by Arie Nugraha
Introduction to MariaDB and Sphinx
MariaDB is a drop-in replacement for MySQL, a very popular open source database server. What makes MySQL popular is its ease of use and deployment compared to other database servers such as PostgreSQL and ORACLE. The official MySQL reference manual states that:
“MySQL Server was originally developed to handle large databases much faster than existing solutions and has been successfully used in highly demanding production environments for several years. Although under constant development, MySQL Server today offers a rich and useful set of functions. Its connectivity, speed, and security make MySQL Server highly suited for accessing databases on the Internet.”
In 2009, ORACLE acquired Sun Microsystems, and with it MySQL AB, the company that has developed and maintained MySQL from the beginning. MySQL’s founder, Michael Monty, fearing that Oracle would close the MySQL codebase, created a fork of MySQL called MariaDB which has the same features and improved performance.
Integrated Library Systems (ILSes) mostly store their metadata/bibliographic description inside database servers to enable fast storage and retrieval. One of the problems when a database server stores a large number of documents is the speed of retrieval. For document retrieval, MariaDB has built-in full-text searching capability, but it comes with its own problem: it could only run on the MyISAM table type before MariaDB version 10.0 and the MyISAM table type comes with its own problems, because it is easily corrupted under some circumstances (http://dev.mysql.com/doc/refman/5.7/en/corrupted-myisam-tables.html). Scalability and performance are additional issues, especially when we deal with a high number of concurrent queries.
Sphinx Search Server (Sphinx) is a standalone product that provides fast full-text search capability for relational databases such as MariaDB, MySQL, PostgreSQL and any database that can be connected via ODBC such as MS SQL Server. Sphinx supports two query methods that integrate particularly well with MariaDB and MySQL. The first allows us to query an indexed MariaDB or MySQL instance directly and retrieve results indexed in Sphinx by setting up Sphinx’s MySQL Storage Engine (SphinxSE). The second lets us query the Sphinx server by connecting to it via the MariaDB or MySQL client library (libmysql version > 4.1 at minimum) and issuing queries using the SphinxQL syntax, a Sphinx-specific SQL dialect. Note that the first method requires our indexed database to be MariaDB or MySQL, while the latter method only requires the client and can be used no matter what kind of database we index.
Some of Sphinx’s features are explained on its official website (http://sphinxsearch.com/docs/2.1.8/features.html) and make it very suitable for indexing large documents:
- Proven scalability up to billions of documents, terabytes of data, and thousands of queries per second;
- High search speed (up to 150-250 queries/sec per core against 1,000,000 documents, 1.2 GB of data);
- Supports boolean, phrase, word proximity and other types of queries;
- Supports stopwords;
- Supports stemming (stemmers for English, Russian, Czech and Arabic are built-in; and stemmers for French, Spanish, Portuguese, Italian, Romanian, German, Dutch, Swedish, Norwegian, Danish, Finnish, Hungarian, are available by building the third party libstemmer library);
From this author’s experience, Sphinx is easy to set up both as a standalone server and integrated with an existing MariaDB database installation, and it is also very fast. This article covers basic usage of Sphinx to index MariaDB database content. Its main focus is integrating Sphinx and MariaDB via SphinxSE, but it also demonstrates searching using SphinxQL as well as the Sphinx API. For the purpose of this article, the author will set up Sphinx, SphinxSE (the Sphinx storage engine of MariaDB) and MariaDB with this hardware and software configuration:
- Operating system : CentOS 6.4 64 bit GNU/Linux with latest update
- Database server : MariaDB 5.5.37 with Sphinx plugin
- Sphinx server : Sphinx 2.1.8
- Processor : Intel Core i7 3770
- Memory : 8 GB
- Drive : 30GB SSD
Sphinx Compared to Other Search Engine Servers
Compared to other digital content indexing solutions such as Solr or ElasticSearch, which are more web services-oriented, Sphinx was specially designed to integrate well with SQL database servers, and to be easily accessed by scripting languages. As such, Sphinx is very suitable for those who already have existing digital content inside database servers such as MariaDB, PostgreSQL, MS SQL, etc. and want the content to be indexed for fast retrieval without having to convert to another format first. Sphinx has very good indexing and retrieval speed; from this author’s experience Sphinx can index approximately 86,200 documents in under 20 seconds.
