By Karen Coyle
In the library community there is a growing recognition that there will need to be a successor to the MARC21 bibliographic format. Discussions about this tend to focus on structural issues: will the new format be an XML format? Will it make use of RDF and linked data standards?
What these questions do not address is the much more difficult task of translating the semantics of library data into something new. It takes only a short investigation of the data coded in MARC21 to reveal that the tags and subfields themselves are inadequate to define the actual data elements carried in library catalog records, as Jason Thomale discussed in his recent article [1]. It is therefore logical that a first step in the transformation of MARC21 to another format (or formats, for there may be more than one) is to identify the data elements that are contained within the MARC21 record. That task, as Thomale evidenced in his example, is more difficult than it may seem.
A few caveats are in order. The analysis here is an analysis of MARC21 format data elements, not of MARC21 instance data. This mapping will not be sufficient to translate individual MARC21 records to a different format; that would require further information that would need to be provided by one or more applications. This analysis is intended solely to identify the bits of information that library data can contain. To illustrate, the MARC21 field definition for an ISBN is tag 020; an instance of the ISBN would be the ISBN number itself tagged in a MARC21 record: 020 $a 0877790019. The description of the MARC21 bibliographic format is available at http://www.loc.gov/marc/bibliographic/, while the records in library catalogs that use this format are examples of instance data.
This analysis is currently limited to the MARC21 bibliographic format. I suspect, however, that the techniques used here and the patterns that are revealed will be the same in the authorities format.
None of this is intended to guarantee round-trip mapping between MARC21 and any other data format. I decided early on that to insist on round-tripping for all data elements would greatly complicate the task at hand. Some round-tripping would depend on instance data (e.g. keeping track of whether the fixed field value came from an 006 or an 008), which is not in scope here.
I subtitle this paper with “A Start” because my analysis so far has only covered the fixed fields and the number and code fields. These are the easier portions of the MARC21 record to tackle, with the fixed fields being the lowest of the “low-hanging fruit.” What I have learned in this process is the focus of this article.
The Back Story
My investigation into the underlying data elements of the MARC21 record began in 2005 with an unpublished report that I produced for the Library of Congress that defined some possible steps that could be taken to prepare for “life after MARC.” At that time my assumption was that the next library format would be in XML. However, I stated that a necessary step in the process of transforming MARC21 would be to identify all of the data elements the format contains. In essence, a distillation of MARC21 into data elements would allow the same data to be carried in any future serialization. I wasn’t aware of how difficult a task this would be until I embarked on it later myself.
I began my work with a database of tags and subfields that had been developed by Tom Delsey in his “Functional Analysis of MARC21 Bibliographic and Authority Formats” [2]. I was able to supplement this using the tables of fixed fields and their values from marc.pm modules [3]. If nothing else, this task made me painfully aware that we do not have a sharable machine-readable form of our own data format. The MARC21 standard is represented only by an online text, something that is rather astonishing if you think about it. Anyone wishing to develop applications for MARC21 must create their own usable version. My own database still lacks definitions and descriptions, and those will probably need to be added by screen-scraping hundreds of screens from the LC web site.
Having the MARC21 fixed fields, tags and subfields in a database first allowed me to do some quick statistics based on the names of fields and fixed field values. These results are in a page on the Futurelib wiki [4]. I was particularly struck by the large number of different fixed field elements (many of which are probably encoded only rarely in actual instance data), and how many of them have “non-values” like “unknown.” The use of values for “unknown” and “no attempt to code” are directly related to the characteristic of fixed length fields made up of positional data elements, where all positions must be filled in to retain the positioning. It becomes therefore necessary to decide if “unknown” is truly a value or can be treated as the absence of a value. As I once argued at a meeting of the MARC21 standards group, MARBI, about the use of the value “No attempt to code,” it is highly unlikely that someone who is not going to bother to code a value will carefully encode their intention not to bother. Some of these values may exist in instance data only because they have been used as defaults. In the extraction of fixed fields that I have done so far I have ignored the three values “Other,” “No attempt to code,” and “Unknown” although there may be a case to be made for including “Other” in this analysis (and I may decide to add those later). I also did not include elements that have a status of “Obsolete” in the MARC21 documentation. Any of these could be added later if there is a need for them.
