By Corey Davis
Introduction
While “paper survives benign neglect for a long time” (Rosenthal, 2010a), such is not the case with materials on the web. Digital information is far more fragile than print. “Electronic resources are profoundly unstable,” and unlike paper, they are not generally intelligible following even a modest amount of wear and tear (Cohen & Rosenzweig, 2005). Websites are especially problematic because of the ephemeral nature of content on the web itself. The average half-life of a webpage has been estimated at two years (Koehler, 2004), which is almost certainly too generous, and those that do survive tend to change frequently (Dougherty et al., 2010). So while the web’s impact on society has continued to grow alongside an explosive growth of the content available, this rich trove of informational resources remains very much at risk. Roger Highfield (2014) of The Telegraph captures the feeling of many librarians and archivists involved in web archiving when he states: “[i]f we’re not careful, historians will know more about the beginning of the past century than the start of this one.” It is this sense of urgency and obligation that in great part animates web archiving initiatives throughout the world.
Web archiving
Web archiving involves collecting data from the web, storing that data and preserving it at some level, and making it accessible to users (Niu, 2012). Julien Masanès of the Internet Memory Foundation, and former director of web archiving at the Bibliothèque Nationale de France (BnF), has identified three main technical approaches to web archiving (Pennock, 2013): transactional, server-side, and client-side.
“[T]ransactional archiving records content… presented to a user on a given date and time” by creating a record of all HTTP requests and responses (Pennock). This requires server-side configuration, which means the cooperation of a host. SiteStory (http://mementoweb.github.io/SiteStory) is an example of a transactional web archiving tool. Developed at the Los Alamos National Laboratory, SiteStory enables a server, when it receives a request from a browser:
…to send the response to that browser as expected, but also [to] push it into an associated web archive. As a result, all versions of all resources that are being requested by browsers are also available in the archive (Van de Sompel, 2012).
Server-side archiving also requires support from content hosts because it involves copying files directly from a server. Server-side archiving can be employed when content, such as a database, cannot easily be captured via HTTP requests. DeepArc is an example of a server-side web archiving tool. Developed by the BnF, it “transform[s] relational database content into XML for archiving purposes” (Aubry & Hafri, 2005).
By far the most common form of web archiving is client-side, also referred to as remote harvesting. In this method, web crawlers use the HTTP protocol to collect content directly from a server by crawling all the links associated with a specific ‘seed’ URL. Crawl behavior is determined by providing the crawler with instructions about crawl parameters, such as crawl depth (Pennock).
The Internet Archive
The most well known client-side archiving technology was developed at the Internet Archive (IA), a remarkable organization founded in 1996 by MIT graduate and Silicon Valley entrepreneur Brewster Kahle, with the express purpose of “build[ing] an Internet library” (Internet Archive, n.d.a). It was only after Kahle and his group’s groundbreaking work that “national libraries and archives around the world also began to see the importance of preserving this global resource [i.e. the web]” (Grotke, 2011). As such, many national libraries have established web archiving initiatives. For example, as of 2012, the BnF’s archive consisted of 370 terabytes, or 18 billion pages. In 2013 the British Library conducted the first crawl of all .uk websites, which led to the capture of 30 terabytes of data (Webber, 2014). The Library of Congress had collected 250 terabytes by 2011, and Library and Archives Canada’s collection consists of over 7 terabytes [1]. These and other national collections still pale in comparison to the IA, which contains over 2 petabytes of data and over 150 billion web pages, and the IA corpus grows by approximately 100 terabytes a month (Internet Archive, n.d.b)—larger than the entirety of most national library collections. To provide a sense of scale, the web archives of the Library of Congress—the world’s largest library—grows at the relatively meager rate of 5 terabytes a month (Taylor, 2011). And while the IA has developed an incredibly important resource—the Wayback Machine gets close to 700,000 unique IP visits per day (Internet Archive, 2014)—in the words of Clifford Lynch, “terrifyingly, this major chunk of our cultural memory basically relies on the good offices and good spirit of Brewster Kahle” (Lynch, 2014).