MariaDB Setup
Setting up MariaDB to work with Sphinx is straightforward and relatively easy. To use Sphinx in MariaDB, we should have MariaDB version 5.2.2 at the minimum and also SphinxSE engine installed in the MariaDB server. The author uses the CentOS operating system. To install MariaDB, open the Terminal program and issue this command as root:
# yum install MariaDB-server MariaDB-client
# service MariaDB start
Before executing the above command we must make sure that MariaDB has been added to the yum repository, or else yum won’t install anything. More on how to setup MariaDB on CentOS/RedHat/Fedora can be found at https://mariadb.com/kb/en/installing-mariadb-with-yum/.
Setup Sphinx and the SphinxSE Storage Engine
After completing the MariaDB installation process, the next step is to set up Sphinx and SphinxSE. One of the methods used to integrate MariaDB with Sphinx is to enable MariaDB’s SphinxSE storage engine. To enable SphinxSE in MariaDB, we can issue a one-time SQL command:
INSTALL SONAME 'ha_sphinx';
SHOW ENGINES;
One advantage of using the Sphinx engine in MariaDB is that we don’t need to use the Sphinx API to retrieve records from the Sphinx server, all queries to the Sphinx server are handled by MariaDB using SQL syntax. This means that there will be no big changes to ILS programming code.
Download the latest stable release from http://sphinxsearch.com/downloads/release/, choosing the appropriate operating system and operating system architecture (32/64 bit). In this article, the author used the RHEL/CentOS 6.x x86_64 RPM binary and installed it by issuing this command:
# yum install postgresql-libs
# rpm -Uvh Sphinx-2.1.8-1.rhel6.x86_64.rpm
Sphinx is working as a server/daemon, much like the MariaDB daemon or any other daemon in GNU/Linux. To start the Sphinx server we then issue this command:
# searchd

Figure 1. Starting Sphinx searchd Server (enlarge)
If we don’t see any errors, that means we are ready to go. By default, the server listens on port 9312, but we can tweak this configuration by editing the Sphinx.conf file located in /etc/Sphinx.
To index our database content, we need to configure Sphinx so it knows what kind of records/documents from our database to index. To configure Sphinx indexes, we must open Sphinx.conf and edit some parameters:
source our_documents
{
type = MariaDB
sql_host = localhost
sql_user = root
sql_pass = secret
sql_db = test
sql_port = 3306
sql_query = SELECT biblio_id, title, series_title, author, topic, \
notes FROM search_biblio
sql_query_info = SELECT * FROM search_biblio WHERE biblio_id=$id
}
index idx_our_documents
{
source = our_documents
path = /var/lib/sphinx/idx_our_documents
stopwords = /etc/Sphinx/stopwords.txt
docinfo = extern
charset_type = sbcs
}
indexer
{
mem_limit = 64M
}
searchd
{
listen = 9312
listen = 9306:mysql41
log = /var/log/Sphinx/searchd.log
query_log = /var/log/Sphinx/query.log
read_timeout = 5
max_children = 30
pid_file = /var/run/Sphinx/searchd.pid
max_matches = 10000
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
workers = threads # for RT to work
binlog_path = /var/lib/Sphinx/
}
In the above configuration, our main settings are in lines 1-22, and line 40; the “indexer” and “searchd” may not need to be changed at all. Our custom settings simply state that we want “our_documents,” taken from our MariaDB database with the query “SELECT biblio_id, title, series_title, author, topic, notes FROM search_biblio FROM search_biblio,” to be indexed into an index named “idx_our_documents.” Note that Sphinx will assume that the first column (biblio_id) on the “sql_query” parameter is a document ID and this document ID MUST BE an INTEGER or BIGINT type. Other columns specified in “sql_query” will be indexed by the Sphinx indexer.
To improve indexed data, we also can set a stopwords file in the “stopwords” parameter inside our index. The stopwords file is just a plain text file which contains a comma separated list of words that are excluded from the index. In this example, the stopwords file is located at /etc/Sphinx/stopwords.txt.