In addition to the fixed field values like “Unknown,” almost 60% of indicator positions (206 out of 350 in my database) have the value “Undefined.” These truly represent empty positions in the record format and they can be ignored.
The Analysis
In beginning my analysis of the data elements in MARC21, I found it convenient to break the task into three primary sets:
- control fields (00X)
- number and code fields (0XX)
- descriptive fields (XXX)
The fixed fields are fixed-length strings with positional data elements that take coded data that is presumably useful for machine processing. These are primarily in the form of controlled term lists with the terms represented by 1-2 character codes, and are tagged 006, 007, and 008. The “00X” area also includes the record number (001), record source (003), and a date/time stamp (005). These data elements are for record management, and do not belong in an analysis of MARC21 content. One of the difficult tasks in analyzing MARC21 is to separate the record structure from its content, as the two are not distinguished in the format itself.
The remaining MARC21 fields (tags 010 to 888) are variable-length fields with variable-length subfields. The fields tagged from 010 to 088 contain data-like identifiers, classification numbers and other data that is not generally displayed as part of the bibliographic description. The fields tagged from 100 to 888 are the “meat” of the bibliographic record, with authors, titles, notes, subjects, etc. Users are presented with much of this latter data in a textual display. The bibliographic description area contains the most voluminous fields, some with nearly thirty subfields with complex interactions and dependencies between them.
All of the data elements in my study must be assigned an identifier, and I use http URIs for this under the registered domain name “marc21.info”. It is also convenient if the description of the data elements contains information that would lead back to the original encoding of that data in MARC21. I therefore use the MARC21 tags and positions to create an identity and a link between the MARC21 field origins and the derived data. More detail is given on this below.
Control fields (00X)
The control fields include record numbers and identifiers as well as three fields made up of fixed-length data elements: 006, 007, and 008. The fixed fields that I include in my analysis are the 007 and 008, for reasons that I explain below. These look like:
007 sd fsngnn ed 008 981123p19981996enkmun efhi d
The data elements in these fields are defined by their positions in the fixed field, such as:
007 position 03 = Speed (of the sound recording)
The “f” in position 3 (all numbered positions are counted starting from “0”) in the string below is the value for the speed of the sound recording in this 007:
007 sd fsngnn ed
Since the element has only one byte in length for its values, the information is recorded using single-letter codes for each desired value:
a – 16 rpm (discs)
b – 33 1/3 rpm (discs)
c – 45 rpm (discs)
d – 78 rpm (discs)
e – 8 rpm (discs)
f – 1.4 m. per second (discs)
h – 120 rpm (cylinders)
i – 160 rpm (cylinders)
k – 15/16 ips (tapes)
l – 1 7/8 ips (tapes)
m – 3 3/4 ips (tapes)
o – 7 1/2 ips (tapes)
p – 15 ips (tapes)
r – 30 ips (tape)
u – Unknown
Tags 007 and 008 are each more than one set of data elements since the values carried by the field vary based on the format of the resource being described. The different formats of the 008 are the ones that are defined in the MARC21 Leader. The Leader contains a small number of record-level fields, including the primary format of the resource:
books, computer files, maps, music, continuing resources, visual materials
The formats covered by the 007 are different from those of the 008. They are coded in the first byte of the 007 and are:
map, electronic resource, glob, tactile material, projected graphic, microform, nonprojected graphic, motion picture, kit, notated music, remote-sensing image, sound recording text, videorecording, unspecified
This gives us six different 008 fields and fourteen different 007 fields to analyze.