The IA and its archiving technologies dominate the web archiving landscape. Teams at IA developed the widely-used Heritrix tool, a Java application that crawls the web and stores content specifically for the purposes of web archiving (Donovan, 2014). That content is stored in either the ARC or WARC format [2], both of which “specif[y] a method for combining multiple digital resources into an aggregate archive file together with related information” (Library of Congress, 2009). [3] This means that in addition to, for example, the HTML text, other files—images, JavaScript, media files, etc.—are combined into a single W/ARC file, which also contains crawl-specific metadata to indicate “the time of harvesting, the IP address of the harvesting machine, Internet Media Type (MIME type) and response code for the harvest transaction, the purpose of harvesting, etc.” (Library of Congress, 2009). W/ARC files can then be replayed by entering the original page’s URL into an instance of the Wayback Machine, a Java Servlet application “that retrieves, displays, and indexes archived Internet content” (Donovan). The Heritrix web crawler and the Wayback Machine are both open source [4], and have been extensively implemented at institutions ranging from the Library of Congress (n.d.) to the subscription-based Web Archiving Service (WAS) of the California Digital Library (n.d.). WARC is an ISO standard (28500:2009), and W/ARC files can be indexed for full-text search using open-source tools like NutchWAX (developed by the Internet Archive and the Nordic Web Archive), Solr, or Elasticsearch, all of which are based on Lucene [5].
To serve the web archiving needs of smaller institutions, several SaaS tools have been brought to market in recent years. In 2005, the IA launched Archive-it, a subscription-based service based on its core web archiving technologies, which it “developed, in particular, for memory institutions and state archives” in order to create curated collections not captured by larger web archiving efforts (Information Today, 2005). The California Digital Library’s Web Arching Service (WAS) is another SaaS tool using Heritrix, Wayback, and NutchWAX—all technologies developed initially at the IA¬—and is used by many institutions, including Stanford and Berkeley. ArchivetheNet (also in SaaS) is offered by the Internet Memory Foundation (IMF) and is used, among others, by the British Library to create the UK Government web archive.
University of Victoria’s web archiving initiative
With the IA and various national libraries and other organizations archiving the web, why would a research library want to get involved? To start with, IA crawls are broad and focus on top-level domains, and national library collections tend to emphasize government sites and country-specific domains (.ca, .fr, .uk, etc.). This approach needs to be paired “with deep, curated collections by theme or by site, tackled by other cultural heritage organizations” (Grotke). In this way, web archives can be seen as an extension of existing collection activities meant to support faculty, student, and community research:
…broad national web archive collections, which often only have limited accessibility for legal and technical reasons, may not meet the dispersed needs of individual researchers, and be in danger of providing a “one-size fits nobody” solution. Archiving and providing access to individual historical web resources is the basic “must-have” of a web archive (Hockx-Yu, 2012).
In 2013, the University of Victoria Libraries decided to subscribe to the Archive-it service as part of a consortial license negotiated by the Council of Prairie and Pacific University Libraries (COPPUL). Up to this point, while some at the library recognized the importance and possibilities of archiving websites—especially in support of archives and special collections—there was no clearly-articulated demand for such a service by librarians, archivists, or faculty. As such, when the COPPUL offer was announced and the library decided to participate in the Archive-it subscription, it was without a preconceived vision of what a web archiving initiative would look like, or how it would fit into the library’s emerging strategies around digital scholarship. In fact, it took almost eight months before we identified specific websites and started initial test crawls using Archive-it. It has only been since the start of 2014 that we have begun building collections in earnest. These currently include: an events-based collection on the 50th anniversary of the University; several thematic collections in support of our extensive archival and special collections holdings on anarchist and transgender issues, hyper-local news, and environmental organizations; collections of local government websites; and, digital humanities websites. The IA hosts and stores all of the data and provides a web-based interface through which relatively non-expert users can create collections.
Some organizational challenges considered
Library vs. archive
While the web is often referred to as “the world’s largest library”, this analogy is disingenuous. Academic library collections—or at least library acquisitions budgets—still tend to be dominated by books and journal articles (and the platforms and discovery services that make them accessible in either print or electronic form). Relationships between these kinds of materials—most of which are considered discrete information objects—are not rigorously represented, and they tend to be grouped together based on some shared subjective quality, such as subject matter. This is not the case with archives, which consist largely of primary source materials organized according to very different principles: respect des fonds, provenance, and original order. At most universities, the administrative functions for library and archival acquisitions are distinct. Websites do not respect such organizational arrangements. Articles, reports, newsletters, and other ‘discrete published items’ are common on websites, but website structure—the relationship between documents—is also important. Unlike items on a library shelf, “[w]eb documents at the page level (but also the site level) hardly ever make sense alone….[t]hey are mingled in a larger document network” (Masanès, 2005). In this way, they are more like archival material, where original order—i.e. site structure—is essential to understanding the whole. And much web content, such as blogs and wikis, is of a kind whose print analogs would usually be found in collections of personal or organization documents in an archive. Furthermore, the use of the term “archive” vis-à-vis web archiving, is also problematic, because in this context the term itself is “much more in keeping with the computing usage of archive as a back-up copy of information then the disciplinary perspective of archives” (Owens, 2014). The organizational lines that often separate libraries from archives suggest that for web archiving initiatives to be successful, participants will have to be willing to work across traditional divides. Jurisdictional issues—if not addressed upfront—can stall a web archiving initiative. In order to address this challenge, our initiative at the University of Victoria is overseen by an Archive-it Working Group with broad representation. This working group consists of people with technical and collections expertise, but also the Associate University Librarian for Learning and Research Resources, the head of Collections Management Services for the library, as well as the Director of Special Collections and the University Archivist.
