by Carol Jean Godby, Devon Smith and Eric Childress
1. Who uses interoperable records?
The winters are gloomy in Columbus, Ohio, so Susan decides to take an online course on memoir writing. After reviewing one of her homework assignments, her instructor emails her late one night with the recommendation that she take a close look at how Homer Hickam, in his celebrated book Rocket Boys, manages to craft gritty but lyrical descriptions of his boyhood home, a coal mining town in a remote valley of West Virginia in the 1950s. Susan needs this book tomorrow morning, so she wonders if she can get the book from a nearby library. She goes to WorldCat.org [1] and types the title into the search box. The top-ranked result shows that the book is available from Worthington Public Library, just ten miles away from her house.
This paper describes one component in a complex process that enables WorldCat.org to deliver information like this to library patrons. How does this service, which can be accessed from the Internet anywhere in the world, recognize that a library close to Susan has the book she wants?
At the start of the process, third-party jobbers obtain orders from a collection of libraries, which they fill by placing a bulk order to an online bookseller. The Worthington Library’s copy of Rocket Boys and the other books in the same order are located and shipped from the bookseller’s warehouse using the information in a record coded in ONIX [2], the relatively new but emerging de-facto standard for descriptions of materials handled by the publishing industry. The jobber’s order is also sent to OCLC to determine whether it can be matched with the corresponding MARC [3] records in the WorldCat® database [4]. A software module translates some of the elements in the ONIX record to MARC and searches for it. Since Rocket Boys has already been cataloged, the WorldCat record is updated with a flag indicating that the book will soon be held by the Worthington Public Library. WorldCat.org now has the essential information required to connect Susan with her book.
2. Translating bibliographic metadata: a short progress report
The above scenario is an example of how the library community interacts with publishers to deliver value to patrons. The workflow isn’t particularly complex, nor is the relationship between libraries and publishers especially problematic because the negotiations are about well-understood resources that must simply be transferred from one community to another. Nevertheless, the achievement of this goal requires that two descriptive standards be synchronized. Both are sophisticated. Both are entrenched in their respective communities of practice and both are necessary because they annotate the outcomes of events involving the book in two different contexts. The ONIX standard originated from the need to identify and track books as they are bought and sold. The transaction typically involves a bookseller Web site such as Amazon.com, which links a physical item to a machine-readable description and associates it with ancillary materials, including web sites, study guides, cover art, tables of contents, reviews, or digitized pages, all used to create a rich context for interacting with the book before and after a purchase. The MARC standard evolved from the need to create an authoritative description establishing the authorship, subject, and provenance of a work that can be interpreted as an archival record with many anticipated uses in the library community. The MARC record has relatively few links to commercial transaction data or to elements required to populate a given Web site, while the ONIX record is less rich in links to name and subject authorities. But the two descriptions are not incompatible.
2.1. The crosswalk.
In fact, there is considerable overlap because the ONIX and MARC descriptions of Rocket Boys refer to the same book. But it takes the effort of an expert familiar with the formal specifications as well as the normal use cases of both standards to tease out the commonalities and record them, typically in a table of correspondences called a crosswalk [5], such as a sample of the ONIX-to-MARC mapping maintained by the Library of Congress [6] shown in Table 1:
| Title composite <Title> The Title Composite contains the text of a title, including a subtitle when necessary. |
||
| <b202> | <TitleType> | (Used to set field 246 2nd indicator: If b202 = 00, 246 I2 = #; if b202 = 01, 246 I2 = 2) |
| <b276> | <AbbreviatedLength> | |
| <b203> | <TitleText> | 246 $a |
| <b030> | <TitlePrefix> | 245 $a |
| <b031> | <TitleWithoutPrefix> | 245 $a |
| <b029> | <Subtitle> | 245 $b; 246 $b |
Table 1. A fragment of an ONIX to MARC crosswalk
If the goal is to share records between libraries and publishers, clear correspondences between ONIX and MARC must be established among elements that identify authors, titles, publishers, dates of publication, numeric identifiers, editions, physical formats, summaries, tables of contents, or subjects. It is less clear what to do with descriptions of the bundled items, such as associated Web sites and user reviews that can have their own complete bibliographic descriptions. But the easy correspondences are good enough to conduct much of the day-to-day work in digital libraries and library support organizations, including record creation, normalization, and enhancement; database searches and retrievals; and the automatic generation of rough drafts for archival records that would be completed by human experts.
Nevertheless, we have discovered that even the slightest incompatibilities among record formats produce huge backlogs that translate to unfulfilled queries from users. Consider a few elements from some of the major standards for representing bibliographic information that name primary book titles. In the MARC to Dublin Core crosswalk, 245 $a maps to Dublin Core (DC) title, a relationship that persists through XML, ASN.1/BER[7], RDF [8], and various standard or non-standard human-readable displays. It also persists through multiple versions and editions of both standards, such as OAI-PMH Dublin Core [9], MARC-XML [10], MARC 2709 [11], and Versions 1.1 and 1.2 of Unqualified Dublin Core (or DC-Simple) [12], as well as Dublin Core Terms [13] (or Qualified DC). The MODS standard can also be reasonably added to this mix. MODS [14] is a slight simplification of MARC designed for the description digital library resources, whose title concept, <titleinfo><title>, is also mapped to 245 $a and DC:title, according to crosswalks available from the Library of Congress. MARC 245 $a also maps to several ONIX elements, among them <DistinctiveTitle>. In addition, crosswalks are being developed between Dublin Core and ONIX, which maps DC:title to <DistinctiveTitle>.
