By KIA Siang Hock, LI Lingxia
Introduction
Audio and video content forms an integral, important and expanding part of the digital collections in libraries and archives world-wide. While these memory institutions are familiar and well versed in the management of more conventional materials such as books, periodicals, ephemera and images, the handling of audio (e.g., oral history recordings) and video content (e.g., audio-visual recordings, broadcast content) requires additional toolkits. In particular, a robust and comprehensive tool that provides a programmable interface is indispensable when dealing with tens of thousands of hours of audio and video content.
FFmpeg is comprehensive and well-established open source software that is capable of the full range of audio/video processing tasks (such as encode, decode, transcode, mux, demux, stream and filter). It is also capable of handling a wide range of audio and video formats, a unique challenge in memory institutions. It comes with a command line interface, as well as a set of developer libraries that can be incorporated into applications.
Uniquely Audio/Video Singapore Content
Excellence in Singapore Content has been one of the core pillars of the National Library Board (NLB) of Singapore. When the National Archives of Singapore (NAS) joined the NLB family in November 2012, it brought with it a huge and highly valuable collection of audio/video resources, including oral history recordings, sounds, audio-visual recordings and broadcast content. NLB has been progressively digitising the audio/video content for preservation and access purposes and managing the digitised content with its robust and scalable Content Management Service. The NLB Content Management Service is based upon the Alfresco Community Edition (Kia & Wang, 2013).
The Challenges of Audio-Visual Content
Complexity of audio-visual content
Compared with most other formats, audio-visual content are relatively more complex. Figure 1 shows the steps typically required to process such content [1].

Figure 1: Processing of audio-visual content
The content is kept in a ‘container’, more commonly known as a format. The container is used to identify and package the various data components that make up the audio-visual content. Some of the most popular containers are AVI (Audio Video Interleaved), FLV (Flash Video), MPEG (Moving Picture Experts Group), MP4 (MPEG-4) and MOV (Quicktime).
A video container will typically contain one or more data streams for video and audio. Each of these data streams will need to be managed by a codec (coder-decoder) program that is capable of encoding and decoding the data stream based on a specific codec standard. Generally, the codec encodes an input video data into storage, and decodes video content for playback. There are literally hundreds of codecs; the popular ones are H.264 and MPEG4.
Digital Preservation requires high resolution
As a memory institution, it is a key role of NLB to preserve Singapore content that are of historical, cultural and heritage value for future generations to come. For this purpose, the audio-visual content will need to be digitised at the highest possible resolution. The following are some examples of the standards adopted by NLB for the preservation, working and access copies of the content (not exhaustive):
-Standard Definition & High Definition Videos
o MP4 – H.264
o WMV
- Standard Definition Broadcast Quality Videos
o Apple Pro Res HQ
o IMX 30
- High Definition Broadcast Quality Videos
o Apple Pro Res HQ
o XDCAM HD
- 2K Film Resolution Broadcast Quality
o Apple Pro Res HQ
o HDCAM SR
Multi-screen access to audio-visual content
With the proliferation of mobile devices in Singapore (and in many other countries world-wide), it is critical for NLB to be able to deliver its content on all devices (including phones, tablets, notebook and desktop computers). These devices provide varying support for the types of container and codec standards. For optimal delivery, it is necessary to transcode the audio-visual content to cater to the devices to be supported. A media player that is able to detect the device capabilities so as to select HTML5 or Flash to stream the appropriate audio/video format will also be required. NLB uses JW Player for this purpose [2].
About FFmpeg
FFmpeg (Fast Forward Moving Picture Experts Group) is a comprehensive, cross-platform solution to record, convert and stream audio and video [3]. It is free software licensed under the LGPL or GPL, and supported on Linux/Unix, Windows and Mac OS X operating systems.
FFmpeg is made up of 5 key components, namely:
1. ffmpeg: the command line interface
2. ffserver: the media streaming server
3. ffplay: the media player
4. ffprobe: the media data analyzer
5. developer libraries
While the project started in 2000, active development appears to happen from 2010. More recently, a new major release takes place quarterly (version 2.1 was released on 28 October 2013, while version 2.0 was released on 10 July 2013).
Who is Using FFmpeg?
The Projects page on the FFmpeg official website lists some of the users of FFmpeg [4]. For example, the Google Chrome browser uses the FFmpeg libraries to support HTML5 audio and video playback. The popular VLC media player is another project that leverages the cross-platform FFmpeg software [5].
NLB has recently implemented an audio/video streaming infrastructure based on the Wowza solution [6]. FFmpeg has been integrated with that solution.
Beyond these, there have been speculations on the Internet about YouTube and Facebook using FFmpeg in their video upload mechanism. However, these have not been confirmed by Google and Facebook.
Basic Audio/Video Content Processing
As mentioned earlier, FFmpeg comes with the streaming server and media player components. We will, however, not cover them in this article since the focus is on programmatic processing of audio-visual content. Let’s start our tour of the FFmpeg functionalities with some basic tasks. For ease of illustration, we will perform the tasks using the command line interface.