The ownership conundrum
Websites as objects of acquisition can blur the organizational lines between library and archive. But they are also problematic in the same way that a significant amount of open access journal literature is. The advent of open access content is a relatively new thing for librarians. We tend to focus on materials we have paid for. Services like Portico, LOCKSS, and Scholar’s Portal attempt to tackle issues of preservation, but are mostly focused on subscription-based resources. And while work is currently being done by the Public Knowledge Project (PKP) to address the long-term preservation of Open Journal System (OJS) content using LOCKSS (Public Knowledge Project, 2014), open access literature—especially from smaller publishers—tends to be more vulnerable to loss than expensive subscription-based content, simply because no single library necessarily has the incentive to invest in long-term preservation. Websites tend to fall into this same category. Unlike governmental organizations that have a mandate to collect certain types of websites, such as state or national libraries and archives, university libraries and archives rarely have such obligations. For individual selectors, the focus is generally on expending funds for books, journals, research databases, and other paid-for resources. There is often little incentive to build collections of archived websites, which involves a considerable amount of effort, especially when more pressing collection-building activities related to acquisitions are at hand. As such, any web archiving initiative will have to carefully consider how to engage librarians in the time-intensive process of collection building.
Legal issues
An article for Wired UK about archiving Britain’s web contains the subtitle: “the legal nightmare explored” (Scott, 2010). This is not far off the mark, and as of this writing, the University of Victoria Libraries is still in the process of finalizing our policy around web archiving. As such, we have not yet made the majority of our collections available to the public.
Basically, there are two approaches to dealing with the issue of copyright: opt-in and opt-out. With the opt-in approach, the institution undertaking the web archiving contacts the appropriate content owners to get explicit permission to capture their site. The opt-out approach simply captures sites of interest while respecting the robots.txt protocol, and take-down and other requests are handled after the fact on a case-by-case basis.
The opt-in approach is best characterized by the British Library’s approach to the creation of its Open UK Web Archive prior to 2013. Response rates to permission requests were just 24 percent. The CEO of the British Library at the time, Dame Lynne Brindley, considered this approach unsustainable because it would mean the capture of perhaps only one percent of UK websites (Scott). All of this changed, of course, when legislation for legal deposit for non-print resources passed in the UK Parliament in April 2013 (British Library, 2013). As of this writing, the British Library is working on its second annual capture of the entire UK domain (Webber).
The Internet Archive uses an opt-out approach, “that allows a website owner/content provider to remove access from the archive, and/or prevent their content from being captured by putting up a robots.txt exclusion on their website” (Scott). If requested by the content owner, the IA will remove a site from public access via the Wayback Machine—but not, importantly, from its central index.
Because the scale of the web is so vast, and response rates to permission requests are so low, many consider the opt-out approach the only workable solution to web archiving. In the Canadian context, this is the approach used by the University of Alberta Libraries (2013), which states: “when a site owner authorizes communication of their work to the public by telecommunication without technological restrictions, we view this as their implicit consent to the indexing and caching of their site.” This is the general approach the University of Victoria is planning to take. And while this approach has not been tested in the courts, many universities in the U.S. and Canada are conducting web archiving under the auspices of fair use (or its Canadian equivalent, fair dealing), as outlined in the Association of Research Libraries Code of best practices in fair use for academic and research libraries (2012). This document states quite forcefully that:
[Web archives] represent a unique contribution to knowledge and pose no significant risks for owners of either the sites in question or third-party material to which those sites refer. In the absence of such collections, important information is likely to be lost to scholarship….It is fair use to create topically based collections of websites and other material from the Internet and to make them available for scholarly use.
The Library of Congress seems to strike a balance between the two perspectives. While they might seek explicit permission for some sites, “some notice at a minimum must be provided to the site owner” before their site is crawled and captured (Library of Congress Collection Development Office, 2013).