In sum, crosswalks exist between MARC and Dublin Core, ONIX and MARC, ONIX and Dublin Core, MODS and MARC, and MODS and Dublin Core. For a single concept, perhaps corresponding to an educated layman’s understanding of title, the relationships among the standards are consistent and easy to implement. But in its current form, this information is difficult to use for automated processing. It requires corresponding technical resources such as XML schemas and XSLT scripts, which are all too often unavailable, broken, or obsolete. The relative scarcity of machine-processable files implies that it is difficult to transform this content into an executable format and maintain it. But perhaps we need to acknowledge that the antecedent step of intellectual analysis is also difficult. It is a nontrivial task to determine whether existing crosswalks are sufficient to perform a translation, or how they can be modified or enhanced. If crosswalks need to be developed, they are often created from scratch even though they might be algorithmically derived. These problems imply a need for a better formal model of the crosswalk: a model that makes it easier to do the intellectual analysis, one that more closely associates the executable files with the analysis, and one that encodes a realistic proposal for managing different versions and encodings of standards.
2.2. Toward schema-level interoperability.
Using the terms defined in Chan and Zeng’s progress report on interoperability [15,16], the problem we have defined is in the scope of schema-level interoperability because we are trying to identify the common ground among formally defined metadata schemas independently of the short-term need to process instance records. But our goal is a conceptual framework that will make this job easier because we want a solution that can be reused for different kinds of tasks and applications.
Chan and Zeng identify several conceptual objects that have emerged from the effort to achieve this kind of interoperability. In addition to the crosswalk, which is the focus of our work, they also describe derivations, switching-across schemas, and application profiles, all of which have a place in the solution outlined in subsequent sections of this article. A derivation results when a new schema is created from an antecedent, as when MODS was derived from MARC to create a standard that is more appropriate for software systems that manage descriptions in digital library collections. A switching-across schema is a common format, which we call an interoperable core in a hub-and-spoke model [17], into which multiple schemas can be mapped to create a highly efficient processing model. And an application profile is a hybrid schema that is created by combining elements from more than one schema, observing certain restrictions on how they are used [18]. Application profiles achieve interoperability by reusing elements defined in existing schemas and creating new elements only when necessary. For example, Dublin Core Terms is an application profile that extends the Dublin Core Element set with a rich set of vocabulary for describing relationships, dates, and audience levels, among other concepts.
Crosswalks, derivatives, hub-and-spoke models, and application profiles respond to the need to identify common ground in the complex landscape of resource description. But these objects also imply an unresolved tension between the need to minimize the proliferation of standards and the need to create useful machine-processable descriptions of resources. We concentrate on the crosswalk, partly because of the institutional and technical context of our work, but also because we are primarily interested in devising reusable solutions by identifying and exploiting the common ground in metadata standards. But we also believe that the crosswalk is more fundamental because it underlies two of the objects that Chan and Zeng describe: the derivative, which requires a crosswalk to map elements from the parent schema to the child; and the hub-and-spoke model, which requires a crosswalk to map related schemas to an interoperable core.
But the crosswalk is built up from an even more fundamental unit of analysis: a single element defined in a standard, such as title in Dublin Core, MARC, MODS, and ONIX. Like words in a natural language, metadata elements can be extracted from one context and combined into new ones, forming application profiles. They can also enter into semantic relations, such as the equivalences defined by crosswalks, which resemble synonymy. When the focus is on the element, Chan and Zeng’s schema-level interoperability reduces to the problem of element-level interoperability, whose technical infrastructure is a baseline on which more comprehensive systems can eventually be built. And as our opening scenario shows, commercially useful work can be done here, work that is now being done redundantly and wastefully, if at all.
Here we describe a generic computational model that permits someone with an expert’s knowledge of the metadata standards used in libraries, museums, education, the publishing industry, or other contexts that have well-defined data models, to develop executable translations by creating a list of equivalences that looks like the crosswalk shown in Table 1. The model is structured so that the standards expert can concentrate on mapping equivalent elements, letting the software handle the messy details that emerge from multiple structural realizations, such as those that come up when the title concept is identified in MODS, MARC, Dublin Core, and ONIX. Because the model closely resembles the human-produced mappings, relatively little programming is required to make this data actionable—in fact, the process of converting crosswalks to executable code can be largely automated. Once the system is seeded with the most important crosswalks, it can run with minimal human intervention. Only minor tweaks are required to add new standards or accommodate new versions or translations.
The system described below is the core logic of the Crosswalk Web Service, which represents an outcome of the research program first reported in Godby, Childress and Smith [17], and Childress, Godby and Young [19] and is currently being used to power the metadata crosswalking facility in OCLC Connexion®, as well as many offline services that process larges sets of records. A publicly accessible demo will soon be available from OCLC’s ResearchWorks page [20].
The Crosswalk Web Service is part of a larger effort to re-engineer OCLC’s products as a collection of modular, configurable services for harvesting, validating, enhancing, and manipulating descriptions of resources, many of which are engineered from Open Source software and exposed through Web service interfaces. The result is an architecture that reduces internal duplication of effort and exposes critical functionalty to any partner, client, or member that recognizes a common set of standards and can be accessed through an Internet connection.
3. A process model for record translation
Figure 2 depicts the major steps in the Crosswalk Web Service process model. It is designed to separate the semantics from the syntax of the translation task, from which many desirable consequences follow, including reusable components and simplified translation scripts, as we argue below. But the most important consequence is that the task of creating and interpreting crosswalks remains abstract, so the metadata subject matter expert can concentrate on defining mappings without getting bogged down by complex structural detail. We will illustrate the process by walking through the translation of a simple description of Rocket Boys that starts out as an ONIX record (shown in Figure 5).
