by Rico Simke
Background
The more libraries become interconnected the more important the question of data integrity becomes. Correcting metadata and improving their quality may facilitate identification of bibliographic records and will increase data integrity. Applications that handle large amounts of data, e.g., bibliographic metadata, are in need of automation. However, automation can be difficult to achieve and may even make results more complicated, because automatic collection and aggregation of metadata can produce a data set more faulty than the original one that then needs correction by an expert user, e.g., a librarian. Another possibility, however, is to leave the responsibility of creating metadata for a record to the librarians but to let them be guided by the existing metadata.
Bibliographic work normally is a highly manual task: a librarian holds a book in their hand and either creates a new dataset by inserting metadata information into a database or tries to match it to pre-existing data in some catalog. Newer approaches try to incorporate the FRBR [1] schema into the organization of bibliographic datasets. However, OCLC research shows that automatic organization of metadata with respect to the FRBR schema is not possible and that automatic matching – especially for records without author and/or uniform title – is a difficult task [2].
The need for a tool that can overcome these difficulties and assist its users arose within a concrete scenario of research work. The ESF-funded project Library of a Billion Words [3] is a digitization infrastructure project for primarily Greek and Latin editions from the 19th and 20th century. In order to store the documents and make them usable for researchers in the humanities, the project will provide a repository with high-quality scans. Ultimately, the project aims to create a digital citation infrastructure.
The Library of a Billion Words project depends on high-quality metadata in order to be able to build a persistent, searchable catalog and infrastructure for digitized books. The project’s primary source of scanned documents is the Internet Archive [4] (IA), which provides basic metadata information for every document. That metadata is, however, mostly insufficient for building such an infrastructure. A typical metadata file from the IA catalogs author and title, along with technical information about the scanning process. To improve the data it is possible to search catalogs all over the web for the concerned record. However, the problem of keeping track of and choosing the correct metadata for a digitized object is a recurring problem in the project. There is no place where users of the infrastructure can collect metadata from different sources and view them in direct comparison with each other. An application is needed where the potentially large amount of metadata can be joined and displayed in a comprehensive and user-friendly way. Furthermore, users should be able to create a new record by combining the displayed metadata.
The intention of the project is to combine metadata from sources like the Perseus Catalog [5] and the catalog of the Leipzig University Library (LUL). It appears that it is not possible to match records from these sources automatically, using identifiers from the Internet Archive record files. Similar records can have different identifiers, such as OCLC numbers, when they belong to different items or manifestations. This is why in the majority of cases a record in the LUL catalog can not be identified by the OCLC number provided in the IA metadata. Hence, further OCLC numbers are generated that are likely to be related to the record in question. Additionally, the fact that only about 40% of the Archive.org metadata used in the project contain OCLC identifiers from which additional metadata for a record can be derived makes it impossible for these records to have any kind of automatic metadata retrieval.
Thus, the key components of our solution are a web-based, user-friendly front-end with import and export options and a sleek interface for displaying and combining large amounts of metadata for a single record in a table view. Besides scans from the IA, the project intends to include editions that are already available in and indexed by the Leipzig University Library catalog in its repository. In the event that here too the metadata is insufficient, the tool can be used to improve the data with the help of other sources such as the WorldCat [6] or the Perseus Catalog.
Approach
Starting from the question as to how metadata from different sources can be combined in such a way that its high quality is ensured, our basic approach is to make a front-end available that has an intuitive user interface and visual guidance combined with a central database for all metadata connected to a certain edition. The editions are derived from, e.g., a scanned document or book. The idea behind this tool is to enable the user to put an adjusted metadata record together in a convenient way.
Our approach is new in the way it uses metadata as a starting point for a cataloguing task. The process can be started with only one identifier, such as an OCLC number or title-author combination. The tool can be used to collect as much metadata as possible from identifiers or from other search activities. This makes sense in light of the fact that, in a digital library, one often does not have the physical item at hand but only has a combination of metadata available.
The tool is designed to enable the user to search through and store metadata from different sources. The stored metadata can be analyzed and compared with other metadata, and a new record can be built by combining entries and can subsequently be exported.