Because of the lack of explicit legal precedence and the varying approaches to web archiving across multiple institutions in multiple jurisdictions, it is absolutely central to tackle the issue of permissions as early on as possible, often in consultation with legal counsel.
Technical issues
The web has not only grown in size, but also in complexity. It was originally envisioned by Berners-Lee as a collection of documents, and up until the early 2000s, this mostly held true:
In the 1990’s and even moving into the early 2000’s, most Web pages and site designs were relatively simple. Many used “hybrid” site models that enabled publishers to separate out resources into separate directories and to optimize for different usage scenarios and workflows, but the majority of the emphasis was on more traditional load balancing for scale vs [sic] integration across diverse hosts and services (Netpreserve.org, 2012).
Things have certainly changed. As Negulescu and Rosenthal (2013) aptly put it, “it’s not your grandfather’s web anymore.” Most websites are anything but simple. For example, an August 28, 2014 Archive-it test crawl of the New York Times homepage captured 235 URLs from 61 individual hosts, including 85 images (53 jpegs, 18 gifs, and 14 pngs) and 35 JavaScripts.
Table 1: A file types report from Archive-it for the homepage of the New York Times, August 28, 2014. The File Types report shows how many URLs were captured for each specified file type.
| File Type | URLs |
|---|---|
| text/dns | 62 |
| image/jpeg | 53 |
| text/html | 47 |
| text/plain | 36 |
| application/x-javascript | 24 |
| image/gif | 18 |
| image/png | 14 |
| unknown | 14 |
| application/javascript | 8 |
| text/css | 6 |
| application/json | 4 |
| text/javascript | 3 |
| image/x-icon | 2 |
| text/json | 2 |
| application/x-shockwave-flash | 1 |
| application/xml | 1 |
| image/svg+xml | 1 |
| text/xml | 1 |
The trouble with AJAX
Websites are becoming increasingly reliant on technologies like JavaScript, XML, JSON, and AJAX/J, which can be problematic for a traditional crawler like Heritrix. A good example is the website for Colonial Despatches, a “digital archive [that] contains the original correspondence between the British Colonial Office and the colonies of Vancouver Island and British Columbia” (Holmes, n.d.). Created by the Humanities Computing and Media Centre at the University of Victoria, the site is based on a large eXist database containing XML documents marked up in TEI, and serves as a good example of some of the technical issues facing web archiving tools that use the client-side harvesting approach.
While the website looks relatively simple, it is not. For example, the browse section (http://bcgenesis.uvic.ca/docsByDate.htm) uses AJAX techniques to convert TEI/XML called from the database, processes it via XSLT into XHTML, and embeds it in the page using JavaScript and CSS.
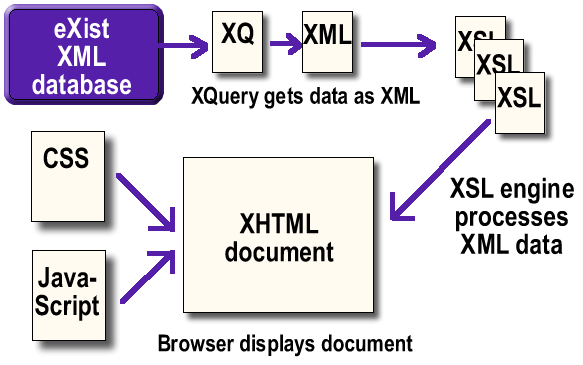
Image 1: A simple version of the application structure of the Colonial Despatches website (http://bcgenesis.uvic.ca/development.htm).
When users go to the browse page, they are presented with a JavaScript-driven list which expands as they click on list items:
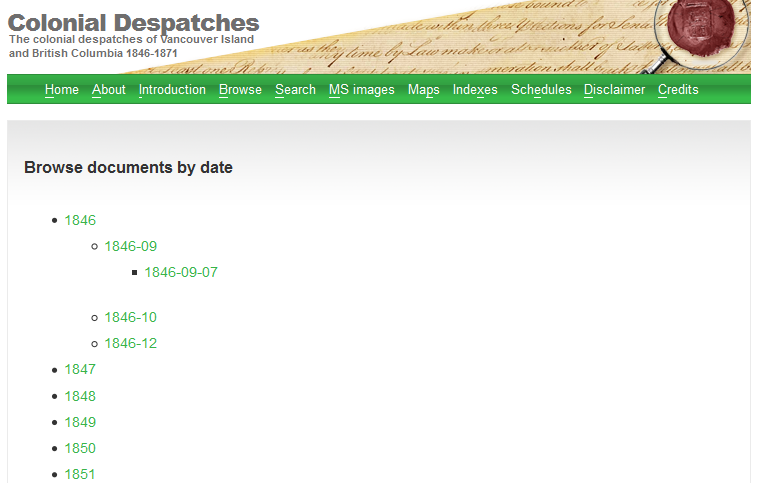
Image 2: When users click on the final ‘link’, the JavaScript executes a call to the eXist database to get the data related to a specific date.

