by Mark Phillips, Hannah Tarver, and Stacy Frakes
Introduction
The University of North Texas (UNT) and the Oklahoma Historical Society (OHS) are collaborating to digitize, process, and make publicly available more than one million photographs from the Oklahoma Publishing Company’s historic photo archive. The project, started in 2013, is expected to span a year and a half and will result in digitized photographs and metadata available through The Gateway to Oklahoma History. The project team developed the workflow described in this article to meet the specific criterion that all of the metadata work occurs in two locations simultaneously.
The Gateway to Oklahoma History
The Gateway to Oklahoma History [1] was launched in April of 2012 to showcase the unique collections housed at the Oklahoma Historical Society. The Gateway is operated by the University of North Texas Libraries for OHS and provides access to nearly one million pages of early Oklahoma newspapers. The Oklahoma Publishing Company (OPUBCO) Photography Collection is the first non-newspaper collection added to the Gateway. All digital content added to the Gateway is held in the preservation repository at the UNT Libraries and uses the content delivery system and digital preservation infrastructure at UNT alongside other digital library projects such as the UNT Digital Library [2] and The Portal to Texas History [3]. OHS expects that a wider range of content will be added to the Gateway in the upcoming years including collections of audio, video, maps, and letters, as well as more digitized newspapers and photographs.
Oklahoma Publishing Company Photography Collection
The Oklahoma Publishing Company Photography Collection grew over time as photographs were taken to accompany stories published by Oklahoma newspapers. OPUBCO archived the hard copies which span from the late 1800s to roughly 1994 when the company decided to use digital photography. Most photos are of newsworthy events in Oklahoma or noteworthy Oklahomans living across the United States or abroad. In 2011, the Gaylord family sold the newspaper company and the new owners had no interest in retaining the collection. At that time, the family gifted the collection – approximately 1.7 million photographs – to OHS for preservation.
The photos are filed alphabetically by subject in 8 ½ inch by 12 inch envelopes, each with a heading that describes the photo or photos inside. The back of each photo is labeled with any known information, such as the photographer’s stamp, the date it was taken, the date it was published (if it was published), and the article that accompanied the image. In addition to photographic prints, the collection contains other items that are significant to newspaper photojournalism, including images on zinc printing plates, pressed paper printing press images, negatives, slides, and glass plates. The items in this collection illustrate the history of newspaper photography and the advances made in photograph technology during the 20th Century.
Ethics in Journalism Grant
Early in the process of acquiring the OPUBCO collection, OHS applied for a $300,000 grant from the Ethics in Journalism Foundation. The funds cover two years and are being used to digitize, process, and store the collection for presentation in The Gateway to Oklahoma History. Initially the funds helped hire staff and purchase supplies to move the collection from the OPUBCO headquarters to its current location at the Oklahoma History Center. Now that the project is under way, the funds pay for digitization of the collection at the records conversion division of Oklahoma Correctional Industries; workers scan the original photos and prepare metadata. Grant funds also support UNT’s processes for ingesting the data into The Gateway to Oklahoma History. Because the grant funding lasts only two years and OHS anticipates the project will extend some years into the future, OHS may need to seek an alternative source of funding when the grant ends.
The Workflow
The workflow for digitizing the OPUBCO Photograph Collection comprises five distinct steps: image preparation, image and metadata capture, metadata cleaning, metadata mapping, and metadata quality control.
During the first step, photo archivists at the Oklahoma Historical Society prepare images for the digitization process by pulling photographs that will not be included in the project. The remaining photographs are delivered to Oklahoma Correctional Industries where the digitization and metadata extraction occurs. The images are scanned at 300 ppi and saved in the TIFF format; due to the size of the project, the backs of the photographs are not scanned. As part of the digitization process, the contractors generate descriptive metadata by transcribing information from the photograph file into a spreadsheet (see Table 1), with each row representing a single photograph and each spreadsheet representing an entire archival box.