MARCXML and Metadata
When collecting and comparing metadata, all of it has to be available in the same format. Among all available bibliographic formats, MARC21 proves to be best for collecting and creating metadata. It is the most-used standard worldwide and can be generated from Dublin Core [7]. To simplify parsing and handling the data, the format of choice is MARCXML[8], which is MARC21 in XML markup. Most sources natively export metadata as MARCXML and there is no loss of information when transforming metadata from e.g., MODS to MARCXML. The hierarchical structure of MARCXML is suited for displaying in a table, as will be shown when we discuss the tool’s grid view.
The following is a short overview of the metadata types used as sources for the project. The tool itself is organized in a modular fashion, which means that it takes few programming skills to include additional sources. The user only needs a web service that provides metadata when given an identifier – e.g., MARCXML for a given library identifier.
Archive.org
The majority of scanned documents are obtained from the Internet Archive. These documents come with very sparse metadata and need to be improved before they are of use to the project.
A study of metadata files from the Internet Archive displays the following distribution of identifiers.
- total number of files: 2,194,251
- oclc-id: 800,870 / 2,194,251 : 36%
- identifier-bib: 382,132 / 2,194,251 : 17%
- google-id: 162,809 / 2,194,251 : 7%
Out of a total of about two million metadata files, only 36% have OCLC identifiers. In total, about 55% of the metadata files contain at least one of the three identifiers.
OCLC control numbers
OCLC control numbers are worldwide record identification numbers, hosted centrally in the WorldCat catalog, which is administrated by OCLC. WorldCat is the world’s largest online catalog and therefore is a good source of metadata. If an OCLC number is available, one can easily get the metadata provided as MARCXML for that particular record via WorldCat.
xOCLC Service
xOCLC is a web service that delivers a list of similar OCLC numbers, when given an OCLC number as input. The xOCLC service is supposed to deliver records that are related to the item identified by the given OCLC number. This goal was formulated by Thom Hickey in 2005:
xOCLC: take in an OCLC number and return the OCLC numbers in its FRBR work-set [9]
Currently, the service does not provide any information on the type of relation between two OCLC numbers in an xOCLC request. The tool uses the getEditions [10] method to obtain a list of related items, and stores them as a list of numbers affiliated with an edition.
Perseus Catalog
Some of the research in the Library of a Billion Words project is in collaboration with the Perseus Catalog project at Tufts University. The Perseus Catalog is part of the Perseus Digital Library and aims to “create a catalogue that would provide coverage of Greek, Latin, and ultimately other literatures in a way that was suitable to a digital age.” [11] This makes it an ideal source for enriching metadata in the Library of a Billion Words project. The metadata in the Perseus Catalog is organized to try to reproduce the FRBR schema for its records. This means that metadata is enriched with information about related items, such as host editions of works. This information is preserved in the metadata tool, since at a later stage it will be important for the project’s catalog infrastructure. Since metadata from the Perseus Catalog, provided in the MODS format, can be transformed into MARCXML, it can be imported to this tool.
finc – Leipzig University Library catalog
Since the Library of a Billion Words project is based at Leipzig University, the metadata tool integrates an interface to the Leipzig University Library catalog, finc [12]. In the tool, all OCLC control numbers that have been retrieved via the xOCLC service can be automatically queried in the finc catalog. If an OCLC number is found in the finc catalog, the associated MARCXML record is stored in the database and connected to the corresponding edition.
The Application
The application is written in Ruby, using the Ruby on Rails framework with a MySQL database for metadata storage. In the database every edition is connected with a number of metadata entities. The user can take different approaches to importing metadata. The first is a simple upload of a MARCXML record to the metadata tool from the user’s machine. The second is to provide an Internet Archive identifier, for which the corresponding metadata is retrieved automatically by the tool. The third is to provide an OCLC number for which a WorldCat record and its metadata can be obtained.
The following subsection outlines a typical workflow when adding a new document.