Image 3: This content is then embedded dynamically into the page.
Before the advent of AJAX and similar functionality, dynamically generating XML content for display in a single page was not possible, and users would most likely be taken to another page via an anchor tag (< a>) containing a URL with specific database query parameters. This anchor tag would enable the Heritrix crawler to execute the specific database query via HTTP, get the associated document, and capture it.
In the above example, < span> tags are used in place of < a> tags, perhaps because <span> is more flexible in terms of display (most browsers have default display rules which can affect the appearance of < a> tags, whereas < span> is a kind of tabula rasa). Here is the code for the last bullet in the list:
<li> <span class="getDocsByDate" onclick="getDocsByDate(this, '1846-09-07')"></span> <div></div> </li>
When the JavaScript is executed, the < div> tags are filled in with XSLT-transformed and CSS-formatted TEI/XML data from the eXist database. Because Heritrix can only discover content by following links to that content from an initial ‘seed’ URL, and because in this case the < span> tag is used in place of an anchor < a> tag, Heritrix will not recognize this as a link and will therefore not execute the JavaScript necessary to create a link to query the database and generate the appropriate content for archiving. In fact, it’s not clear that this kind of dynamic menuing—even if < a> tags were used—would result in effective capture, because URLs are generated through user interaction, and are therefore not a part of the page content or the associated JavaScript.
The problems with dynamic, interactive content
This example hints at one of the major limitations of all current crawlers, where “web pages that are generated via a database in response to a request from the user” are simply not captured (Pennock). And this limitation is particularly serious as database-driven websites become the norm, and where content is increasingly generated dynamically based on user-initiated HTTP requests, either through form-based queries or via AJAX-driven user interactions. For example, the index page for the Diary of Robert Graves 1935-39 and ancillary material (http://graves.uvic.ca/graves/site/index.xml) can only be accessed via form-based query, which makes it very problematic to access via the Wayback Machine [6].
More and more website content is being generated dynamically from database content called via user-initiated JavaScript. This development is almost certain to continue as HTML5 is more widely adopted in order to provide an app-like experience via mobile web browsers (i.e. websites will behave more like single-purpose apps, but without the constraints levied, for example, by Apple’s App Store). As Rosenthal (2011) states, “the key impact of HTML5 is that, in effect, it changes the language of the Web from HTML to JavaScript, from a static document description language to a programming language.” This means that traditional web crawlers like Heritrix will have increasingly more trouble archiving materials effectively: “a major effort to develop techniques capable of collecting and preserving AJAX and HTML5 is urgently needed” (Rosenthal, 2011).
No one knows this more than the folks at Archive-it:
Web sites have become increasingly reliant on client-side script to render pages and to ensure an optimal viewing experience to users….For example, as a user navigates within a Facebook page, content is delivered on demand through JavaScript when the user scrolls to an un-viewed section of their timeline. Displaying content dynamically through client script allows sites to optimize the user experience and reduce the load on their servers. These optimizations, however, make it difficult for Heritrix to discover resources that are necessary for optimal capture and display of archived content (Reed, 2014).
As of June 5th, 2014, Archive-it has deployed a tool called Umbra, to work alongside Heritrix when crawling seed URLs. According to Archive-it:
When a crawl is run using Umbra, designated seeds are sent by Heritrix to a separate process that mimics the way a browser would access the seed URLs. This allows client-side script to be executed so that previously unavailable URLs can be detected for Heritrix to crawl. Umbra also gives Heritrix a flexible way to imitate human interactions with Web sites that were previously not possible, such as executing JavaScript through clicking or hovering the mouse over different Web page elements and scrolling down a page (Reed).
This is heartening, but the results so far have been mixed. Crawls at the University of Victoria since June 5th have effectively captured popular social media sites like Facebook and Twitter (for which Umbra is optimized), but the above-mentioned issues with AJAX in the Colonial Despatches site occurred during crawls in August 2014, two months after Umbra was released. Again, in this particular instance, the tag might be the problem, and an effective capture might result from using the < a> < a>tag instead, but this is unclear, and the basic issue remains: “crawlers are not able to see any content that is created dynamically” (Google, 2014, June 14).