| Field Name | Field Description | Example Entry |
| ImageFile | Unique identifier for an individual photograph, matching the filename of the corresponding TIFF. | 2012.201.B0316.0019.TIF |
| Envelope | Text printed on the envelope that contains the photograph. | CLARK, JIMMY / SCOTTISH / RACE CAR DRIVER |
| Headline | Headline for the article in which the photograph appeared. | Safety queen back in the lime light |
| Caption | Caption that accompanied the published photograph. | Here’s a dog who has been living up to his good, catchy name. |
| Photog | Name of the photographer who took the photograph. | Richard Green |
| OriginalDate | Date that the photograph was taken. | 19610428 |
| PublishDate | Date that the photograph was published, often with a code representing the newspaper in which it appeared. | O-05-24-1959 |
| CaptionWriter | Author(s) of the caption printed in the newspaper to accompany the photograph. | Vernon B. Snell |
| Credit | Newspaper in which the photograph was published. | Daily Oklahoman |
| Source | Newspaper in which the photograph was published. | Oklahoma Times |
| City | City where the photograph was taken. | Tulsa |
| State | State in which the photograph was taken (or similar division for locations outside the United States). | Oklahoma |
| Country | Country in which the photograph was taken. | USA |
Table 1. Descriptive metadata fields transcribed from the photo files for each image.
The vendor delivers the original photographs plus the digitized images and metadata spreadsheets to OHS in batches. There, staff members inventory the photographs and conduct high-level metadata analysis to verify that the digitization vendor is meeting the requirements of their contract. After performing these checks, staff members group images and metadata into a larger batch of roughly 40,000 images (including metadata) to deliver to the UNT Libraries.
Metadata Cleaning
Raw metadata in the spreadsheets needs some initial clean-up before mapping. The following graphic illustrates the remaining steps for processing the supplied metadata and converting it to the local UNTL metadata format:

Figure 1: Workflow for OPUBCO photography project.
In some cases, values in a particular field or column require normalization to fix typos and other minor inconsistencies in the source metadata. More complex problems can occur when a row has multiple columns with values that have been switched or fields that have been accidentally skipped. The project team uses the open-source tool Open Refine (formerly Google Refine) and the Web-based Google Fusion Tables for metadata cleaning and a locally-developed tool (m2m) at the UNT Libraries for metadata mapping. Final changes and quality control happen within the Gateway’s metadata editing framework.
Open Refine (Google Refine)
Open Refine is “A free, open source, power tool for working with messy data” [4]. In this workflow, UNT Libraries staff members use it first to load multiple similarly-formatted spreadsheets simultaneously and concatenate the individual box-level metadata spreadsheets into a larger dataset representing the entire batch of content. The first two batches processed each contained more than 39,000 photographs with metadata spread across 60-80 separate Excel spreadsheets; Open Refine could load all of these items in a single import step. Once staff members have loaded the data for a batch, they identify and normalize values across rows within specific columns. Columns that have reasonable overlap of values between records are most suitable for this type of editing. For example, the Country column shares many codes among multiple records, while PublishDate and Caption do not, making Country a better candidate for this step.
Typically, once staff members identify a suitable column for this step, they select the option to create a “Text Facet” from each unique value in that column. This lets them sort the entire set of values by the number of times each one occurs in the dataset, or alphabetically by value. By browsing this list they can identify values to normalize. Two examples in this dataset are the normalization of various forms of “United States” and “UNKNOWN” for missing values. In the country field, disparate values such as United States, U.S.A, US, U.S, and USA, were all normalized to “USA,” chosen to represent the country “United States” in this project. Additionally, staff members for this project made a decision to explicitly identify rows without a known value using a default value of “UNKNOWN.” Various versions of this string were present in all columns in the dataset and were normalized using the same faceting process.
Open Refine also identifies the number of cells in each column that have a “blank” value and allows the user to adjust them as needed. One of the most powerful features of Open Refine for this type of work is the ability for a user to make mass edits across a number of cells in a column. For example if there were sixty instances of the string “United States” in the country column, a user could change all of the values to the preferred “USA” with a single change. This makes the normalization process across the dataset much quicker than approaching it in a row-oriented manner.
Other features of Open Refine which are helpful for the normalization process include the ability to apply basic string transformation techniques to each cell in a column. Two of these common transforms include “Trim leading and trailing whitespace” and “Collapse consecutive whitespace” to remove superfluous spaces. Other features include changing values to title case, uppercase, or lowercase, and the option to unescape HTML entities. It is also possible to write custom transformations on the cells within a column by writing short bits of transformation code in one of three languages: Clojure, Jython, or Google Refine Expression Language (GREL). Although these tools were not utilized in this workflow directly, they provide endless possibilities for similar kinds of data transformations and normalization of other datasets.