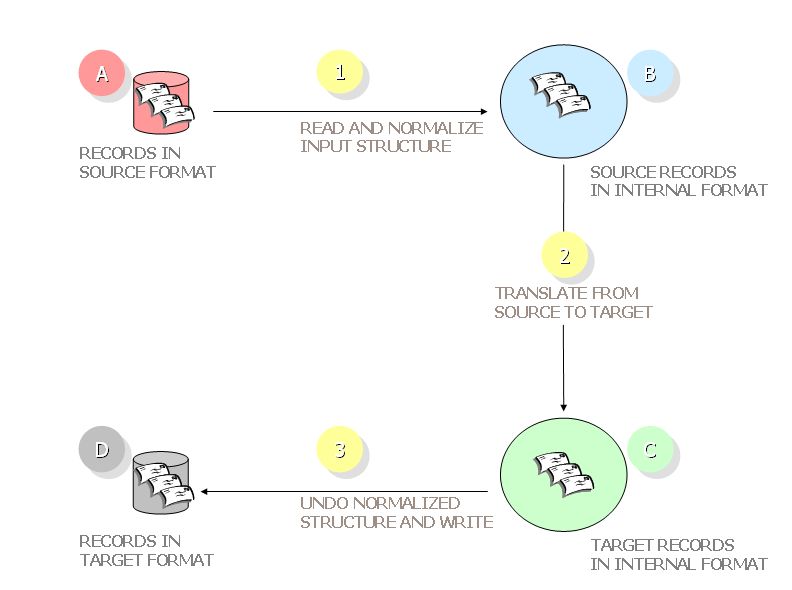
Figure 2. The translation model [View full-size image]
3.1. A brief overview.
Input records conforming to the source metadata standard at State A are converted to a common XML structure at Step 1 and are then translated to the semantics of the target metadata standard at Step 2. The result of the translation is a set of normalized XML records at State C, which are converted to the native structure of the target metadata schema at Step 3, producing output records at State D. Only the first and last steps of the translation model have access to the syntactic details of the native standards. In the internal Step 2, the translation operates on a common, locally defined structure.
3.2. Step 1: Reading the input.
A utility program, informally called a reader, converts an input metadata record to the internal structure required by the translation software in our model. This structure is an XML container we have named Morfrom, whose document type definition contains four elements: record, the top-level element; header, which identifies a default namespace for the record and links to a resource containing a definition of the elements that populate it; field, whose name attribute identifies an element in the native standard; and value, which defines a path to the data. The field elements preserve the element order, sequence, and hierarchical structure, while the name attributes on field preserve the names of the elements in the native record. Finally, the value elements enclose the unique data in the record.
Figure 3 shows the result of running the ONIX reader on our sample record. As shown, this record contains author, title, and subject elements that will be translated. By convention, Morfrom records are designated with the .mfm suffix.

Figure 3. The input record in native ONIX syntax and Morfrom [View full-size image]
3.3. Step 2: The translation.
The key component of the processing model is Step 2 in Figure 2, where the translation takes place. The translation process has two inputs: the translation logic, and a Morfrom-encoded record in the source metadata standard, i.e., the record containing ONIX elements shown in the bottom portion of Figure 3.
The translation logic is written in an XML scripting language we have designed and named Seel, an acronym for Semantic Equivalence Expression Language. It is processed by a custom-written interpreter, which performs the essential function of XSLT or other easily written scripting languages, but represents a computational model of the crosswalk that keeps the defining feature, the assertions of equivalence, in the foreground. The Seel language specification and interpreter bear some resemblance to the Jumper package [21], but Seel has more features for expressing fine-grained details of conditional translations, some of which we describe below.
Figure 4 shows a complete Seel script that can process everything but the subject elements in the sample input, which are treated in Figure 5. A Seel script is enclosed in the <translation> element, which has two children. The <header> specifies the metadata standards in the source and target of the translation. One or more <map> elements follow, each of which contains roughly the same information as a row in a crosswalk: an element defined in the source metadata standard and the equivalent element from the target. Like a row in a crosswalk, a Seel map is modular, self-contained, and abstracted away from the native syntax of the standard. And like a crosswalk, a Seel script can either be lightweight or comprehensive, depending on how many maps it has. The script in Figure 4 maps ONIX <Title><TitleText> to MARC 245 $a and the first occurrence of ONIX <Contributor><PersonName> to MARC 100 $a.
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- dc:source = http://www.loc.gov/marc/onix2marc.html -->
<translation>
<header>
<sourceschema name="onix" namespace="uri:ns:onix-book:2.1"/>
<targetschema name="marc" namespace="uri:ns:marc:21"/>
</header>
<map id="1">
<source>
<mainpath>
<branch><step name="Title"/><step name="TitleText"/></branch>
</mainpath>
</source>
<target>
<mainpath>
<branch><step name="245"/><step name="a"/></branch>
</mainpath>
</target>
</map>
<map id="2">
<source>
<mainpath>
<branch><step name="Contributor" position="1"/><step name="PersonName"/></branch>
</mainpath>
</source>
<target>
<mainpath>
<branch><step name="100"/><step name="a"/></branch>
</mainpath>
</target>
</map>
</translation>
Figure 4. A simple but complete Seel script
In more technical terms, Seel maps the elements that might correspond to a concept of title in the two standards using the information in the Seel <mainpath><branch> element, which identifies a path in the source record and constructs an equivalent path in the target. Once the paths are aligned, the data involved in the translation is transferred from the markup of the source to that of the target. To accomplish this task, Seel has a path language that can refer to any location in a source record encoded in Morfrom. Each Seel element <step name=’abc’> picks out a Morfrom element <field name=’abc’> and defines one step on a path from the record root to the data. For example, the effect of the first Seel map in Figure 4 is to locate the fragment <field name=’title’><field name=’titleText’> in an ONIX-tuned Morfrom record and construct the path <field name=’245′><field name=’a’> in the corresponding Morfrom MARC record.