Metadata
We will start by extracting some basic metadata about the audio-visual content. This is done simply by issuing the following command:
ffmpeg –i audio.mp3
The ffmpeg command reads from one or more ‘input’ sources, as specified by the -i option. The input source can be a regular file, a pipe, a network stream, or a grabbing device.
The output on the console is shown in figure 2.
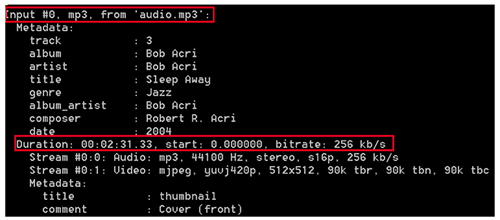
Figure 2: Metadata of MP3 audio file
NLB was interested specifically in the duration information of the audio or video content. In fact, we have successfully integrated the FFmpeg software with our Content Management Service to extract the duration of ingested audio-visual content automatically.
Resize
Another common task with regards to video content is the changing of the width and height of the content, which is needed to create versions of the original video to cater to the different form factors of the playback device.
The following command takes in a video (video.wmv), and creates a new video (video_o.wmv) with width of 320 pixels and height of 240 pixels as denoted by the -s flag:
ffmpeg –i video.wmv –s 320x240 video_o.wmv
Note that the format is normally detected automatically.
There are a number of convenient ways to specify the width and height of the output file required. For example, the parameter of -vf scale=iw/2:ih/2 will result in halving the input width (iw) and input height (ih). iw and ih are predefined variables. The -vf flag applies the video filter.
ffmpeg –i video.wmv –vf scale=iw/2:ih/2 video_o.wmv
Another useful filter is -vf super2xsai. It enlarges the source frame size by 2 times using a scaling algorithm that minimises the reduction of sharpness.
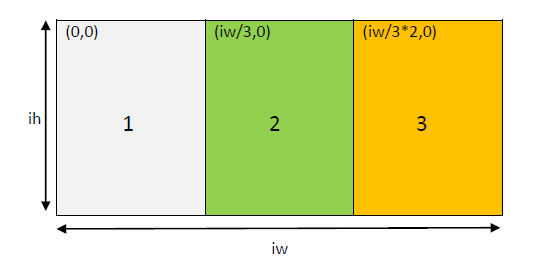
Crop
Cropping is done through the crop filter. The following commands crop the left, middle and right segments of the input video respectively:
1. ffmpeg –i video.wmv –vf crop=iw/3:ih:0:0 video_left.wmv
2. ffmpeg –i video.wmv –vf crop=iw/3:ih:iw/3:0 video_middle.wmv
3. ffmpeg –i video.wmv –vf crop=iw/3:ih:iw/3*2:0 video_right.wmv
The syntax for the crop filter parameter is as follows:
crop=ow[:oh[:x[:y]]]
where
ow – output width
oh – output height
x,y – the co-ordinates of the top left corner of the cropped area
Convert
Before we move on to the more advanced features of FFmpeg, we will cover the important topic of conversion. The conversion can take place from one container format to another (e.g., from WMV to MP4):
ffmpeg –i video.wmv video_o.mp4
While NLB was exploring the use of voice-to-text automatic transcription technologies, we needed to extract the audio component of our video content. This was done simply with the following command:
ffmpeg –i video.wmv audio_o.mp3
Advanced Audio/Video Content Processing
The FFmpeg software is extensive and comprehensive. A thorough discussion of the major features would be beyond the scope of this article. For this rest of the article, we will cover three more features that we find useful in NLB: overlay, extract and join.
Overlay
Many a times, it is necessary to ‘watermark’ the video content, just like how we would watermark an image. We will show the commands to overlay a company logo and a copyright statement onto a video.
To overlay the NLB logo, we will first need the image file (nlb.png in the illustration below). We can then use the following command to achieve the result:
ffmpeg –i video.wmv –i nlb.png –filter_complex overlay video_o.wmv
As shown in figure 3, the NLB logo is placed by default at the top-left corner.