These kinds of challenges are an issue for search engines like Google, whose crawlers also have trouble with dynamic content. Their Webmaster Guidelines talk about how to deal with some of these issues:
Use a text browser such as Lynx to examine your site, because most search engine spiders see your site much as Lynx would. If fancy features such as JavaScript, cookies, session IDs, frames, DHTML, or Flash keep you from seeing all of your site in a text browser, then search engine spiders may have trouble crawling your site (Google, 2014).
Because of Google’s overwhelming role in content discovery, content creators have an incentive to make their stuff as visible as possible to Google’s spiders. As such—and especially for larger, more commercially-oriented sites—decisions are made early in the creation of sites that allow Google to more effectively index content, such as the creation of site maps in XML. And while SEO is very different than web archiving, the principles are the same. If the library is able to somehow influence decisions at an early stage in the development of websites, these sites can be optimized for web archiving. As such, we have recently started a series of conversations with Humanities Computing and Media Centre on issues of web archiving and digital preservation. We are discussing the possibility of creating some built-in functionality for dynamic sites that would automatically write content into flat HTML for capture by Archive-it, perhaps similar to techniques for generating HTML snapshots for indexing AJAX applications in Google (Google, 2014, June 18).
This raises another important issue: what exactly are we trying to capture? In the case of the Colonial Despatches website, even if a perfect representation of the look-and-feel, functionality, and interactivity could be achieved via the use of a tool like Archive-it, the eXist database containing the marked-up TEI/XML of the original transcribed documents would not be preserved. This database—which represents the majority of the project’s human effort—arguably has more value than the website itself. We have talked with the Humanities Computing and Media Centre about possible capture strategies that include a virtual machine snapshot of the entire OS. In some cases the use of a tool like DeepArc might be an option. Our use of Archive-it has stimulated these kinds of conversations, and it’s clear that this is an area in need of considerably more investigation and testing.
Access and digital preservation
Another area of consideration is digital preservation and access. WARC files captured by Archive-it are stored in the United States (Hanna, 2014). For Canadian institutions, this is problematic because the notice-and-takedown provisions of the American Digital Millennium Copyright Act (DCMA) differ significantly from the notice-and-notice regime under Canada’s Copyright Modernization Act. This situation could potentially see the removal of content by the Internet Archive where that content might not have been removed had a similar take-down request been issued in Canada. This is even more troubling considering tools like Archive-it are used to capture sites where content owners might have compelling reasons beyond copyright to see that captured content is removed (politically-oriented and government sites, for example). Where a convincing argument can be made to keep public access available to captured content, having that content located in the U.S. is problematic.
Digital preservation is another key issue for web archives. Capturing websites in WARC format for playback and full-text search is only a part of what is needed for true digital preservation. WARC files backed up by the Internet Archive are susceptible to corruption. As David Rosenthal has recognized, the IA can be thought of as a statistical sample of the whole web. Some data loss is to be expected, and this loss introduces an acceptable amount of noise into a very large sample (Rosenthal, 2010b). This is not necessarily problematic at scale, but for the purposes of a single institution, it is concerning.
Archive-it does provide users with WARC files on request, which can then be managed locally. At the University of Victoria, we are considering obtaining copies of our WARC files for processing by Archivematica and storage in the COPPUL Private LOCKSS Network (COPPUL PLN). Archivematica is an “open-source digital preservation system that is designed to maintain standards-based, long-term access to collections of digital objects” (Archivematica, n.d.). Archivematica can ingest WARC files, which are run through a series of processes based on the Open Archival Information System Reference Model (ISO-OAIS), which allows for future preservation planning based on format identification and other information. Archivematica creates Archival Information Packages (AIPs) from WARCs using Bagit. These ‘bagged’ files can then be uploaded to the COPPUL-PLN, where a single copy, if damaged, can be repaired by other copies in the network. None of this potential Archivematica/LOCKSS integration development work is trivial, especially the creation of a manifest for LOCKSS to harvest AIPs from Archivematica, but it is important to recognize that jurisdictional issues and considerations of digital preservation may require the local management of WARC files to ensure ongoing access and long-term preservation.
Conclusion
The collections being created by the University of Victoria Libraries are unique in the world, and even though the act of capturing websites is a messy affair, there is real value in capturing content that would almost certainly not be around by the time today’s students become tomorrow’s researchers. The importance of the web as part of the human record cannot be overstated, but there are significant challenges any organization faces in starting a web archiving initiative. Organizational, legal, and technical challenges all need to be addressed.