Figure 5 shows the Seel map for the subject elements. It is separated out here for the sake of discussion, but in our production environment it would be appended to the other maps in Figure 4 to create a single ONIX-to-MARC script. This map is more complex than the maps in Figure 5 because it has a conditional. Its effect is to map the ONIX <subject><SubjectHeadingText> element to a Library of Congress Subject Heading in MARC 650 $a if the ONIX source has a sibling <SubjectSchemeIdentifier> whose value is 4, the ONIX code for LCSH in this context. This map also builds a MARC i2 field and populates it. All of this work is done by the <context> element, which has two essential sub-elements: a <path>, which describes a path relative to path described in the corresponding <mainpath> element; and a <value>, which contains data.
In the <source>, the <context> element implements the ‘if’ part of the statement given above by locating the subtree containing the ‘4.’ The ‘from’ attribute on the <path> uses the standard UNIX subdirectory idiom to address any path in the record, and here specifies that <SubjectSchemeIdentifier> is a sibling of <subject><SubjectHeadingText>, which can be verified by checking the Morfrom record shown in the bottom portion of Figure 3.
A <context> can also appear in the <target>, where it is interpreted as an instruction to build an additional path, a child of the root defined in <mainpath>. In the map shown in Figure 5, the <context> element is used to create an indicator element and assign appropriate data to it, resulting in the <field name=’650′> element shown in the Morfrom record in the top portion of Figure 6. The map shown in Figure 5 is actually a fragment of a larger map that would build MARC subject elements with different tag names and internal structures depending on whether the ONIX SubjectSchemeIdentifier code is LCSH, MESH, or a publisher’s unique scheme. In the full script, there would be multiple <branch> and <context> elements, which would be bound to one another with the branch id (‘bid’) attribute. But a single branch is sufficient to translate the sample record.
<map id="3">
<source>
<mainpath>
<branch bid='1'><step name="subject"/><step name='SubjectHeadingText'/></branch>
</mainpath>
<context bid='1'>
<equals>
<path from= '..'><step name='SubjectSchemeIdentifier'/></path>
<value>4</value>
</equals>
</context>
</source>
<target>
<mainpath>
<branch bid='1'><step name='650'/><step name='a'/></branch>
</mainpath>
<context bid='1'>
<equals>
<path><step name='i2'/></path>
<value>0</value>
</equals>
</context>
</target>
</map>
Figure 5. A Seel map with a context
3.4. Step 3: Writing the output.
The output of the translation is a second Morfrom record containing elements defined in the target metadata standard. The Morfrom MARC version of Rocket Boys is shown in the top portion of Figure 6. To complete the translation process, the record must be converted to the syntax of the output by passing through a utility program called a writer. This happens at Step 3 in the translation model shown in Figure 2. Because the client requests ISO 2709 syntax in our example, the record is sent to the ISO MARC writer. The result is the record shown in the bottom portion of Figure 6. The Leader elements shown in the ISO record are defaults generated by our production system, but they can also be created by Seel maps when the need arises.
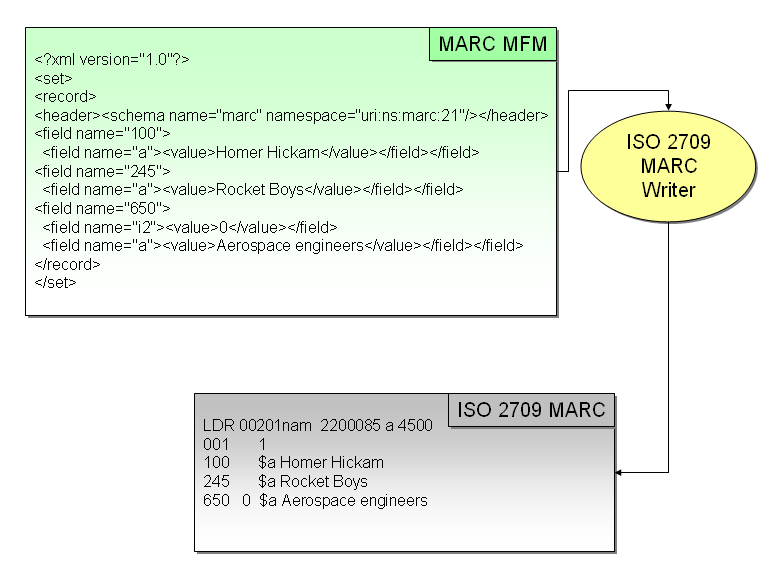
Figure 6. A Morfrom record written to ISO MARC [View full-size image]
3.5. Readers and writers: a recap.
We have walked through a simple example showing the translation of an ONIX XML input to a MARC ISO output to demonstrate that the Crosswalk Web Service model is flexible enough to handle XML, as well as non-XML inputs that are formally defined and consistent, a necessity in an unstable resource description environment such as OCLC’s.
The readers and writers invoked at Steps 1 and 3 require custom programming, but they repay the effort by delivering much-needed abstraction. These programs, typically written in Java, hide the complex and sometimes idiosyncratic details of hierarchical structure, element order, and internal element syntax from the rest of the model. And since these are the very details that are least likely to change as standards evolve, the readers and writers can be written once and reused extensively. The Crosswalk Web Service now has a collection of readers and writers that operate on or generate Morfrom MARC for ISO 2709 MARC, MARC-XML, MARC-8 [22], and locally designed MARC-like formats. Since these programs also make Java‘s library of character sets available to the translation model, the service performs hundreds of distinct conversions from one syntax and character encoding to another, a nontrivial accomplishment that, left unaddressed, results in a large backlog of unprocessed records in our production environment.
The syntactic normalization step also simplifies the translation. As Figures 3 and 6 show, the Morfrom representation eliminates many superficial differences between ONIX and MARC and hence the complexity of the rules required to map the two standards. And only one set of maps is needed because the readers and writers handle all structural variation. Thus the same map would work for MARC XML or MARC ISO-2709 to ONIX or Dublin Core Terms. This reusability comes at the expense of some extra processing when the native record syntax is XML, but the cost is minor, given the benefits.
