of the requested page and then displays it in the wiki editing interface shown in Figure 9.
RAMP also provides an option to create a new wiki page if none of the search results reflects the entity a user is writing about; in this case, an empty text area is displayed on the right. After the user enters or edits content in the right-hand text area, changes are then ready to be posted to Wikipedia. First, however, the user is prompted to log into his or her personal Wikipedia account from within the RAMP editing interface. Having users log into Wikipedia with a personal account helps ensure compliance with Wikipedia’s username policy, which prohibits institutional or shared accounts [22]. After a successful login, RAMP stores a cookie file with the user’s wiki session information for later requests, and the user can now post a new page or changes to an existing page to Wikipedia, along with comments. Some Wikipedia edits also require a CAPTCHA upon submission. If a CAPTCHA is needed, RAMP prompts the editor with the CAPTCHA image and a text box in order to get the solved CAPTCHA. It then tries the edit request again with new parameters, including the CAPTCHA ID and answer.
Finally, RAMP facilitates the editing process by letting users save Wikipedia-hosted drafts of their articles. For example, rather than editing and posting new content directly to http://en.wikipedia.org/wiki/Lydia_Cabrera, RAMP users can check a “Draft” box to save their work-in-progress to a subpage of their Wikipedia user homepage (like http://en.wikipedia.org/wiki/User:Timathom/Lydia_Cabrera). In the Wikipedia community, saving draft articles to user subpages is standard practice.
Preliminary Results
It is still too early to point to concrete evidence, but our preliminary experience using RAMP to create and edit Wikipedia pages has been very positive. To date, only a few live pages have been created using the tool. Minor edits or additions have also been made to a handful of existing pages. For each of us, RAMP represented our first foray into the world of Wikipedia editing. It has been especially interesting to note the speed with which Wikipedia users begin contributing to and improving newly created pages. For example, one of our first test pages was for a composer named Rodrigo Prats Llorens (see Figure 10). As the edit history for the page reveals, contributors began to edit this new entry quite quickly [23]. In the span of five days, three different Wikipedia users provided edits or enhancements, and the first edits came within six minutes of the page’s creation. These contributions suggest that users are viewing and adding to Wikipedia pages at an impressive rate, and they reaffirm that Wikipedia is a robust platform for information-sharing and collaboration. In future versions of RAMP, we hope to explore automated methods for incorporating these “crowd-sourced” enhancements back into local records.
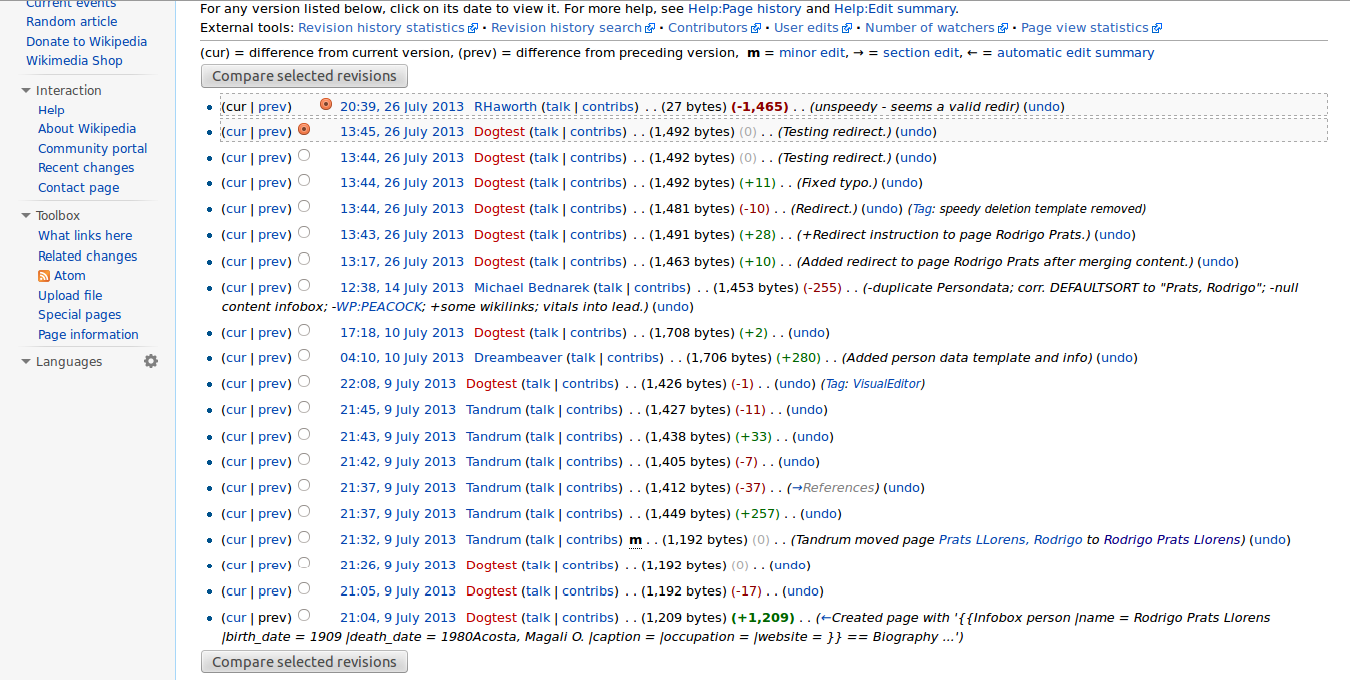
Figure 10. Wikipedia revision history for the RAMP-created page about the composer Rodrigo Prats Llorens. (Click to enlarge)