I do not include the 006 data elements in my analysis since every 006 element is a duplicate of an element in the 008. The 006 exists because the 008 is not repeatable in MARC21 and therefore cannot represent different formats for a multi-format resource. In a semantic sense, there are no new or different data elements in the 006, and repeatability of data elements is not part of the semantic analysis. The elements only need to be defined once even though they could be used more than once in a data record. In essence, I am treating the 006/008 the same way I would treat a repeatable field for a subject heading.
In spite of removing the repetition of the 006 data elements, the number of data elements in the fixed fields is very large. The 007 has 118 data elements, although only 55 of those are unique; the others are repeated in two or more of the 007 formats. The 008 has 58 unique data elements. Most of these data elements take as values a controlled list of terms that are represented by alphabetic codes. There are nearly one thousand different terms between these 113 term lists.
The fixed fields pose few intellectual problems, and the results of my preliminary analysis are on the futurelib wiki [5] with the resulting lists of elements [6] and an RDF-defined value vocabulary [7]. (With thanks to Gordon Dunsire for help with the RDF coding.)
Note that the tag alone is not sufficient to identify the data elements for the fixed fields because either the Leader “Type of Record” (offset 06), in the case of the 008 field, or the first position of the 007 essentially creates a different fixed field for that type of material. I therefore add the MARC21 term for the relevant format to the identifier.
Data elements in the fixed fields get identifiers with the tag, the format and the position or positions.
| Data element | MARC21 data | Identifier |
| reduction ratio | tag 007
format=microform (007 pos. 0 = “h”) data element at position 05 |
007microform05 |
| projection | tag=008
format=map (Leader 06 “Type of record” = “e”) data element in offset positions 22-23 |
008map22-23 |
The actual coded values in each field consist of one- or two-character codes. Identifiers for these coded values are constructed using the identifier for the tag, the format and the position or positions as described above with the addition to the string of the code that represents the value of the data elements. Thus each term in the controlled lists that make up the vast majority of the fixed fields has an identifier.
| Data element | Value | MARC21 data | Identifier |
| reduction ratio | low reduction | tag 007
format=microform (007 pos. 0 = “h”) data element at position 05 value=low reduction (code=”a”) |
007microform05a |
| projection | sinusoidal | tag=008
format=map (Leader 06 “Type of record” = “e”) data element in offset positions 22-23 value=sinusoidal (code=”bg”) |
008map22-23bg |
These identifiers are currently included in the URIs for the fixed field data elements, but I am not wedded to that solution. Perhaps these would be better coded as skos:notation elements.
<skos:Concept rdf:about=”http://marc21.info/vocab/007map03/007map03c“>
The value vocabularies in my analysis are those elements whose values are included “in line” in the MARC21 standard. There are also external lists, such as the language codes and country codes, that are maintained separately. Some of these are appearing on the Library of Congress authorities site http://id.loc.gov, and others have been defined at http://marccodes.heroku.com/.
Number and Code Fields (0XX)
While the fixed field data elements are essentially structured as a compact string of key/value pairs, MARC’s variable fields have a complex structure. Each field has two indicator positions that can modify the field’s semantics in a variety of ways, and the majority have multiple subfields that are subordinate to the field and sometimes to each other.
In these variable length fields we encounter some of the tough questions of interpreting MARC21 as data elements. The first thing to realize is that a single field may in fact contain more than one distinct data element that describes the primary resource. These data elements can be simple — that is, they can consist of a single string — or complex, requiring values from multiple subfields to complete the data element. In other cases, some subfields in the field may be qualifiers for other subfields in the field, most notably the $2 subfields that carry the code for the source of an otherwise un-credited data element.
The MARC21 record also carries some administrative data related to the instance record. The aforementioned 001, 003, and 005 are of this type. The 040 field (Cataloging Source) records the agencies that created and modified the instance record. There are identifier fields, such as the 010 (Library of Congress Catalog Number) that are record numbers for the same bibliographic data in another system. This would probably be best thought of as expressing relationships between instances of the data. I include these in my analysis even though these relationships may be handled very differently in a future implementation of bibliographic data.