3.6. The translation: Why not do it in XSLT?
This is a good place to contrast the Seel translation engine with the the most popular alternative, an XSLT stylesheet that translates directly from the source to the target. Figure 7 shows a fragment of an XSLT stylesheet that constructs MARC 100 1# $a from ONIX <contributor><PersonName> and does some of the same work as the Seel script shown in Figure 6 [23]. This example is derived from the ONIX-to-MARC stylesheet maintained by the Library of Congress [24], which we have simplified slightly for the sake of discussion.
<xsl:for-each select="contributor[PersonName]">
<xsl:call-template name="datafield">
<xsl:with-param name="tag">100</xsl:with-param>
<xsl:with-param name="ind1">1</xsl:with-param>
<xsl:with-param name="ind2">#</xsl:with-param>
<xsl:with-param name="subfields">
<subfield code="a">
<xsl:value-of select="."/>
</subfield>
</xsl:with-param>
</xsl:call-template>
</xsl:for-each>
Figure 7. Part of an XSLT stylesheet for the ONIX-MARC relationship
This stylesheet is a set of instructions for building a MARC XML record that contains properly formatted fields and subfields in the required MARC sort order. Accordingly, the instructions for building and populating the 100 field shown here are located in the full script between those that create the control fields and those for the higher-ranking variable fields in a valid MARC record. Since the record-building task is performed simultaneously with the record-translation task, the semantic elements that would be isolated and brought together in a Seel script are interleaved with statements that specify structural details. Compared to our model, an XSLT script like that shown in Figure 7 is far less abstract because it combines the work performed by a Seel script with that done by the readers and writers. Of course, an additional process would be required to produce non-XML output in a model that depends on XSLT to translate metadata records.
And unlike the corresponding Seel script, the XSLT stylesheet is inherently asymmetric because the source and the target paths to the data have qualitatively different encodings. The source path is defined using XSL XPath [25] elements, which identifies the ONIX tag of interest in Line 1 and transfers the data at that node to the target record in Line 8. But the target path is defined more simply by a set of hard-coded XML elements obtained from the target record specification. For example, Line 3 establishes the root of the target path by passing a value to an XSL template that produces the element <datafield tag=’100′>. Line 7 extends this path with the element <subfield code=’a’>, a relationship that is not explicitly labeled, as it would be in a Seel path statement, but is inferred from the fact that this line is executed immediately after Line 3. By contrast, a Seel map is unambiguous because everything is fully labeled with elements defined in the Seel document type definition.
Because a Seel map is explicitly labeled and symmetric, it can be algorithmically reversed by transposing the contents of the <source> and <target> elements. In the one-to-one maps shown in Figure 4, this relationship is perhaps obvious, but it is also true of the more complex map in Figure 5. In the reverse translation, a MARC 650 $a containing a second indicator with the value ‘0′ triggers the construction of the ONIX <subject><SubjectHeadingText> and builds a sibling <SubjectSchemeIdentifier> element with the value ‘4.’ We are still fine-tuning the reversibility feature of Seel, but it has already been helpful in the development and evaluation of round-trip translations.
4. Fine-tuning the translation step
Our walkthrough of the Crosswalk Web Service translation model in the previous sections featured a translation from ONIX to ISO 2709 MARC. This is one path through our system, but there are many others. To promote reusability, the Crosswalk Web Service implements a hub-and-spoke model, which sometimes requires two translation steps: one to map the input to a core format, and a second to map the core format to the desired output. In our model, a core format has no literal existence either as a software implementation or as a data structure. It is nothing more than an agreed-upon convention to write one set of Seel scripts with a common target (the to-scripts), and a second set with a common source (the from-scripts).
In a service designed to meet the needs of the library community, a core format based on MARC produces certain efficiencies. These savings are achieved because the translations are divided into to-MARC inputs and from-MARC outputs. When a new to-MARC input such as MODS is introduced, it has automatic access to the existing collection of all from-MARC outputs. As a result, once the collection of inputs and outputs grows even moderately, the hub-and-spoke model eliminates considerable programming effort. For example, the baseline version of the Crosswalk Web Service has the following outputs: four syntactic encodings of MARC and locally defined MARC-like extensions, five versions and two syntactic encodings of Dublin Core, two versions of MODS, and one version each of ONIX-Books and ONIX-Serials. When we added the MODS-to-MARC input, all of these outputs became available, even translations from MODS to ONIX and MODS to Dublin Core Terms, for which metadata experts have attempted to write crosswalks, perhaps unnecessarily, because many of the relevant mappings can be inferred.
This model can easily cut through the problems surrounding the translation of title we discussed in Section 2. Figure 8 shows a hypothetical hub-and-spoke translation model that maps a single element and depicts the syntactic encodings, represented as black tabs, that would be handled by the readers and writers. In all, just six maps would be required: three to-MARC maps and two from-MARC maps. But the model can handle 49 different combinations of inputs and outputs that could be found in a request to translate a set of metadata records to a target standard and encoding.
Of course, the full Crosswalk Web Service has a collection of comprehensive scripts that map hundreds of elements. But Figure 8 would accurately depict the mapping relationships in the full system if all references to the ‘title’ elements were omitted.