The Sphinx configuration file allows more than one index to be defined. This is very useful when we wish to index the contents of two or more databases. After the configuration is completed then we must run the Sphinx indexer by executing the following command:
# indexer idx_our_documents
This command tells the Sphinx indexer to fetch records from MariaDB based on an index named “idx_our_documents”. The result of this will be something like the following:
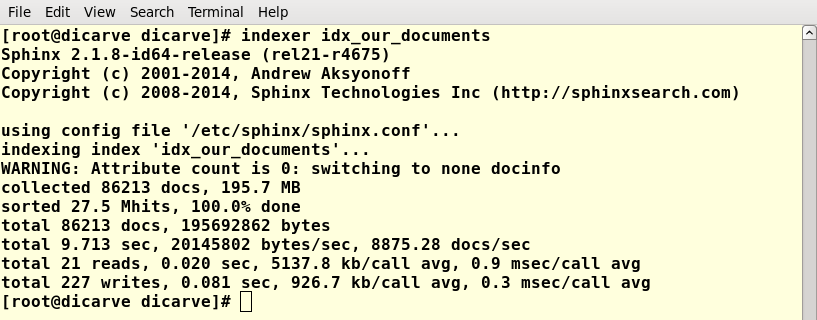
Figure 3. Indexer result (enlarge)
In this example, we have 86,213 library bibliographic records populated from Springer’s MARC Download Tool. The table structure for storing bibliographic records is taken from the open source ILS Senayan Library Management System (SLiMS), search_biblio table. SliMS uses this as a redundant table for storing the bibliographic records index to speed up search. The structure of this table can be seen below:
| Column | Type |
| biblio_id | int(11) |
| title | text |
| edition | varchar(50) |
| isbn_issn | varchar(20) |
| author | text |
| topic | text |
| gmd | varchar(30) |
| publisher | varchar(100) |
| publish_place | varchar(30) |
| language | varchar(20) |
| classification | varchar(40) |
| spec_detail_info | text |
| location | text |
| publish_year | varchar(20) |
| notes | text |
| series_title | text |
| items | text |
| collection_types | text |
| call_number | varchar(50) |
| opac_hide | smallint(1) |
| promoted | smallint(1) |
| labels | text |
| collation | varchar(100) |
| image | varchar(100) |
| input_date | datetime |
| last_update | datetime |
Figure 4. Bibliographic record table structure
After we create the index with Sphinx, we must next create a table in MariaDB which acts as a proxy to the Sphinx server. The table structure must be at least like this:
CREATE TABLE idx_our_documents ( id BIGINT UNSIGNED NOT NULL, weight INTEGER NOT NULL, query VARCHAR(3072) NOT NULL, INDEX(query) ) ENGINE=SPHINX CONNECTION="Sphinx://127.0.0.1:9312/idx_our_documents";
The first three fields are mandatory, because they will be used by Sphinx server when returning search results.
Querying Records in Sphinx
Sphinx has historically had five document matching modes: “all,” “any,” “phrase,” “boolean,” or “extended.” However, according to the official documentation, the preferred matching mode is now “extended” (SPH_MATCH_EXTENDED), which has subsumed the others (which are deprecated). The “extended” match mode supports the following syntax:
Boolean syntax:
operator OR:
information | knowledge
operator NOT:
information -retrieval
information !system
Field match syntax:
field search operator:
@title information @content information retrieval
field position limit modifier:
@content[50] information
multiple-field search operator:
@(title,body) information retrieval
ignore field search operator (will ignore any matches of ‘information’ from field ‘title’):
@!title information
all-field search operator:
@* information retrieval
Phrase match syntax:
phrase search operator:
“database indexing”
proximity search operator:
“database indexing”~10
quorum matching operator:
“using Sphinx to index digital content”/3
Strict order syntax
strict order operator:
aaa << bbb << ccc
field-start and field-end modifier:
^information retrieval$
There are also other search operators not mentioned in this article, but we think that above examples are the most important operators which will be commonly used for search query. More information about other operators can be found at http://sphinxsearch.com/docs/2.1.8/extended-syntax.html.
Specific Field Match
Before using Sphinx, to query our bibliographic records from our database we go straight to the MariaDB table that holds bibliographic data like this (assuming that we have already created a full-text index on the columns we are searching):
MariaDB Query
SELECT *
FROM `search_biblio`
WHERE MATCH(`title`, `notes`) AGAINST('+database +indexing +multimedia' IN BOOLEAN MODE)
ORDER BY `title` ASC;
In the above query, we want a document whose title and notes fields MUST contain the terms “database, “indexing”, and “multimedia”. When using Sphinx we query the proxy table instead with this equivalent syntax:
Sphinx Query
SELECT * FROM `idx_our_documents` WHERE `query`='@(title, notes) database indexing multimedia;mode=extended;limit=10000;sort=extended:@weight desc';
In this example, both MariaDB’s Full Text Search (FTS) and Sphinx return the same results, 36 unique documents retrieved. The difference is in speed, MariaDB’s FTS query took 4.5758 seconds to return the result, while Sphinx only took 0.0019 seconds.