Open Refine allows users to make use of facets for multiple columns as they process data, to make identification of inconsistencies across rows more obvious. In the OPUBCO dataset there are three columns which contain information related to place: City, State, and Country. These three columns were compared together to identify rows in the dataset where the Country was identified as USA or Canada, but for which the State column value was not one of the fifty states or thirteen provinces or territories, respectively. Likewise, this provided the ability to identify rows where a known city, such as “Oklahoma City,” had missing or mismatched state and country values.
The faceting approach also helped users identify cells which were transposed by one or more columns during the initial data entry process. Open Refine allows a user to facet on custom functions related to the column cell values. For example the number of characters in a field can be used as the facet value instead of the actual string present in the field. This is helpful when there is an expected range for the length of a field, such as a date field which should always have four to eight digits for this dataset. Fields that did not meet the expected length often contained values entered into incorrect columns during the transcription process.
A powerful feature of Open Refine is the ability to “cluster” values of a column and provide a simple interface for merging similar values. This is especially useful for columns that have a reasonable amount of overlap but sometimes suffer from transcription errors, such as names. Open Refine has two kinds of clustering: key collision, and nearest-neighbor. Key collision takes the values of a column and applies a weak hashing function to the input string, then groups all of the values on this newly generated hash or key. A number of hashing functions are present and described in the tool’s documentation. The first key collision hashing function is called fingerprint and applies the following transformations to the input string in order to create the key:
- remove leading and trailing whitespace
- change all characters to their lowercase representation
- remove all punctuation and control characters
- split the string into whitespace-separated tokens
- sort the tokens and remove duplicates
- join the tokens back together
- normalize extended western characters to their ASCII representation (for example “gödel” >> “godel”)
This is helpful for catching a number of typos and grouping inverted and non-inverted names if they consist of only first and last name. For example the following values are all assigned the same fingerprint of “a owen y”:
- A. Y. Owen
- Owen, A. Y.
- A Y Owen
- A. Y Owen
Once a collision is identified, Open Refine chooses the entry with the most instances as the target to be used when merging these values. A user has the opportunity to modify this suggested value with a more appropriate value to be applied after the merge. As a user merges various terms, he can save changes to the dataset and rerun the clustering process.
In addition to the fingerprint function, Open Refine uses ngram-fingerprint, and two phonetic fingerprint algorithms: metaphone3 and cologne-phonetic. The documentation for Open Refine explains these algorithms and their strengths in further detail [5].
Open Refine can also create clusters using a nearest-neighbor clustering algorithm (also known as kNN). There are two algorithms available for use in this clustering process, levenstein (or edit distance) and PPM (Prediction by Partial Matching). For a full explanation of the algorithms and process used for the nearest neighbor clustering functionality, consult the Open Refine documentation [5].
Once staff members have finished column-centric data normalization, they export the entire dataset as a comma-separated-value (CSV) file for the next step of the process.
Google Fusion Tables
Google Fusion Tables [6] is “an experimental data visualization web application to gather, visualize, and share larger data tables” [7]. The project team has found it to be a useful tool for the OPUBCO photograph project for several reasons. First, the application is available freely through the Google Drive suite of tools in a Web-based context; this means that multiple people across both institutions could interact with one hosted version of the dataset and not have to resort to checking out, modifying, and then checking in files, or even worse, e-mailing versions of the dataset between the various project team members. Second, Fusion Tables provides a row-based view of the dataset with the ability to edit each row as a “record.” The ability to edit a row as a record makes it possible to edit a field within a row or to copy and paste between fields of a row quickly. Third, the application provides the ability to search and facet on one or more fields similarly to Open Refine to help analyze values across the dataset.
A staff member loads the exported spreadsheet from the Open Refine portion of the workflow into Google Drive to generate a new Fusion Table. Once created, other participants in the project are allowed editing access to the table with the “Share” feature. So far there have been two team members at UNT and one member at OHS who have participated in data cleanup utilizing one Fusion Table.