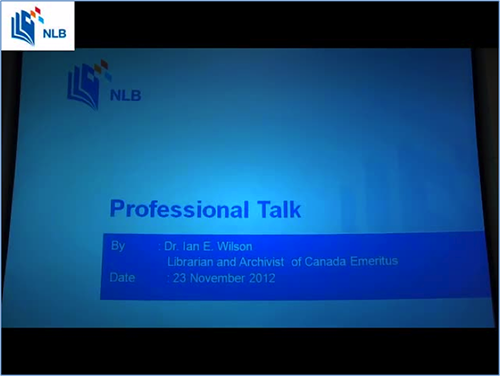
Figure 3: Logo on top left corner
You can determine the exact positioning of the logo by providing an x:y position that represents the top left corner of the logo within the video. FFmpeg defines 4 variables that can be used in the expression for x and y:
W – width of main video
H – height of main video
w – width of overlay
h – height of overlay
With these predefined variables, you can easily place the NLB logo at the bottom right corner using the following command (see figure 4):
ffmpeg –i video.wmv –i nlb.png –filter_complex overlay=W-w:H-h video_o.wmv
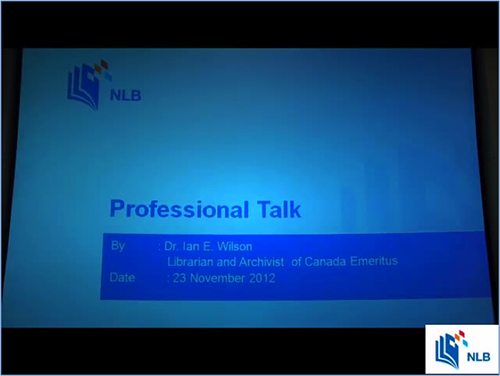
Figure 4: Logo at bottom right corner
It is common to add a copyright statement on our digital content. To do just that, we can use the following command:
ffmpeg –i video.wmv –vf drawtext=”fontfile=/Windows/Font/arialbd.ttf:\
text=’All Rights Reserved.National Library Board Singapore 2013’\
:fontsize=14:fontcolor=white:x=220:y=450” video_o.wmv
By now, the above ffmpeg command should be self-explanatory.
Figure 5 shows the result of the above command, with the logo placed on the bottom left.

Extract
Most libraries and archives provide the service for organisations and individuals to purchase content from their digital collections (where copyright permits), and this service may include audio-visual content. In some cases, the user is able to purchase specific segments of the content, and the libraries/archives will deliver only the segments requested. Many times, such requests will need to be manually fulfilled.
The next 2 commands from FFmpeg can be used to automate the fulfillment process, thereby enabling a fully automated end-to-end, straight-through order processing system.
Assuming that the user-facing ordering system gathers the information about the segment(s) the user would like to purchase, we can then program the system to extract each segment from the video using the following command:
ffmpeg –ss 00:00:10 –t 00:00:20 –i video.wmv video_1.wmv
The segment starting from the 10th second for the duration of 20 seconds will be extracted into video_1.wmv.
This can be repeated if the user has selected multiple segments.
Join
If the user selected multiple segments, these segments will need to be joined together. The command to join multiple audio-visual content is as follows:
ffmpeg –i video_1.wmv –i video_2.wmv –filter_complex concat video_o.wmv
The –filter_complex option is typically used when there are more than one input and/or output, such as the joining of the 2 video input streams in this example and the overlay examples described earlier.
The output file can then be electronically delivered to the user.
Conclusion
We just went on a whirlwind tour of FFmpeg, an excellent open source software for audio-visual content. It will do most of the tasks that you will ever need to perform. While we used audio-visual content to illustrate the features covered in this article, you will be happy to note that quite a number of the FFmpeg options work with images too.
The online official documentation is adequate. However, given the many formats, codecs and numerous parameters and options that FFmpeg supports, it is not easy software to master. The book FFmpeg Basics written by Frantisek Korbel is a good way to start, and the authors of this article have hugely benefited from it.
Moreover, while the illustrations are based on the command line interface, you can easily wrap the command line interface into web services, or embed the developer libraries into your applications. In fact, there are already many FFmpeg wrappers available for popular programming languages, such as the Media Handler Pro by MediaSoft [7].
We now have a powerful tool that we can leverage to handle the complex nature of the tens of thousands of hours of valuable audio-visual resources, and deliver an experience that is engaging anytime, anywhere, on any device.
Notes
[1] Taken from FFmpeg Basics by Frantisek Korbel
[2] http://www.jwplayer.com/
[3] http://ffmpeg.org/
[4] http://ffmpeg.org/projects.html
[5] http://www.videolan.org/vlc/
[6] http://www.wowza.com/
[7] http://www.mediasoftpro.com/media-handler-pro.html
References
KIA, Siang Hock and WANG, Zhi Liang (2013) Content-as-a-service platform with the alfresco open-source enterprise content management system. Paper presented at: IFLA World Library and Information Congress, 17 – 23 August 2013, Singapore.
About the Authors
KIA Siang Hock (siang_hock_kia@nlb.gov.sg) is currently the Deputy Director overseeing the IT Architecture and Innovation at the National Library Board, Singapore (NLB). In this role, he and his teams are heavily involved in the conceptualisation, proof of concepts (PoCs), design and development of various innovative services at NLB.
LI Lingxia (lingxia_li@nlb.gov.sg) is a Senior Systems Analyst at the National Library Board, Singapore. She provides IT solutions and technical supports for internal and public-facing services at NLB. Lingxia is responsible for the developments involving the FFmpeg software.

Nilesh, 2014-03-03
Hi,
How join work with multiple audio files ?