Effect of Indicators
The meaning of the entire field may change on the application of indicator values. The 024 is a good example of this:
024 Other standard identifier
Indicator 1
0 – International Standard Recording Code
1 – Universal Product Code
2 – International Standard Music Number
3 – International Article Number
4 – Serial Item and Contribution Identifier
7 – Source specified in subfield $2
8 – Unspecified type of standard number or code
Indicators of this type expand the capabilities of the MARC21 format, overcoming the inherent limitations of the structure. If you consider that the 0XX range at best allows only 89 different fields, and that all fields with a “9” in the tag are supposed to be reserved for local use, the actual number of available fields is only 70. Without this ability to expand the number of data elements through the use of indicators and through qualifying subfields (like $2) the record would have been unable to incorporate new codes and identifiers. As it is, 49 tags have been assigned in this range. The 024 field is also an interesting example of an open-ended list that uses “Source specified in subfield $2” to make the value of the field greatly expandable.
This is the most common use of indicators in this tag range, but there are others. Some fields have indicators that are data values that could stand on their own, such as “Existence in LC collection,” which is semantically binary, “yes/no.”
There are indicators that give information about how the data is structured in the field. In the Coded Cartographic Mathematical Data field (034) the first indicator states whether the field contains a single scale or a range of scales. This appears to be redundant with the data itself: a range is expressed with two successive $b subfields. As I am not knowledgeable about cartographic data, finalizing this field will await input from someone with that specific expertise who can clarify the meaning of this indicator. In general, though, I am not including record structure in my analysis, only semantics, since other serializations of the data elements may express structure (like ranges) differently.
What is a Data Element?
Unlike the fixed fields, in working with the variable fields it is necessary to decide what makes up a data element. The nature of the tag-plus-subfields structure often masks the fact that in some cases the subfields in a field are independent data elements that have been placed in a single field because they have something in common. As an example, the field for the ISBN, tag 020, has three subfields:
020 $a ISBN $c Terms of availability $z Canceled/invalid ISBN
These are actually three separate simple elements: ISBN, Terms of availability, and Canceled/invalid ISBN. Each of these is a statement about the primary resource that is the focus of the bibliographic record, and they are not defined as dependent on each other. Their collocation in a single field does not have an effect on their semantics. (Note: although the instructions in MARC21 do not indicate a dependency between the ISBN in the $a subfield and the terms of availability in the $c, it may not be wrong to interpret them in that way given that the field is repeatable – as are most variable fields. One could agonize at length over situations of this type, or simply make a decision and move on. I generally opt for the latter, especially because I consider the work at this stage to be informative, not prescriptive.)
Using the 024 again as an example, it has two types of data elements. The first are those defined by first indicator codes 0-4, 8. These have the following subfields:
$a – Standard number or code $c – Terms of availability $d – Additional codes following the standard number or code $z – Canceled/invalid standard number or code (R)
024 fields with a code of “7” in the first indicator also have a subfield $2 that has a standard value for the organization or system providing the identifier; something that can also be called the provenance.
Based on the indicators it is pretty clear that the 024 breaks out into more than one type of identifier. Each of the values coded in 0-4, 8 essentially defines the type of identifier in the field, and value of “7” designates a complex data element that carries within it the designation of the entity providing the identifier. That would give us seven separate data elements based on this MARC21 field. There are additional aspects of these subfields that need to be examined, particularly the relationships among them.
The subfield $a is the primary identifier string, with the subfield $d being additional characters that belong to that identifier. This indicates that $d is dependent on $a, and those two codes need to be treated as a multi-unit data element. In the case of identifiers whose source in included in $2, the $2 is also part of this complex. So we now have two patterns: $a $d, and $a, $d, $2.