Lessons Learned
As with any collaborative project that involves multiple stakeholders, there were challenges that arose during the RAMP development process. Like Chaucer’s pilgrims [24], each participant involved in the project represented a socio-professional type, as it were: curators care deeply about the information they have worked to structure and provide; programmers are focused on problem solving and achieving specific results; and cataloging and metadata librarians are concerned with data conversion and the integrity of formats and standards. These different frames of reference made constant communication a necessity. The agile Scrum process provided a structured framework for facilitating communication on the development side, but it may also have made communication with stakeholders more difficult, since each sprint tended to create a kind of isolation zone around the project. Our experience reminded us that the demands of development should be balanced with the need to stay engaged, early and often, with stakeholders and interested parties, who may run the risk of feeling left out of the project management process. This balance was particularly hard to achieve during the initial sprint, before we had a working product to demonstrate. The end-of-sprint demos, however, gave stakeholders an opportunity to comment on a concrete thing rather than an idea of a thing. As a result, we received concrete and practical feedback, which we worked to incorporate into subsequent sprints.
There were also technical challenges during the development process. The original concept for manually editing EAC-CPF files in RAMP was to utilize a web form, mirroring the functionality of archival information management systems such as Archon, Archivist’s Toolkit, and ArchivesSpace. The advantage to this approach is that it limits the possibilities for user error, which may result in malformed XML or invalid EAC-CPF documents. The developers quickly encountered a number of challenges when trying to build the web form, however. EAC-CPF is designed to be a fairly flexible schema, allowing for things such as the description of multiple identities for a single entity (for example, Barack Obama the president and Barack Obama the law school lecturer). Building a web form to accommodate this would have consumed time and resources that needed to be devoted to other core functionality. Utilizing a web form for data entry in EAC-CPF files also effectively limits the user to a single application profile (which is a problem alluded to in the discussion of Archon’s XML export format, above). We decided instead to use the Ace Editor as the interface for editing EAC-CPF files. It proved to be a lightweight but powerful solution, allowing users full control over the structure of their EAC-CPF files. Although working directly in the XML can potentially place a greater burden on users, the validation service will alert them to any errors in the encoding.