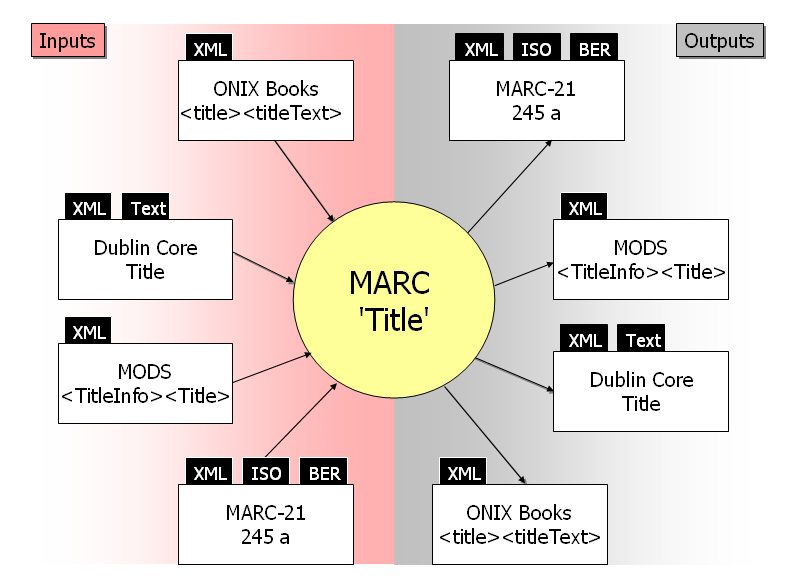
Figure 8. A hub-and-spoke translation model for the ‘title’ concept. [View full-size image]
Inefficiencies result from thinking about the metadata mapping problem in terms of pairwise translations that would have to be written for every input and output format, each of which requires a corresponding crosswalk—for example, MODS to MARC 2709, MODS to MARC-XML, MODS to ONIX Books, and so on. In this model, software cannot be reused as the collection of translations grows. Our model is more efficient because it separates the semantics of the problem, the assertions of equivalence between pairs of elements—from the syntax, a potentially large variety of structural realizations that must be decoded at the start of the process and reassembled at the end.
5. Seel maps in a persistent resource
A set of Seel maps renders a crosswalk into a computable form through statements in a declarative language. The relationships of interest are assertions of semantic equivalence, which represent the judgment by metadata standards experts that pairs of author, title, and other elements in two standards are synonymous, or at least close enough that their differences don’t affect the outcome of a translation task. Since a Seel map is fully labeled, it can be interpreted either as a set of executable instructions or as static data, enabling it to function as a record in a database of relationships among metadata standards. Over time, these crosswalk records can be collected, searched, dynamically assembled, and even mined for new information.
Figure 9 shows a schematic representation of a database of Seel maps that can be accessed from a utility associated with the Crosswalk Web Service.
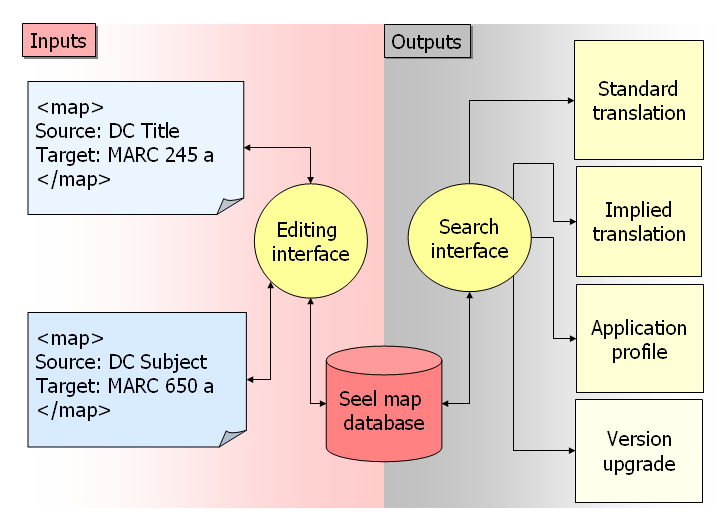
Figure 9. Seel maps in a persistent resource [View full-size image]
A metadata standards expert enters a new line into a machine-processable form of a crosswalk, such as an Excel spreadsheet. Because a Seel map closely resembles an entry in a crosswalk, a Seel map can be automatically generated in most cases. The standards expert and the software developer need only observe a few common conventions for coding the source, target, and special conditions, such as indicator values, that appear in Seel <context> elements. Once these conventions are established, a small set of changes may be the only effort required to upgrade a crosswalk to a new version of a standard because many of the maps in the database can be reused.
Once the new maps have been generated and added to the database, the expert interested in the ONIX-to-MARC translation can use the search interface to retrieve all maps with an ONIX source and a MARC target. This is a typical standard-to-standard translation, but in our model it is conceptually similar to other outputs. For example, a search query could specify Dublin Core or ONIX sources and MARC targets, producing a translation that mimics an application profile. Yet another search could retrieve all Seel maps whose target is MARC 245 $a. If the source in one map in the result set identifies the ONIX path <DistinctiveTitle>, while the source in another identifies the MODS path <titleinfo><title>, an automated process could safely produce an implied translation between the title fields in ONIX and MODS, using MARC 245 $a as an intermediary. As we said in the Introduction, metadata standards experts have not yet published a crosswalk for ONIX and MODS, but none is required when a collection of maps from related standards can be intelligently exploited.
The Seel maps database acknowledges some important realities about the metadata crosswalk as a conceptual object for achieving Chan and Zeng’s element-level interoperability. The maps corresponding to a published crosswalk between a pair of standards can be retrieved from the database with a straightforward search query, as we explained. More than likely, though, the translation will need to be customized in some way by adding, deleting, or overriding individual maps to accommodate the needs of a local task. Even so, the logic of decomposing the translation into maps and storing them emerges from the observation that most maps are likely to be persistent. Thus the Seel maps database enables the user to map the relationship between Dublin Core Title and MARC 245 $a once, store it, reuse it in a variety of translations and structural encodings, or mine information from it.