Phrase Match
Now we will try to search using a phrase match query. The “notes” field in the “search_biblio” table holds keywords and also a document abstract. With traditional MariaDB’s FTS query, our query for documents which contain the phrase “information retrieval” and also contain the phrase “natural language” inside the “notes” field will be like this:
MariaDB Query
SELECT * FROM `search_biblio`
WHERE MATCH(`notes`) AGAINST('"information retrieval"' IN BOOLEAN MODE)
AND MATCH(`notes`) AGAINST('"natural language"' IN BOOLEAN MODE)
ORDER BY `title` ASC;
The query returns 64 documents in 0.1041 seconds. With Sphinx the query will be like this:
Sphinx Query
SELECT * FROM `idx_our_documents` WHERE `query`='@notes "information retrieval" "natural language"; mode=extended; limit=10000; sort=extended:@weight desc';
Sphinx also return 64 documents, but with faster speed, 0.0064 seconds.
Start End Match
Since MariaDB’s FTS doesn’t support start and end match operators yet, if when we want to search for documents that start or end with some words in MariaDB, we use a non-FTS query (which uses an ordinary index, not a full-text one) and also the wildcard operator (the % symbol) in this query:
MariaDB Query
SELECT * FROM `search_biblio` WHERE `title` LIKE 'information%' OR `title` LIKE '%management' ORDER BY `title`;
The query searches for documents which start with “information” or end with “management”. The result returns 571 documents in 0.1045 seconds. Sphinx’s equivalent query will be like this:
Sphinx Query
SELECT * FROM `idx_our_documents` WHERE `query`='@title ^information | @title management$; mode=extended; limit=10000; sort=extended:@weight desc';
The interesting thing we found here is Sphinx returns more results, with 925 documents in 0.0085 seconds.
SphinxQL Usage
Another method to query Sphinx indexes is through the MariaDB or MySQL native protocol with SphinxQL. With SphinxQL, we don’t need to use the SphinxSE storage engine and its proxy table, but rather we can query the Sphinx server directly using the MySQL or MariaDB client library. With this method, the Sphinx server acts as if it is a MySQL or MariaDB server, allowing any MariaDB/MySQL client API to connect to and query it.
SphinxQL is Sphinx’s own subset of SQL. It is similar to standard SQL, but it has additional features that are not supported in standard SQL. One of the advantages of using SphinxQL is that the syntax supports real-time updating of Sphinx indexes where the traditional API does not.
To connect and query our existing index using SphinxQL in PHP we can write code like this:
<?php
// Sphinxql-test.php
// define constant
define('SPHINX_HOST', '127.0.0.1');
define('SPHINX_PORT', 9306);
define('SPHINX_INDEX', 'idx_our_documents');
// connect to Sphinx server using Mysqli
$dbs = @new mysqli('127.0.0.1', '', '', '', 9306);
// query
$query = '@title database indexing';
// query index
$query = $dbs->query("SELECT * FROM ".SPHINX_INDEX." WHERE MATCH('$query') LIMIT 0, 10000");
// get record(s)
$found = $query->num_rows;
if ($found > 0) {
echo "Found ".$found." record(s) :\n";
while ($data = $query->fetch_object()) {
echo "Document ID : ".$data->id."\n";
}
} else {
echo "Sorry, no match found...\n";
}
Figure 5. Using PHP to connect & query Sphinx server with MariaDB and SphinxQL
If this script is executed in terminal we will see output like this:
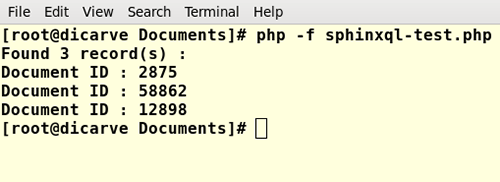
Figure 6. Result of PHP script when executed
Sphinx API Usage
Besides using SphinxSE and SphinxQL, Sphinx’s developers also provide an API to popular programming languages such as Java, Ruby, Python and PHP. These APIs are already bundled inside the Sphinx distribution. If we are using the Sphinx API, then we connect straight to the Sphinx server and not via MariaDB’s SphinxSE engine. To connect and query to our index in PHP, we need at minimum to write code like this:
<?php
// Sphinx-test.php
// define constant
define('Sphinx_HOST', 'localhost');
define('Sphinx_PORT', 9312);
define('OUR_INDEX', 'idx_our_documents');