Conclusion
Now that the core functionality of the RAMP editor is in place, we have begun to explore the possibilities for integrating it into local workflows. Because of the nature of the tool, an important part of adoption will involve establishing local guidelines and best practices for Wikipedia editing in general. One important issue to address before beginning to utilize the tool is that of copyright and permissions. Wikipedia provides two basic options for “donating” text for republication on its pages [25]. The first option is to include a permissions statement on the webpage of the local source of information, licensing it under a Creative Commons Attribution-Sharealike 3.0 Unported License (CC-BY-SA) and GNU Free Documentation License (GFDL). As an alternative, content contributors can also send an email to Wikipedia with a formal declaration of consent for each text to be republished [26].
Although there is a clear analogy between the structured content of an EAC-CPF record and that of a biographical Wikipedia entry, it is important to recognize that two different sets of conventions and expectations are at play. Whereas Wikipedia places a premium on rigorous citation of sources, this is not a practice that archival metadata standards have traditionally emphasized. When contributing biographical pages to Wikipedia through RAMP, it may be necessary to add references or check the sources of the local description (especially if it involves a living person) in order to bring it into line with the expectations of the Wikipedia community. As a ubiquitous, international platform, Wikipedia can provide users with new access points to libraries, archives, and special collections; at the same time, publishing archival metadata on Wikipedia can challenge librarians and archivists to evaluate the quality and accessibility of their own descriptive practice.
Moving forward, we hope that future development of the RAMP editor will be driven by feedback from users. We have carried out a round of usability testing with colleagues who have volunteered to test the tool, and based on initial usability feedback, we have been iteratively enhancing the RAMP user interface to make its editing workflow more intuitive. Usability testing has drawn our attention to the challenge, generally speaking, of working with data across domains and platforms. Working with each of the three data formats involved in RAMP places a different burden on the user: there is a significant amount of background knowledge involved in reaching a certain comfort level with the data itself, whether it be EAD, EAC-CPF, or wiki markup.
Some of the functionality that did not make it into the initial stage of development includes workflow management features like user accounts, notifications, and approval queues for newly created content, as well as integration with additional APIs. We also plan to explore ways to track usage statistics and measure the impact of RAMP-created articles on access to local resources and materials. Although we do not have the capacity to provide technical support for the tool, we are eager to explore possibilities for collaboration with other institutions and to find ways to plug RAMP into the broader GLAM-Wiki movement.
RAMP is licensed under an Educational Community License, Version 2.0 (ECL-2.0), and its source code is available at https://github.com/UMiamiLibraries/RAMP. Ultimately, we hope that the RAMP editor can serve as a gateway for more librarians and archivists to become active on Wikipedia. The RAMP platform could be used as a starting point for Wikipedia edit-a-thons and could lend support to initiatives like the Wikipedia Library [27], an initiative focused on putting active Wikipedia editors in touch with library resources, or the Rewriting Wikipedia Project, which aims to bring increased diversity to Wikipedia by creating content about “marginalized groups and their histories” [28]. In the end, this project should serve to remind us that archives and special collections are not only repositories of unique content, they are also repositories of information about unique people and organizations. The University of Miami Libraries, for example, are home to collections that reflect the history and culture of South Florida, the Caribbean, Cuba, and the Cuban diaspora. Many of the people and organizations present in our collections, including women and minorities, have not yet been adequately represented in Wikipedia. The overall goal of RAMP is not simply to provide additional access points to local content—although we certainly see that as important. Above all, its objective is to further the altruistic mission of Wikipedia by enriching the global cultural context with information that for too long has been removed from the broader conversation.