6. Using the translation service
The translation logic is available to OCLC applications through a call to the Crosswalk Web Service, or to third parties through a link on OCLC’s ResearchWorks page [20]. The service appears to the client application as a black box that processes a work order expressed in the Web Services Description Language [26], where the user supplies a triple that specifies the metadata standard, the syntactic encoding, and the character encoding for the input and output of the translation. The service is called from many contexts, ranging in complexity from batch processes that translate only a few elements to an editing interface that premits a cataloger to enter a detailed record and view it in multiple formats, in real time.
Crosswalks are obtained from public sources such as the Library of Congress, and from OCLC’s own metadata subject matter experts. Internally created crosswalks are submitted as spreadsheets. Though OCLC’s subject matter experts coded crosswalks as spreadsheets long before the Crosswalk Web Service was developed, the task is arduous, so we make every effort to leverage this work. For example, to obtain the relationship between Dublin Core and MARC, the subject matter expert mapped Dublin Core Terms to MARC, from which a Seel script was automatically generated. Since Dublin Core Terms is an application profile, the ‘dumb-down’ principle [18], which collapses extensions such as DCTerms:Title:Alternative to DC:Title, can be used to generate the crosswalk to Unqualified or Simple Dublin Core. The same intellectual input produces two different translations and many more when the different structural encodings are taken into account, and still more when these translations are used as the source or destination in relationships involving MARC and MODS, GEM, or ONIX. These savings are possible because every component in our translation model is designed for reuse.
In the future, we plan to streamline the writing of crosswalks by developing a user interface that accepts inputs required by the Seel map structure and generates either human-readable crosswalks or Seel scripts. So far, our work has focused on bibliographic records but discussion is underway to develop additional sets of translations that represent descriptions of authorities, holdings, and museum data. Our goal is to create an environment that makes it as easy as possible to exploit the intelligence embedded in crosswalks for any kind of markup. Through repeated use, these crosswalks will be vetted and revised and the most popular ones will emerge as de-facto standards.
7. The status of schema-level interoperability
To summarize, we have described a translation model (shown in Figure 2), a data model (Morfrom), a language specification (Seel), a software toolkit (the Crosswalk Web Service), and, soon, a publicly accessible demo designed for the large-scale management of diverse streams of metadata. This work proceeds from the hypothesis that beneficial consequences follow if the atomic unit of analysis is a map, or a single equivalence between two elements—not a complete translation between two standards, the more typical solution proposed in the metadata translation problem space.
In short, the Crosswalk Web Service answers Chan and Zeng’s call for tools that make it easier to implement element-level interoperability and has permitted us to normalize the records encountered in the day-to-day conduct of OCLC’s business. These records represent about a dozen formally defined metadata standards and a difficult-to-enumerate span of structural diversity. But because we serve a single community of practice, the semantics of the relationships required to execute a large number of transactions are generally well understood.
Nevertheless, this solution addresses only the easy cases. At a level lower than the element is a set of issues that we informally refer to as field normalization—i.e, the standardization of data contained in elements that are especially critical to the management of bibliographic records such as names, dates, and citations. In these cases, as in the typical bibliographic record that passes through OCLC’s systems, syntactic expression may be diverse but the semantics are transparent. As a result, we are exploring the potential of a scripting language similar to Seel that operates at the sub-element level and can be written as a persistent set of instructions retrieved from a database to add, delete, or rearrange data.
But at a level higher than the element is the more difficult problem of enhancing the interoperability of two standards by making their abstract models more consistent. Unlike the problems we addressed in the Crosswalk Web Service, which are largely in the realm of software engineering, reconciling differences among abstract models is a considerably fuzzier sociological problem that requires intellectual analysis, consultation with the gatekeepers of the standards, and bilateral compromise. For example, Doerr, et al.[28], a conceptual reference model used in cultural heritage communities to describe museum objects, with controlled vocabularies that have been developed for broader application in digital library communities, including the authors’ own Harmony [29]. But the authors reported only partial success. To resolve the problem for good requires an ontology of everything that has been deemed important to a description of a broad range of resources and genres. And the ontology of descriptions continues to evolve, as leading-edge work is being done to define the essential components in descriptions of intellectual property rights, or of educational materials that are deployed in complex technical and institutional contexts.
Since we have not yet worked with metadata for museum objects, the problems described by Doerr, et al. might seem remote to our concerns. But this impression is misleading because a similar problem lies at the core of ONIX and MARC, a relationship that we have examined closely. Despite the fact that many pairs of elements from the two standards can be mapped and made accessible through the Crosswalk Web Service, as we have discussed in this paper, many more await the resolution of a problem whose major symptom is that the authoritative crosswalk maintained by the Library of Congress is too ambiguous to use as direct input to our system. For example, about thirty elements map to MARC 245 $a (two of which crop up in Table 1), despite the fact that MARC allows only one instance of this element per record. The underlying problem is that the ONIX Books standard defines a record that describes a foreground object and an optional set of ancillary objects—reviews, tables of contents, Web sites, promotional materials, and even pieces of clothing, each of which may be accompanied by a detailed description that includes a title—while a MARC record is designed as a description of a single item. Collaborative work by two high-profile organizations is required to resolve the differences between the abstract models that underly the two standards. But when this work matures, more elements could be mapped in the Crosswalk Web Service.
Notes
[1] “WorldCat.” <http://worldcat.org>. Accessed 11/01/07.
[2] “ONIX for Books.” <http://www.editeur.org/onix.html>. Accessed 11/01/07.
[3]”MARC Standards.” <http://www.loc.gov/marc/>. Accessed 11/01/07.
[4]”OCLC WorldCat (the OCLC Online Union Catalog) (WorldCat).” <http://www.oclc.org/Support/documentation/firstsearch/databases/dbdetails/details/WorldCat.htm>. Accessed 11/01/07.