Workflow
The normal workflow is as follows: the user starts by creating a new empty edition in the metadata tool. The new edition is identified by a name or any other kind of identifier. As a start, that edition exists only in the tool and is not yet assigned to any edition outside of it, e.g., in the Library of a Billion Words infrastructure. The user can then choose the metadata sources that they want to be included in the new edition. If a record is not in the MARCXML format originally, it will be transformed, e.g., records from the Perseus Catalog, which are supplied in an embedded MODS-format, will automatically be transformed to MARCXML. If the user chooses to add an OCLC number, the metadata for that number will be fetched and the user can then submit an xOCLC request to add further metadata to the edition. All MARC records are stored in the database, and different types of associations define which metadata records are assigned to an edition.
Once the user has finished collecting metadata, they can enter the grid view to compare and choose an edition’s metadata.
The grid view
In the grid view all source records assigned to a certain edition are displayed in a table, together with their metadata. The leftmost column contains the new record that is built. That column remains empty until the user selects metadata from other source records or types in adjusted metadata. The second-left column labels the MARC21 field-subfield combination. The third column provides statistical information on the metadata contained in each row (see Screenshots 1 and 2). The remaining columns represent the different source records, with the metadata to be compared – one column for every source record. The rows in the table represent the MARCXML fields. Each row is again divided into subfields.
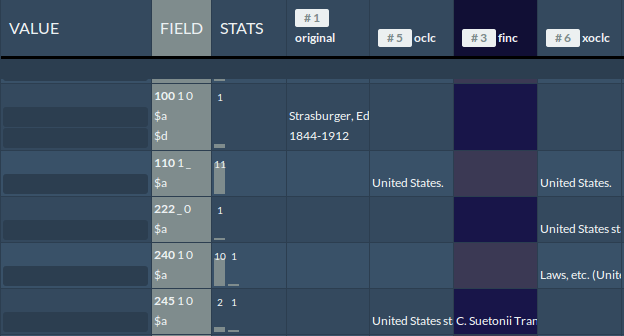
Screenshot 1: Grid view
Each field-subfield combination is displayed at least once. If two or more sources share a field-subfield combination, the data is displayed in the same row. Metadata that share the same field but differ in their subfields are displayed in different rows, e.g., two sources sharing the field 245 1 0 $a share the same row for that combination of fields, whereas any source with the fields 245 1 0 $a $b would have its metadata displayed in a different row.
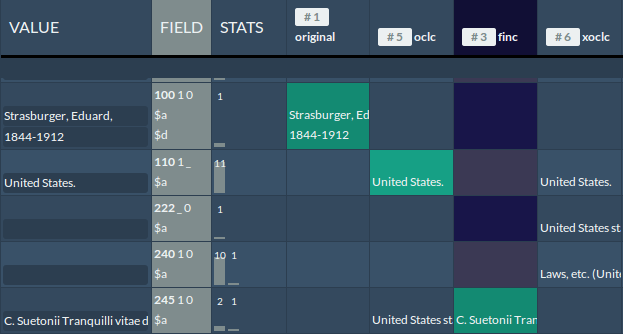
Screenshot 2: Grid view with selected values
Metadata fields within sources that do not share a certain field-subfield combination are left empty.
For every field, the user can select values from a certain metadata record or enter their own values, e.g., if the values are incorrect or if the required values are not available (Screenshot 2).
The tool guides the user in finding the correct metadata by displaying statistical information about all collected metadata. This is achieved with two different types of statistical information: first, for every MARC field the five most prominent values and their quantity, i.e., number of appearances of the same value, are displayed. The idea is that more frequently occurring content is more likely to be correct for the corresponding field. The user can hover over the bars to view their values as a tooltip, and to highlight source records that contain these values (Screenshot 3).
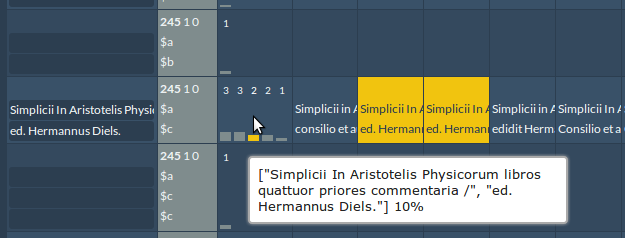
Screenshot 3: Grid view with statistics and activated hover feature
Second, all fields are compared with regard to their relative frequency in all source records (Screenshot 4). The underlying idea is that a more frequently occurring field is more important to a cataloguer than a less frequently occurring one. This helps the cataloguer to instantly see the distribution of MARC fields in all source records. The frequency of the metadata is displayed as a bar chart:

Screenshot 4: Total share in all data sets for every MARC21 field
Other Metadata Standards
This tool was primarily designed for working with MARCXML and its particular way of structuring metadata. In its current version, the tool cannot yet handle metadata standards with a different structure. However, as shown above, it is straightforward to, e.g., transform MARCXML to MODS or vice versa. Thus, it is possible to integrate more classes of bibliographic metadata, as long as they can be transformed to MARCXML.