Then there is the $z, the canceled/invalid standard number or code. It isn’t at all clear that this has any direct relationship with the data element that begins with the $a. The MARC21 documentation says: “If a valid number or code of the same type is not known, subfield $z may appear alone in field 024.” There isn’t a relationship of dependency between the $a and the $z, the $z is a separate data element. Oddly, it has no subfield for “additional codes” and it’s probably best to assume that a $z $d combination is not intended. However, presumably a $z $2 combination is possible.
The $c subfield for Terms of availability has an odd relationship to the primary data element of the field; the MARC21 documentation says: “Information is only recorded in this subfield when a number is present in subfield $a.” That’s a constraint on input, which is usually to be managed by an application, but it’s less clear how this affects the meaning of the data element represented by the $c. At this point, without having clear use cases to help us understand how this data might be employed in actual applications, it is hard to make a clear decision about the data element, but since MARC21 treats it as dependent, I decided to keep it together with the $a.
The 024 also has a second indicator called “difference indicator” that states whether the code is available both in eye-readable and machine-readable form. This indicator qualifies the $a $d and therefore belongs with those. I have coded this by adding “/02” to the tag in the chart below.
Out of this one MARC21 field we therefore derive fourteen separate data elements. I’ve used shortcuts here in the display but the names of the data elements and their parts are spelled out in the PDF version of the 0XX analysis [8]. (I have not yet created an RDF-encoded version of this range. Presumably it would make use of OWL, and I would welcome collaboration on that aspect of the task since OWL is notably complex and has many options.)
| Element | MARC21 field/subfields |
| ISRC | 024$a 024$c 024$d 024/02 |
| UPC | 024$a 024$c 024$d 024/02 |
| ISMN | 024$a 024$c 024$d 024/02 |
| EAN | 024$a 024$c 024$d 024/02 |
| SICI | 024$a 024$c 024$d 024/02 |
| Other number | 024$a 024$c 024$d 024$2 024/02 |
| UNKnown Number | 024$a 024$c 024$d 024/02 |
| ISRC Cancelled | 024$z |
| UPC Cancelled | 024$z |
| ISMN Cancelled | 024$z |
| EAN Cancelled | 024$z |
| SICI Cancelled | 024$z |
| UNKnown Number Cancelled | 024$z |
| Other number cancelled | 024$z 024$2 |
Because this is mainly an exercise in identifying the semantics of MARC21 it is probably a good idea to hold in check our impulses to normalize the data elements or make them more consistent. Consistency is not MARC21’s forte, and I am sure that there will be fields in the XXX area that make this one look reasonably well-designed. I could see a later step that attempts to “fix” some of the problems that we encounter in MARC21, but I’m not sure that will ever be needed. I say that because I sincerely doubt that we will want to reproduce the entirety of MARC21 in another format even though each of the individual data elements may find a future user base. In fact, it makes perfect sense to me for us to rebuild our bibliographic data from the ground up, looking back to MARC21 from time to time to remind ourselves of data that we once thought necessary but perhaps no longer do.