// query
$query = '@title database indexing';
// main API class inclusion
require "sphinxapi.php";
// create Sphinx client instance
$cl = new SphinxClient();
// set connection params
$cl->SetServer( Sphinx_HOST, Sphinx_PORT );
$cl->SetConnectTimeout( 1 );
$cl->SetArrayResult( true );
$cl->SetWeights( array ( 100, 1 ) );
$cl->SetMatchMode( SPH_MATCH_EXTENDED2 );
$cl->SetSortMode( SPH_SORT_EXTENDED, '@weight desc' );
$cl->SetSelect( 'title, author, topic, notes' );
$cl->SetLimits( 0, 100, 10000 );
$cl->SetRankingMode( SPH_RANK_PROXIMITY_BM25 );
// execute the query
$res = $cl->Query( $query, OUR_INDEX );
// iterate the result
if ( $res===false ) {
// query is failed
print "Query failed: " . $cl->GetLastError() . ".\n";
} else {
if ( $cl->GetLastWarning() ) :
print "WARNING: " . $cl->GetLastWarning() . "\n\n";
endif;
print "Query '$query' retrieved $res[total] of $res[total_found] matches in $res[time] sec.\n";
print "Query stats:\n";
if ( is_array($res["words"]) ) :
foreach ( $res["words"] as $word => $info ) :
print " '$word' found $info[hits] times in $info[docs] documents\n";
endforeach;
endif;
if (is_array($res["matches"]) ) {
$n = 1;
print "Matches:\n";
foreach ( $res["matches"] as $docinfo )
{
print "$n. doc_id=$docinfo[id], weight=$docinfo[weight]";
foreach ( $res["attrs"] as $attrname => $attrtype )
{
$value = $docinfo["attrs"][$attrname];
print ", $attrname=$value";
}
print "\n";
$n++;
}
}
}
Figure 7. Using PHP to connect and query the Sphinx server using the PHP Sphinx API
If the above script is executed in a terminal, we will see output like this:

Figure 8. Result of Sphinx PHP script when executed (enlarge)
Conclusion
Sphinx is a good alternative for indexing digital content/documents already stored inside an existing DBMS, especially MariaDB. It is easily deployed and configured, and therefore presents a lower barrier to entry for system librarians or library/archives software developers. Combined with MariaDB and its SphinxSE engine, Sphinx becomes even easier to integrate into existing ILSes that use MariaDB as their backend. Sphinx’s ranking feature makes it easier to rank documents based on their relevance. Sphinx’s performance is also good compared to native MariaDB indexing system, so it is also a good alternative if we just want to index existing MariaDB database records for fast retrieval.
Bibliography
Aksyonoff, Andrew. 2014. Sphinx 2.1.8-release reference manual. Sphinx Open Source Search Server [Internet]. [Cited 2014 May 17]. Available from: http://sphinxsearch.com/docs/manual-2.1.8.html
Aksyonoff, Andrew. 2011. Introduction to Search with Sphinx: From installation to relevance tuning . Sebastopol, CA. O’Reilly Media.
Daniel Bartholomew et. al, 2014. Enabling Sphinx in MariaDB. MariaDB [Internet]. [Cited 2014 May 17]. Available from: https://mariadb.com/kb/en/about-Sphinx/
Gilfillan I, Razzoli F. 2014. Fulltext Index Overview. MariaDB [Internet].[Cited 2014 May 17]. Available from: https://mariadb.com/kb/en/fulltext-index-overview/
Monty M, Bartholomew D. 2012. Installing and testing Sphinx with MariaDB. MariaDB [Internet]. [Cited 2014 May 17]. Available from: https://mariadb.com/kb/en/installing-and-testing-Sphinx-with-mariadb/
MySQL [Internet]. Corrupted MyISAM Tables. [Cited 2014 July 15]. Available from: http://dev.mysql.com/doc/refman/5.7/en/corrupted-myisam-tables.html
MySQL [Internet]. What is MySQL? [Cited 2014 July 15]. Available from: http://dev.mysql.com/doc/refman/5.7/en/what-is-mysql.html
About the Author
Arie Nugraha currently works as a junior lecturer for the Department of Library and Information Science, Faculty of Humanities, University of Indonesia. He lectures about library automation, databases and also digital libraries to bachelor degree library science students at the University of Indonesia. He is also an active open source developer.
He may be reached at dicarve@gmail.com. He blogs at http://dicarve.blogspot.com.

Subscribe to comments: For this article | For all articles
Leave a Reply