Each team member focuses on a different aspect of data cleanup. One focuses on place, photographer, and caption writer names; another focuses on dates; and yet another focuses on headlines, captions, and envelope data. With all three working on specific areas of the dataset, work happens quickly. Row-based changes – such as moving values that had been transposed – are straightforward using Fusion Tables. In this tool, focusing on one value opens the entire row/record making it easy to shift values or change multiple field values in a single incorrect row.
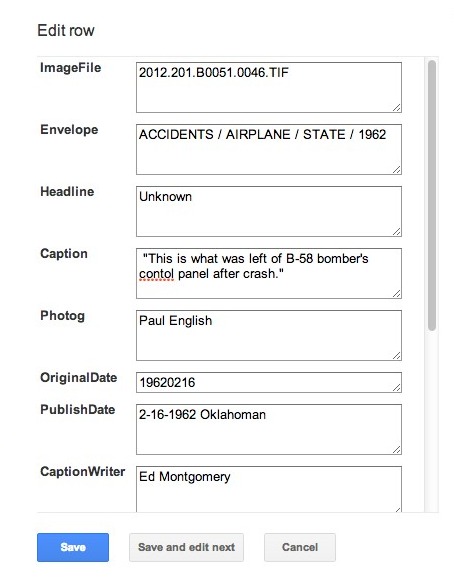
Figure 2: Detail of Edit row screen in Google Fusion Table.
Because of data inconsistencies in the first batch of items, roughly 3,500 rows were modified using Fusion Tables.
Once all data manipulations are completed in Google Fusion Tables, staff members export the resulting dataset as a CSV file for use in the next step of the conversion process.
Metadata Mapping
All of the digital objects hosted in the UNT system – including those in The Gateway to Oklahoma History – have the same metadata schema containing twenty-one possible fields. This UNT Libraries (UNTL) format is a locally-qualified Dublin-Core-based metadata format; semantic guidelines are fully documented on the Digital Projects Unit website [8]. At this stage in the workflow, data from the photos in the first batch needed to be mapped from the spreadsheets to XML files in the UNTL format; once established, the same mapping will work for all future batches.
UNTL Metadata
The goal behind mapping the field values included preserving all of the information available (i.e., documented in the spreadsheets) while matching UNTL formatting to improve usability of information for the general public. Based on the content available for the OPUBCO photographs, staff members conceptually mapped data from the spreadsheets to the most relevant fields in the UNTL metadata (see Table 2).
| UNTL Field | Qualifier | OPUBCO Field(s) |
| Title | Main | ImageFile |
| Added | Headline | |
| Creator | Photographer | Photog |
| Contributor | Author | CaptionWriter |
| Date | Creation | OriginalDate |
| Description | Content | Source Caption |
| Subject | Keyword | Source Envelope |
| OPUBCO | Envelope | |
| Coverage | Place Name | City State Country |
| Date | OriginalDate | |
| Source | Newspaper | Headline Source PublishDate |
| Identifier | Local Control Number | ImageFile |
| Note | Display | Credit PublishDate |
Table 2. Relationship of OPUBCO photo fields to UNTL fields.
Additionally, some UNTL fields had default values that did not come from the OPUBCO data, such as resource type, language, and physical description. Some values required formatting changes, e.g., inverting personal names for creators and contributors, normalizing dates to a YYYY-MM-DD format, and changing locations to hierarchical strings.
For each UNTL field, staff members documented which values should come from the spreadsheets, any changes or ordering of data, and how to handle information that was not available. As an example, the “Source” field pulls information from the Headline, Source, and PublishDate fields in the spreadsheet. Initial notes about the mapping included the following:
Source
Qualifier: Newspaper
Text: “{{{Headline}}},” {{{Source}}}, Oklahoma City, Oklahoma, {{{PublishDate}}}
X-MM-DD-YY >> Month Day, Year
— if headline is unknown, use {{{Source}}}, Oklahoma City, Oklahoma, {{{PublishDate}}}
— if source is unknown, do not include source
— if publish date is unknown, leave it out
Terms surrounded by three braces represent values pulled from columns in the spreadsheets with those titles. This list provided the general information to create a script for generating the final records. So a complete UNTL Source term would look like: “Air Safety Officers,” Oklahoma City Times, Oklahoma City, Oklahoma, October 25, 1957. This documentation serves as pseudo-code utilized for creating the formal mapping between the spreadsheet data and the UNTL metadata format discussed in the section below.