Notes
[1] http://en.wikipedia.org/wiki/Wikipedia:GLAM
[2] http://en.wikipedia.org/wiki/User:VIAFbot
[3] http://www.oclc.org/research/news/2012/12-07a.html and http://viaf.org
[4] http://worldcat.org/identities/
[5] http://socialarchive.iath.virginia.edu/prototype.html
[6] https://osc.hul.harvard.edu/liblab/proj/connecting-dots-using-eac-cpf-reunite-samuel-johnson-and-his-circle
[7] http://library.miami.edu/specialcollections/
[8] http://library.miami.edu/chc/
[9] http://en.wikipedia.org/wiki/Scrum_(software_development)
[10] https://en.wikipedia.org/wiki/Template:Infobox_person
[11] https://en.wikipedia.org/wiki/Wikipedia:Persondata
[12] http://ace.c9.io/#nav=about
[13] https://c9.io/
[14] https://gist.github.com/
[15] https://github.com/UNC-Libraries/jquery.xmleditor
[16] https://github.com/chrisboulton/php-diff
[17] https://github.com/Xiphe/jQuery-Merge-for-php-diff
[18] http://www.oclc.org/developer/documentation/virtual-international-authority-file-viaf/using-api
[19] http://oclc.org/developer/documentation/worldcat-identities/using-api
[20] http://www.php.net/manual/en/intro.curl.php
[21] http://www.w3schools.com/dom/
[22] http://en.wikipedia.org/wiki/Wikipedia:Username_policy
[23] We eventually discovered that this page was a duplicate of another page, titled “Rodrigo Prats,” and we used RAMP to create a redirect and merge the new page with the existing one: http://en.wikipedia.org/w/index.php?title=Rodrigo_Prats. For the revision history of the original page, see http://en.wikipedia.org/w/index.php?title=Rodrigo_Prats_Llorens&action=history.
[24] http://en.wikipedia.org/wiki/The_Canterbury_Tales
[25] http://en.wikipedia.org/wiki/Wikipedia:Donating_copyrighted_materials
[26] http://en.wikipedia.org/wiki/Wikipedia:Declaration_of_consent_for_all_enquiries
[27] https://en.wikipedia.org/wiki/Wikipedia:The_Wikipedia_Library
[28] http://dhpoco.org/rewriting-wikipedia/
References
Greene MA, Meissner D. 2005. More product, less process: revamping traditional archival processing. The American Archivist, 68:208-263. Available from http://archivists.metapress.com/content/c741823776k65863/fulltext.pdf
Szajewski M. 2013. Using wikipedia to enhance the visibility of digitized archival assets. D-Lib Magazine [Internet], 19(3):9-. Available from http://www.dlib.org/dlib/march13/szajewski/03szajewski.html
van Hooland S, De Wilde M, Verborgh R, Steiner T, and Van de Walle R. 2013. Named-entity recognition: a gateway drug for cultural heritage collections to the linked data cloud? Available from http://freeyourmetadata.org/publications/named-entity-recognition.pdf
Wisser KM. 2011. Describing entities and identities: the development and structure of Encoded Archival Context–Corporate Bodies, Persons, and Families. Journal of Library Metadata [Internet], 11(3):166-75. Available from http://dx.doi.org/10.1080/19386389.2011.629960
About the Authors
Tim Thompson (t.thompson5@miami.edu) is a Metadata Librarian at the University of Miami Libraries, where his specific responsibilities include metadata creation for collections in Spanish.
James Little (j.little@miami.edu) is a Digital Programmer at the University of Miami Libraries. He holds an MSLIS from the University of Illinois Urbana-Champaign.
David Gonzalez (d.gonzalez26@umiami.edu) is a Digital Programmer at the University of Miami Libraries. He holds a BS degree in Computer Science from the University of Miami.
Andrew Darby (agdarby@miami.edu) is the Head of Web & Emerging Technologies at the University of Miami Libraries.
Matt Carruthers (m.carruthers@miami.edu) is a Metadata Librarian at the University of Miami Libraries, where he supports and enhances discovery of and access to the Libraries’ digital content.

Subscribe to comments: For this article | For all articles
Leave a Reply