Notes
[1] Lists of website archiving initiatives are maintained at http://netpreserve.org/about/archiveList.php and http://en.wikipedia.org/wiki/List_of_Web_archiving_initiatives
[2] For sample ARC and WARC files from the Internet Archive, see https://archive.org/details/ExampleArcAndWarcFiles
[3] “The (W)ARC format is a revision of the ARC File Format [ARC_IA] developed in the mid-1990’s that was first used to store Web crawls as sequences of content blocks harvested from the World Wide Web.” https://webarchive.jira.com/wiki/display/ARIH/Archive-It+Storage+and+Preservation+Policy
[4] See https://webarchive.jira.com/wiki/display/Heritrix/Heritrix and http://archive-access.sourceforge.net/projects/wayback/
[5] “Solr or elasticsearch may prove more versatile than NutchWax, which is designed to be implemented in large multi-server environments.” https://www.archivematica.org/wiki/Websites
[6] See https://wayback.archive-it.org/4376/20140807180501/http://graves.uvic.ca/graves/site/index.xml
References
Archivematica. (n.d.). What is Archivematica? Retrieved from https://www.archivematica.org/wiki/Main_Page
Association of Research Libraries. (2012, January). Code of best practices in fair use for academic and research libraries. Retrieved from http://www.arl.org/storage/documents/publications/code-of-best-practices-fair-use.pdf
Aubry, S., & Hafri, Y. (2005). DeepArc. Retrieved from http://deeparc.sourceforge.net/
British Library. (2013, April 4). Click to save the nation’s digital memory. Retrieved from http://pressandpolicy.bl.uk/Press-Releases/Click-to-save-the-nation-s-digital-memory-61b.aspx
California Digital Library. (n.d.). Web archiving services FAQ. Retrieved from http://webarchives.cdlib.org/faq
Cohen, D. J., & Rosenzweig, R. (2005). The fragility of digital materials. In Digital history: a guide to gathering, preserving, and presenting the past on the web. Retrieved from http://chnm.gmu.edu/digitalhistory/preserving/1.php
Donovan, L. (2014, April 25). Archive-It (AIT) 4.5 technical overview. Retrieved from https://webarchive.jira.com/wiki/display/ARIH/Archive-It+%28AIT%29+4.5+Technical+Overview
Dougherty, M., Meyer, E. T., Madsen, C., van den Heuval, C., Thomas, A., & Wyatt, S. (2010). Researcher engagement with web archives: state of the art. Retrieved from http://repository.jisc.ac.uk/544/1/JISC-REWA_StateoftheArt_August2010.pdf
Google, Inc. (2014). Webmaster guidelines. Retrieved from https://support.google.com/webmasters/answer/35769?hl=en
Google, Inc. (2014, June 14). What the user sees, what the crawler sees. Retrieved from https://developers.google.com/webmasters/ajax-crawling/docs/learn-more
Google, Inc. (2014, June 18). How do I create an HTML snapshot? Retrieved from https://developers.google.com/webmasters/ajax-crawling/docs/html-snapshot
Grotke, A. (2011). Web archiving at the Library of Congress. Computers in Libraries, 31(10). Retrieved from http://www.infotoday.com/cilmag/dec11/Grotke.shtml
Hanna, K. (2014, February 12). Archive-It storage and preservation policy. Retrieved from https://webarchive.jira.com/wiki/display/ARIH/Archive-It+Storage+and+Preservation+Policy
Highfield, R. (2014, January 6). Can DNA reign supreme in the digital dark age? The Telegraph. Retrieved from http://www.telegraph.co.uk/science/10553626/Can-DNA-reign-supreme-in-the-digital-dark-age.html
Hockx-Yu, H. (2012, December 19). Digital humanities and the study of the web and web archives. Retrieved http://britishlibrary.typepad.co.uk/webarchive/2012/12/digital-humanities-and-the-study-of-the-web.html#sthash.CSWkLtSl.dpuf
Holmes, M. (n.d.). Development of this site [Colonial Despatches]. Retrieved from http://bcgenesis.uvic.ca/development.htm
Information Today. (2005, November 28). Internet Archive offers new archive service. Retrieved from http://newsbreaks.infotoday.com/Digest/Internet-Archive-Offers-New-Archive-Service-16063.asp
Internet Archive. (2014, August). Number of unique IP addresses per day. Retrieved from https://archive.org/stats/
Internet Archive. (n.d.a). About the Internet Archive. Retrieved from https://archive.org/about/