Metadata to Metadata (m2m)
A final mapping step uses a local UNT Libraries tool to generate UNTL records from the spreadsheets, following the conceptual mapping. This tool, locally called m2m which stands for “Metadata to Metadata,” is based on work described by Janée and Frew in their paper “A Hybrid Declarative/Procedural Metadata Mapping Language Based on Python” [9]. The m2m tool works with a spreadsheet in the CSV format and applies a set of declarative mapping functions to each row in the dataset to emit a properly-formatted UNTL XML file for ingest into the digital library system.
Example 1. Sample m2m mappings for title, contributor, and subject
#create record instance
record = RecordClass("mphillips")
# Mapping of column Headline to title with addedtitle qualifier
record.map("basic", "title", row["Headline"].title(), required=False,
qualifier="addedtitle")
# Mapping of column CaptionWriter to contributor with aut qualifier,
# per for the name type, and "Caption writer" as added info"
record.map("agent", "contributor", invertName(row["CaptionWriter"]),
qualifier="aut", required=False, agent_type="per", info="Caption writer.")
# Mapping of column Envelope to subject with KWD qualifier, split input on
# forward slash and then apply a title case function to each piece, then create
# an instance of subject in the metadata record for each piece
record.map("basic", "subject", row["Envelope"],
qualifier="KWD", required=False, split=" / ",
function=(lambda x: x.title()))
Example 2. Command line script to convert spreadsheet data to XML records
python m2m.py -m opubco2untl.py OPUBCO-November.csv
Because the mappings in the m2m tool are written in Python, it is easy to implement modifications to the input data as it is processed, for example: changing the case for a field to title case, inverting personal names, loading external data to use as replacement dictionaries, or creating new metadata fields based on the presence of specific attributes in the supplied data. These features were used extensively in the full mapping file for the OPUBCO project.
Example 3. Input data formatted in JSON
{
"Caption": "\" The tail section of a T-33 jet trainer from Vance Air Force Base,
Enid, landed in an open field southeast of Tinker AFB after
colliding with an F-104 Starfighter jet Thursday afternoon
southeast of Tinker.\" ",
"CaptionWriter": "Mark Sarchet",
"City": "Oklahoma City",
"Country": "USA",
"Credit": "Daily Oklahoman",
"Envelope": "ACCIDENTS / AIRPLANE / COUNTY / 1950-1970",
"Headline": "Unknown",
"ImageFile": "2012.201.B0051.0221.TIF",
"OriginalDate": "19591112",
"Photog": "Cliff King",
"PublishDate": "11-13-1959 Oklahoman",
"Source": "Daily Oklahoman",
"State": "Oklahoma"
}
Example 4. Resulting UNTL metadata.xml file after metadata mapping
<?xml version="1.0" encoding="UTF-8"?>
<metadata>
<title qualifier="officialtitle">[Photograph 2012.201.B0051.0221]</title>
<creator qualifier="pht">
<type>per</type>
<name>King, Cliff</name>
</creator>
<contributor qualifier="aut">
<info>Caption writer.</info>
<type>per</type>
<name>Sarchet, Mark</name>
</contributor>
<date qualifier="creation">1959-11-12</date>
<language>nol</language>
<description qualifier="content">Photograph used for a story in the Daily Oklahoman
newspaper. Caption: "The tail section of a T-33 jet trainer from Vance Air Force
Base, Enid, landed in an open field southeast of Tinker AFB after colliding with
an F-104 Starfighter jet Thursday afternoon southeast of Tinker."</description>
<description qualifier="physical">1 photograph: b&w</description>
<subject qualifier="UNTL-BS">
Business, Economics and Finance - Journalism
</subject>
<subject qualifier="KWD">Accidents</subject>
<subject qualifier="KWD">Airplane</subject>
<subject qualifier="KWD">County</subject>
<subject qualifier="KWD">1950-1970</subject>
<subject qualifier="KWD">Daily Oklahoman photographs</subject>
<subject qualifier="OPUBCO">ACCIDENTS / AIRPLANE / COUNTY / 1950-1970</subject>
<primarySource>1</primarySource>
<coverage qualifier="placeName">
United States - Oklahoma - Oklahoma County - Oklahoma City
</coverage>
<coverage qualifier="date">1959-11-12</coverage>
<coverage qualifier="timePeriod">mod-tim</coverage>
<source qualifier="newspaper">
Daily Oklahoman, Oklahoma City, Oklahoma, November 13, 1959
</source>
<collection>OKPCP</collection>
<institution>OKHS</institution>
<resourceType>image_photo</resourceType>
<format>image</format>
<identifier qualifier="LOCAL-CONT-NO">2012.201.B0051.0221</identifier>
<note qualifier="display">PublishDate: 11-13-1959 Oklahoman</note>
<note qualifier="display">Credit: Daily Oklahoman</note>
<meta qualifier="metadataCreator">mphillips</meta>
<meta qualifier="hidden">True</meta>
</metadata>
The resulting metadata file is coupled with the master image file and a JSON file containing the original data mapped into the UNTL file. The resulting structure is created for each image file before it is loaded into the Gateway.