Finding Patterns
When analyzing MARC21 variable fields one has to understand the relationships between the subfields. Certain patterns are revealed that can be applied repeatedly to the task. I have so far identified these three patterns:
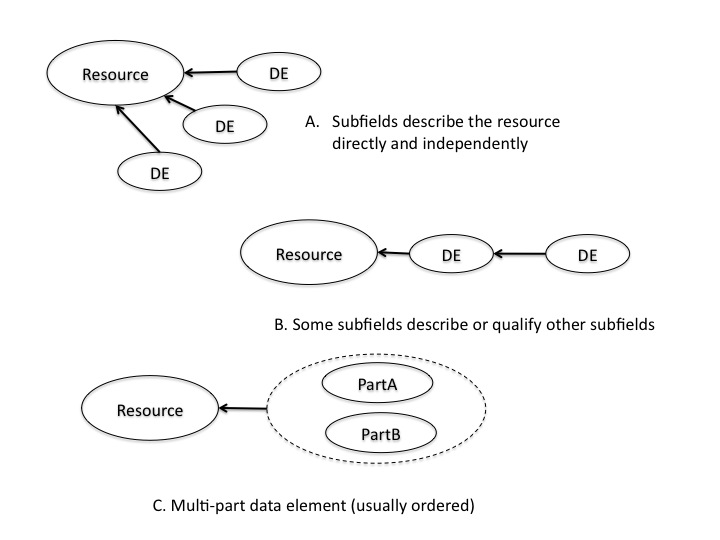
Figure 1.Types of Relationships Between MARC Subfields
Examples:
A. 041 Language code
$a Language of text/sound track or separate title
$b Language of summary or abstract
$d Language of sung or spoken text
$e Language of librettos
$f Language of table of contents
$g Language of accompanying material other than librettos
$h Language of original and/or intermediate translations of text
$j Language of subtitles or captions
The 041 has multiple types of languages, each in a standard ISO 3-character coded form. There is no dependency between them and each describes an aspect of the resource being cataloged without a need for the others.
B. 100 Personal Name Main Entry
$a Person name
$d Dates associated with a name
The $d holds the dates for the person whose name is in the $a, not dates for the primary resource being described. In this case, the $d is a qualifier on the $a, because the dates are used to qualify the name to make the name heading unique.
C. 050 Library of Congress Call Number
$a Classification number
$b Item number
The call number is in two parts: classification and item. Both are describing the primary resource, but the Item number cannot be used alone, therefore it is a part of the whole that is the Call number, with parts Classification number and Item number.
Within a single field (and this will happen more frequently in the XXX fields) more than one of these patterns may exist.
For Another Time: Bibliographic Description Fields (XXX)
It’s obvious from the analysis of the code and identifier fields (0XX) that the remainder of the bibliographic fields, those in the tag range 100-899, will present some significant and interesting problems. For example, there are fields that are defined more by their function than by their semantics, as in the uniform title field, MARC21 tag 240. In the MARC21 documentation, the field is defined as:
“Used when a work has appeared under varying titles, necessitating that a particular title be chosen to represent the work.”
The $a subfield of the 240 is defined as the “uniform title,” with the other subfields having the role of modifiers on that title. Although identically coded, the $a subfields in the following 240 fields have totally different meanings:
240 10 $a Pendolo di Foucault. $l English
This uniform title brings together the translations of a Work. “Pendolo di Foucault” is the title of the work (in the FRBR sense of Work), in the original language. The translation being described is in English.
240 10 $a Selections
This is used for an item “…consisting of three or more works in various forms…” The title of the work is not “Selections.” This title, and others such as “Works” or “Complete works” are supplied by the cataloger.
240 10 $a Concertos, $m harpsichord, string orchestra, $n BWV 1052, $r D minor
This is a practice of music librarianship. It is a coded description of music that may have little or nothing to do with the actual title on the item being described. It is a structured field that contains the distinguishing information about a piece of music in a set of facets: medium of performance, standard number, key, arrangement.
All of these uses of the 240 field fulfill the function of providing a single title for the work, but there is no way to give an a priori meaning, such as “title of original work” or “musical form” to subfield $a as a data element because that difference only appears in instance data. (Note that in some cases there will be no way to algorithmically distinguish these different semantics even in instance data.)
The bibliographic description fields also have a significant amount of redundancy, in the sense that elements like “author” and “title” appear in numerous fields. However, because of the limitations of the MARC21 structure, these elements have been coded differently in different fields in order to conserve the use of subfield codes (in particular in the 77X linking fields).