[5]We use crosswalk in the sense defined in the glossary of “Introduction to Metadata: Pathways to Digital Information,” (n.d.): “A chart or table that represents the semantic mapping of fields or data elements in one data standard to fields or data elements in another standard that has a similar function or meaning. Crosswalks enable heterogeneous databases to be searched simultaneously with a single query as if they were a single database (semantic interoperability) and to effectively convert data from one metadata standard to another. See also metadata mapping below. Also known as field mapping.”
<http://www.getty.edu/research/conducting_research/standards/intrometadata/glossary.html#C>. Accessed 02/08/08.
[6] “ONIX to MARC 21 Mapping.” <http://www.loc.gov/marc/onix2marc.html>. Accessed 11/01/07.
[7] “Introduction to ASN.1.” <http://asn1.elibel.tm.fr/introduction/index.htm>. Accessed 11/01/07.
[8] “Resource Description Framework (RDF).” <http://www.w3.org/RDF/>. Accessed 11/01/07.
[9] “Open Archives Initiative.” <http://www.openarchives.org/>. Accessed 11/01/07.
[10] “MARCXML: MARC 21 Schema.” <http://www.loc.gov/standards/marcxml/>. Accessed 11/01/07.
[11] “ISO: 2709:1996.” <http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=7675>. Accessed 11/01/07.
[12] “Dublin Core Metadata Element Set, Version 1.1.” <http://dublincore.org/documents/dces/>. Accessed 11/01/07.
[13] “DCMI Metadata Terms.” <http://dublincore.org/documents/dcmi-terms/>. Accessed 11/01/07.
[14] “MODS: Metadata Object Description Schema.” <http://www.loc.gov/standards/mods/>. Accessed 11/01/07.
[15] Chan, L.M. and Zeng, M.L. (2006). “Metadata Interoperability and Standardization – A Study of Methodology. Part I: Achieving Interoperability at the Schema Level.” D-Lib Magazine.12:6 (June). <http://www.dlib.org/dlib/june06/chan/06/chan.html>. Accessed 11/01/07.
[16] Zeng, M.L. and Chan, L.M. (2006). “Metadata Interoperability and Standardization – A Study of Methodology. Part II: Achieving Interoperability at the Record and Repository Levels.” D-Lib Magazine.12:6 (June). <http://www.dlib.org/dlib/june06/zeng/06/zeng.html>. Accessed 11/01/07.
[17] Godby, C.J., Smith, D., and Childress, E. (2003). “Two Paths to Interoperable Metadata.” Presented at Dublin Core (DC)-2003: Supporting Communities of Discource and Practice–Meadata Research& Applications. Seattle, Washington (USA), September 28-October 2. <http://www.oclc.org/research/publications/archive/2003/godby-dc2003.pdf>. Accessed 11/01/07.
[18] Heery, R. and Patel, M. (2000). “Application Profiles: Mixing and Matching Metadata Schemas.” Ariadne. 25 (September). <http://www.ariadne.ac.uk/issue25/app-profiles/>. Accessed 11/01/07.
[19] Godby, C.J., Young, J.A, and Childress, E. (2004). “A Repository of Metadata Crosswalks.” D-Lib Magazine. 10:12 (December). <http://www.dlib.org/dlib/december04/godby/12godby.html>. Accessed 11/01/07.
[20] “ResearchWorks: Things to play with and think about.” <http://www.oclc.org/research/researchworks/default.htm>. Accessed 11/01/07. The public demo of the OCLC Crosswalk Web Service was originally intended to be available in time for publication of this article. It was not quite ready in time, but we anticipate it being available soon.
[21] “Jumper.” <http://www.jumpernetworks.com/>. Accessed 11/01/07.
[22] “MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.” <http://www.loc.gov/marc/specifications/specchartables.html>. Accessed 11/01/07.
[23] Strictly speaking, the scripts are not analogous because this script inserts indicators, while the corresponding Seel map in Figure 6 does not. But the Seel map shown in Figure 7 shows how it would be done.
[24] “ONIX to MARCXML Stylesheet.” <http://www.loc.gov/standards/marcxml/xslt/ONIX2MARC21slim.xsl>. Accessed 11/01/07.
[25] “XML XPath language (XPath).” <http://www.w3.org/TR/xpath>. Accessed 11/01/07.
[26] “Web Services Description Language (WSDL).” <http://www.w3.org/TR/wsdl20/>. Accessed 11/01/07.
[27] Doerr, M., Hunter, J. and Lagoze, C. (2003). “Towards a Core Ontology for Information Integration.” Journal of Digital Information. 4:1, Article No. 169, 2003-04-09. <http://jodi.tamu.edu/Articles/v04/i01/Doerr/ >. Accessed 11/01/07.
[28] The CIDOC Conceptual Reference Model. <http://cidoc.ics.forth.gr/>. Accessed 11/01/07.
[29] Lagoze, C. and Hunter, J. (2001). “The ABC Ontology and Model.” Journal of Digital Information.” 2:2, Article No. 77, 2001-11-06. <http://jodi.tamu.edu/Articles/v02/i02/Lagoze/>. Accessed 11/01/07.
About the Authors
Carol Jean Godby is a Research Scientist in OCLC Research. Her research
interests focus on automatic metadata extraction and creation.
godby at oclc.org
Devon Smith is a Consulting Software Engineer in OCLC Research. He works
primarily on metadata translation. smithde at oclc.org
Eric R. Childress is a Consulting Project Manager in OCLC Research. He
provides project management support for OCLC Research initiatives and
participates as a contributing team member on selected research
projects. eric_childress at oclc.org

will, 2012-06-22
thanks for the great notes
Toward element-level interoperability in bibliographic metadata | John's LS 566 Blog, 2015-02-06
[…] http://journal.code4lib.org/articles/54 […]