Future Work
A question that arises with regard to future work is the handling of identifiers. Each source delivers a different type of identifier. Records that derive from WorldCat are typically identified by an OCLC number in field 001. MARCXML records extracted from the Internet Archive have a different type of identifier (e.g., operarecensuitri10libauoft) in that field. Since each operation in the tool can lead to a new dataset, it would be inconsistent to simply apply one of these identifiers to the newly created record. Therefore, we need a solution as to how to create new identifiers for new records. However, taking care of these difficulties and creating rules for processing identifiers has to mainly be the responsibility of the end-users, within their concrete use cases.
To make Mdmap more convenient, better integration of catalog search functionality into the tool is needed – e.g., to provide search directly in the finc catalog or WorldCat, from within the application. Additionally, performance of the grid view needs to be improved.
Scalability of the tool presents another issue. In the Library of a Billion Words project, the tool is intended to store and connect millions of metadata records. However, we have not yet tested the tool under such realistic circumstances. Given the fact that in a typical use case the user needs to find a certain record in a collection of millions of editions, a logical first step is to integrate more effective search technologies, such as Solr, into the tool.
In our project, the Library of a Billion Words, we intend to make the tool available to librarians with practical experience working with MARC records, to help them clean up metadata for editions incorporated into the Library of a Billion Words text repository that are believed to have insufficient metadata available. At this point, the tool is still in an experimental stage of development and has not yet been tested by expert users. It has, however, been presented to librarians at the Leipzig University Library, whose feedback has been taken into consideration during further development of the metadata tool.
Conclusion
We proposed a new approach to bibliographic work, and presented a tool that can handle metadata from a large amount of sources. Anyone interested in Mdmap is strongly encouraged to download and test the tool [13].
Acknowledgements
Parts of the work presented in this paper are the result of the project Die Bibliothek der Milliarden Wörter. This project is funded by the European Social Fund. Die Bibliothek der Milliarden Wörter is a cooperation between the Leipzig University Library, the Natural Language Processing Group at the Institute of Computer Science at Leipzig University, and the Image and Signal Processing Group at the Institute of Computer Science at Leipzig University. ![]()
Notes
[1] http://www.ifla.org/publications/functional-requirements-for-bibliographic-records
[2] http://www.oclc.org/research/activities/frbralgorithm.html
[3] http://asv.informatik.uni-leipzig.de/en/projects/30
[5] http://catalog.perseus.org/
[7] http://www.loc.gov/marc/dccross.html
[8] http://www.loc.gov/standards/marcxml/marcxml-design.html
[9] http://outgoing.typepad.com/outgoing/2005/05/xisbn_extension.html
[10] http://xisbn.worldcat.org/xisbnadmin/xoclcnum/api.htm#geteditions
[11] http://sites.tufts.edu/perseuscatalog/documentation/history-and-purpose/purpose/
[12] https://katalog.ub.uni-leipzig.de/
[13] https://github.com/ubleipzig/mdmap
References
Hickey, Thomas B., Edward T. O’Neill, & Jenny Toves. (2002). Experiments with the IFLA Functional Requirements for Bibliographic Records (FRBR). D- Lib Magazine 8, 9 (September).
Zeng, M. L., & Qin, J. 1. (2008). Metadata. London: Facet.
About the Author
Rico Simke (simke@ub.uni-leipzig.de) is a Research Associate in the project Library of a Billion Words at Leipzig University Library and a PhD student in the Natural Language Processing group at the Department of Computer Science (Leipzig University).

Subscribe to comments: For this article | For all articles
Leave a Reply