100 field, personal name subfields
$a – Personal name (NR)
$b – Numeration (NR)
$c – Titles and words associated with a name (R)
$d – Dates associated with a name (NR)
$e – Relator term (R)
$q – Fuller form of name (NR)
$u – Affiliation (NR)
773 field, personal name subfields
$a – Main entry heading (NR)
Examples:
100 1_ $a Hamilton, Milton W. $q (Milton Wheaton), $d 1901-
773 0_ $a Hamilton, Milton W. (Milton Wheaton), 1901- $t Sir William Johnson
and the Indians of New York. $d [Albany] : University of the State of
New York, State Education Dept., Office of State History, 1967
Can these be considered semantically equivalent even though they may be composed of different parts?
It remains to be seen how effectively the bibliographic description fields can be analyzed into their component semantics. It may be necessary to create elements that are as ambiguous as their MARC21 origins, and to use this to illustrate areas of library data that need to be more precisely defined to facilitate use and re-use.
Comparison to RDA
There is a comparison [9] between MARC21 and RDA that was part of the RDA development process. This document was produced in 2007 and was not updated as RDA evolved beyond that point. However, it is clear from that document that the list of RDA elements that was issued as RDA Element Analysis [10] is not at the same level of detail as the MARC21 standard, and also that many data elements, in particular those in the MARC21 fixed fields and coded data fields, are not addressed in RDA. An obvious next step is to attempt the same comparison between the MARC21 semantic analysis and RDA. I have no doubt that this will have some similar results to the study produced by the JSC, but cannot speculate at this time on what we should conclude about those differences.
Conclusion
As I said in my introduction, undertaking a study of this depth as a solo project may not have been wise. However, my frustration as a library professional at not having a good grasp on the scope and nature of our own metadata has led me to throw caution to the wind. There is a certain amount of magical thinking on my part: if we could just create a definitive ontology for library data then we could make a rational transformation from MARC21 to a more modern metadata format. This doesn’t mean I expect that we would use this analysis to create a map or cross-walk from MARC21 to MARC++. In fact, armed with this knowledge we might decide to greatly trim or radically transform the data elements that we carry with us into the future.
I will continue to make available my results in machine-usable formats so that others can do their own analyses or make use of what I have done. I welcome comments and criticisms, and anything else that this work might inspire.
Notes
[1] Thomale, J. (2010). Interpreting MARC: Where’s the Bibliographic Data? Code4Lib Journal, 11. http://journal.code4lib.org/articles/3832
[2] Delsey, T. (2003) Functional Analysis of the MARC 21 Bibliographic and Holdings Formats. http://www.loc.gov/marc/marc-functional-analysis/original_frbr.html
[3] http://marcpm.sourceforge.net
[4] http://futurelib.pbworks.com/w/page/13686649/Data-and-Studies
[5] http://futurelib.pbworks.com/w/page/35201344/fixed_fields
[6] http://kcoyle.net/rda/elementslist.txt
[7] http://futurelib.pbworks.com/w/page/36289829/Resulting-Data
[8] http://kcoyle.net/rda/0xx.pdf
[9] Kiorgaard, D. (2006). RDA and MARC21. http://www.loc.gov/marc/marbi/2007/5chair12.pdf
[10] Danskin, A, (2009). RDA Element Analysis. http://www.rda-jsc.org/docs/5rda-elementanalysisrev3.pdf
About the Author
Karen Coyle is a librarian and consultant with particular interest in metadata. She began encouraging the library community to work on the next generation of library metadata at least ten years ago. As this was not successful, it has become a DIY project.

Code4Lib Journal – n° 14 « pintiniblog, 2011-07-27
[…] MARC21 as Data: A Start […]
Formato XML pode substituir o formato MARC? | Processo Técnico BICE/UCS, 2011-07-29
[…] Para acessar o artigo, em inglês, clique aqui […]
Matthew Beacom, 2011-08-04
Karen,
Great article on your MARC modernization effort.
At the end you say, “… armed with this knowledge we might decide to greatly trim or radically transform the data elements that we carry with us into the future.”