Internet Archive. (n.d.b). Internet Archive projects. Retrieved from https://archive.org/projects/
Koehler, W. (2004). A longitudinal study of Web pages continued: a consideration of document persistence. Information Research, 9(2). Retrieved from http://www.informationr.net/ir/9-2/paper174.html
Library of Congress Collection Development Office. (2013). Library of Congress collections policy statements supplementary guidelines: Web archiving. Retrieved from http://www.loc.gov/acq/devpol/webarchive.pdf
Library of Congress. (2009). WARC, Web ARChive file format. Retrieved from http://www.digitalpreservation.gov/formats/fdd/fdd000236.shtml
Library of Congress. (n.d.). Web archiving: technical information. Retrieved from http://www.loc.gov/webarchiving/technical.html
Lynch, C. A. (2014, January 30). Challenges of stewardship at scale in the digital age. Retrieved from http://youtu.be/rfvLlQ2nZj0
Masanès, J. (2005). Web archiving methods and approaches: a comparative study. Library Trends, 54(1). Retrieved from http://muse.jhu.edu/journals/library_trends/v054/54.1masanas.html
Negulescu, K. C., & Rosenthal, D. S. (2013). Not your grandfather’s web anymore. Retrieved from http://www.cni.org/topics/digital-preservation/not-your-grandfathers-web-any-more/
Netpreserve.org. (2012, May 17). IIPC future of the web workshop: introduction & overview. Retrieved from http://netpreserve.org/sites/default/files/resources/OverviewFutureWebWorkshop.pdf
Niu, J. (2012). An overview of web archiving. D-Lib Magazine, 18(3/4). Retrieved from http://dlib.org/dlib/march12/niu/03niu1.html
Owens, T. (2014, February 27). What do you mean by archive? genres of usage for digital preservers. Retrieved from http://blogs.loc.gov/digitalpreservation/2014/02/what-do-you-mean-by-archive-genres-of-usage-for-digital-preservers/
Pennock, M. (2013). Web archiving. Retrieved from http://dx.doi.org/10.7207/twr13-01
Public Knowledge Project. (2014, June 3). Announcing forthcoming PKP LOCKSS PLN. Retrieved from https://pkp.sfu.ca/announcing-forthcoming-pkp-lockss-pln/
Reed, S. (2014, June 5). Introduction to Umbra. Retrieved from https://webarchive.jira.com/wiki/display/ARIH/Introduction+to+Umbra
Rosenthal, D. S. (2010a). How green is digital preservation? Retrieved from http://www.digitalpreservation.gov/meetings/documents/othermeetings/Rosenthal.pdf
Rosenthal, D. S. (2010b). How are we ensuring the longevity of digital documents? Retrieved from https://www.youtube.com/watch?v=h53DMtBUxsk
Rosenthal, D. S. (2011, August 22). Moonalice plays Palo Alto. Retrieved from http://blog.dshr.org/2011/08/moonalice-plays-palo-alto.html
Scott, K. (2010, March 5). Archiving Britain’s web: the legal nightmare explored. Wired Magazine. Retrieved from http://www.wired.co.uk/news/archive/2010-03/05/archiving-britains-web-the-legal-nightmare-explored
Taylor, N. (2011, June 6). Web and Twitter archiving at the Library of Congress. Retrieved from http://eventsarchive.org/sites/default/files/webandtwitterarchivingatthelibraryofcongress-110614202159-phpapp01.pdf
University of Alberta Libraries. (2013). University of Alberta Libraries web archiving policy. Retrieved from http://www.library.ualberta.ca/aboutus/collection/policy/Web%20Archiving%20Policy.pdf
Van de Sompel, H. (2012). SiteStory transactional web archive software released. D-Lib Magazine, 18(9/10). Retrieved from http://www.dlib.org/dlib/september12/09inbrief.html
Webber, J. (2014, June 12). How big is the UK web? Retrieved from http://britishlibrary.typepad.co.uk/webarchive/2014/06/how-big-is-the-uk-web.html
About the Author
Corey Davis has been with the University of Victoria since 2012, where he works as Systems Librarian. He has a particular interest in the long-term preservation of born-digital materials. Prior to joining UVic, he was head of Technical Services at Royal Roads University Library.

Andy Jackson, 2014-11-04
Great article. Just a minor correction – we (The British Library) do not run the UK Government Web Archive. The National Archives of the UK does that. Thanks.