Example 5. Digital folder structure for an object ready for ingest into Gateway.
2012.201.B0051.0221 |-- 01_tif | |-- 2012.201.B0051.0221.tif |-- 02_json | |-- metadata.json |-- metadata.xml
Quality Control
The UNTL records generated from the original spreadsheets are ingested along with the images into The Gateway to Oklahoma History. Metadata editors at the OHS then use the Gateway’s metadata editing interface to finalize the records by adding details and making corrections. This typically includes generating a title for each photograph, adjusting content descriptions, and adding keywords or personal names. Editors also check the other values to ensure that the information matches the photograph and catch any additional formatting or typographical errors missed during the metadata cleaning stage. As editors complete this final stage, they make photographs accessible to the public.
Conclusion
The workflow that the Oklahoma Historical Society and the UNT Libraries use for the OPUBCO photo project is a straightforward, scalable, and repeatable process that others can leverage for their own collaborative projects. Since it uses primarily Web-based tools, it allows for flexibility in the number of editors that have access to the datasets and limitations of resources. Combining Open Refine and Google Fusion Tables allows staff members to edit data using both column-based and row-based tools and techniques to achieve the cleanest data possible given the size of the dataset and the timeframe for editing. This approach drastically reduces the amount of manual editing post-ingest and helps to prevent consistency errors. These tools also make it easy to divide the work into a number of parts and share them between the institutions, since multiple project members could edit the metadata without the need to track and merge changes between versions. Finally the utilization of the UNT-specific metadata-to-metadata (m2m) mapping process provides another layer of flexibility for helpful modifications to the metadata records just before they are loaded into the production system, which reduces the amount of repetitive manual editing required for the large collection of photographs. With a project completion date of late 2014, UNT Libraries and OSH expect the workflow outlined in this article to scale adequately to meet the challenge of adding nearly one million new images with metadata to The Gateway to Oklahoma History.
Notes
[1] The Gateway to Oklahoma History; http://gateway.okhistory.org/
[2] UNT Digital Library; http://digital.library.unt.edu/
[3] The Portal to Texas History; http://texashistory.unt.edu/
[4] Open Refine; http://openrefine.org/
[5] Open Refine Documentation; https://github.com/OpenRefine/OpenRefine/wiki/Clustering-In-Depth#key-collision-methods
[6] Google Fusion Tables; http://www.google.com/drive/apps.html#fusiontables
[7] About Google Fusion Tables; https://support.google.com/fusiontables/answer/2571232?hl=en
[8] UNT Libraries Metadata Documentation; http://www.library.unt.edu/digital-projects-unit/metadata/
[9] Janée, Greg, and James Frew. “A Hybrid Declarative/Procedural Metadata Mapping Language Based on Python.” National Geospatial Digital Archive. n. page. Web. 15 Jan. 2014. http://www.ngda.org/docs/Pub_Janee_ECDL_05.pdf.
Authors
Mark Phillips is Assistant Dean for Digital Libraries at the University of North Texas Libraries.
Hannah Tarver is Head of the Digital Projects Unit at the University of North Texas Libraries.
Stacy Frakes is the Oklahoma Publishing Company photo archivist at the Oklahoma Historical Society.

Subscribe to comments: For this article | For all articles
Leave a Reply