We may begin to trim the needed data elements immediately and not wait until we are fully-armed with this knowledge. We can create a simple bibliographic model that can begin to capture or propose those elements (with definitions) that would allow us to create services for users. Among them may be identifiers of various sorts, titles, publication as an event, etc. That said, you have given us all a great start. Thank you.
Scott Lewis, 2011-08-04
Though I have not worked extensively with MARC, I’ve done enough with it to notice many of the complexities described in this piece.
Overall, it is my impression that attempts to describe these data structures in terms of databases and database-type concepts(such as Codd’s
normalization) may not be the most fruitful path to follow.
My impression of MARC is that what it maps to most closely would be the way in which we construct and make use of objects in the more pure O-O programming
languages, such as Smalltalk and Self.
One way of looking at that shift is that data/database type constructs tend to concentrate on the \nouns\ of the given information. The formation of MARC
itself is attempting to supply both the \nouns\ and something like a \verb\ form (or at least a gerund) as well. This noun/verb form (data and the
integral means of accessing it) is very much what objects offer.
I think there may be two consequences to following this path. Firstly, if the goal of a user/translator of MARC is to do something helpful with it within
a program, it might be best to consider moving from a standard RDBMS to an Object-based RDBMS. Secondly, if the goal is to serialize the MARC data in a
different form, such as XML (perhaps in OWL), it might be best to first transform the data into an object form, then work out how to serialize that
object.
Using objects as an intermediary in this way may seem to be either a distraction or an additional task. However, the goal of O-O has never been to, say,
make computers work faster. It has always been about finding better ways for humans to conceive of complex systems. MARC might be a good place to make use
of these tools.
cheers,
Scott
“MARC21??????”??? » ????III, 2011-08-06
[…] 2011?8?6? ? catwizard ?? » MARC21 as a Data: A Start / By Karen Coyle. Code4Lib Journal, Issue 14, 2011-07-25. ISSN 1940-5758 […]
Jakob, 2011-08-10
@Scott: I would not call it Object-Oriented and I strongly doubt that using Object-based RDBMS makes any difference, because this is too much on a technical level. The representation in a (possibly OO-)RDBMS is just another (internal) serialization, comparable to XML, or RDF. Instead we need a better understanding of the \data elements\ as Caren calls it: the task is to determine the basic conceptual entities (you can also name it aspects) of a record and their dependencies. Codd’s or other datbase theory maybe helpful in doing so, but I find Caren’s diagrams helpful enough.
@Caren: I found that sometimes order of repeatable elements is relevant and sometimes it is not. Do you have more on repeatable fields?
Eric Nord, 2012-03-19
While new to MARC I’ve already become accutely aware of the need for a new format. One of the great difficulties with MARC21 is identification of records is aproximate not exact. I belive this is due in part to many new formats and item types being forced into a standard that was never built to handle them (Describing CD, DVD, Blu-Ray in the 007 for example)
I wonder how the well a modular approach would work where each “item type” had it’s own standard identifiers, rather than trying to cram everything into one rule set (which leads to abstract identification). This would compartmentalize the “standardization” to a specific item type and perhaps allow for more direct and clear identification by SMEs of that specific item type.
This may also lead to simplificaiton where libraries would only need to understand the item types they deal with directly.
In the end we’ve all used MARC21 differently to best describe our varied holdings – due to MARC21s “approximate” nature I really don’t see a universal application that will cover all cases. We’ll all have to dig ourselves out of the corner we’ve painted ourselves into with MARC21 and the more we stuff in the worse it gets.
Re: Browse and search BNB open data | First Thus, 2014-06-26
[…] Posting to RDA-L concerning Karen Coyle’s article at http://journal.code4lib.org/articles/5468 […]
Understanding MARC | Library Metadata, 2014-09-28
[…] web sites and other resources available with details about MARC. But, Karen Coyle has written a summary which is a good introduction for people looking for a quick […]