by Jason Clark
Introduction
With the maturation of web services giving rise to a stable development platform, Montana State University (MSU) Library decided to build a digital video library with YouTube as the data store and app engine. The live application from this experiment is the “MSU Library Channel” at http://www.lib.montana.edu/channel/. Over the course of this article, we will look at the design and reasoning behind our digital video library app, what it means to use YouTube as your database, how to create API requests that allow for different views of YouTube data, what kinds of metadata routines work best to organize YouTube data for a digital library setting, and finally how to optimize performance and archive data when relying on external web services to power an application.
YouTube as Application Platform
As we started to sketch out the blueprint for the project, our first consideration was formalizing the requirements for the application and making sure these requirements could be achieved using the YouTube Data API. As with any digital library app, we needed a discovery layer that included browse, search, and item views for all objects. The “Playlists”, “Search”, and “Videos” API methods could be applied to make this discovery layer. We needed a tool that allowed us to create rich enough metadata records to provide subject and keyword filters for browsing and searching the objects in the video library. The “Video Manager” component of the YouTube interface could be used to tag videos with keywords and group videos into prescribed subjects. And finally, we needed a simple video editing and uploading tool that would work in any web browser. Again, the “Video Manager” allowed for editing of all video details and enabled uploading of videos from just about any internet-enabled device.
With these requirements scoped out and the API ready to provide all the necessary functionality, the library put together a development group to build the app. This small working group included myself as lead developer and designer and Rhonda Borland, a library technician on the Cataloging and Processing team. Rhonda consulted on metadata for the application and had primary responsibility for archiving the data. Another working group within the library, the User Experience Group (UXG) was the sounding board for an early prototype of the application and championed its placement into production. It was a small (but agile) group that grew out of a singular research idea to apply a web service to a digital library production application setting.
The digital video application itself runs mostly using PHP and a few .htaccess tweaks. The steepest part of learning curve was understanding how to parse the structured data that is the foundation of the YouTube Data API. We chose to use the JSON-C format (a compressed, minimized version of JSON) because it allowed for a simpler parsing of key/value data objects and removed all extra markup, which made the API responses quicker.[1] At the time of this writing, we used version 2.0 of the API as version 3.0 was still tagged as “experimental” and subject to changes. An added benefit of version 2.0 of the API is the public nature of the JSON feeds which do not require developers to authenticate requests to receive data and build applications. While authentication was not required for our read-only use of the API, we did register as developers and receive a key to help YouTube understand our use of their API. There is more on the registration process in the “how to” section below entitled: “Web as Database: Using the YouTube Data API”.
Ease of workflow and usability for the application had to be intuitive and straightforward as we were looking for a tool that would allow simple uploads and editing of metadata. In this way, the YouTube “Video Manager” interface proved to be ideal. Project contributors to the digital video library, primarily the Access Services team and Digital Access and Web Services team, were given the library YouTube user account and could post videos, process videos using the YouTube video editor, and add metadata from any computer or device with access to YouTube.
With the prototype application up and running in the fall of 2012, we had anticipated a number of advantages in using the web service and some of these advantages started to play out.
- Scale: Using YouTube as a production layer for our web deliverable videos was simple and effective. Creation of videos and editing of videos was fast and easy. Adding metadata in YouTube and then re-applying that data to our application with the API made for a simple and efficient cataloging process.
- Discoverability: YouTube as a discovery platform and means to make content findable was an added bonus and the reach of our videos was reflected in YouTube analytics.
- Application of default tools and methods: Using the metadata index that is part of the YouTube Data API, we were able to create an interface that had a native, out of the box search functionality without having to build a local search index. In addition, we were able to use the chromeless YouTube video player (no need to code or download a video player script) which is fast and works across multiple devices and operating systems.
- Customization: APIs by their nature are data agnostic. The onus is on the developer to find a way to design and shape the raw data returned into a meaningful software interface. We were able to use the JSON data to rework application settings and data views to just about any user scenario: search, browse, embed, share, mobile, etc.
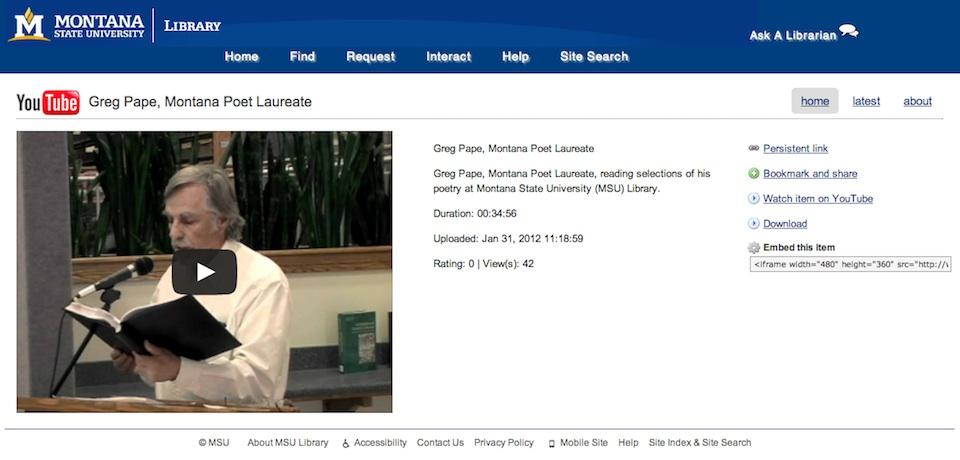
Figure 1. Item level view (http://www.lib.montana.edu/channel/item.php?id=jpPDkxWA2Q4)
With this app, we could create the item view that you see above, but behind the scenes we could add microdata and RDFa data to give our videos newer richer, semantic meanings. A “view source” on the item page above shows this additional schema.org markup.[2]
<ul class="item" vocab="http://schema.org/" itemprop="about" itemscope="itemscope" itemtype="http://schema.org/VideoObject" typeof="VideoObject">
<li class="item-play">
<iframe itemprop="video" width="480" height="360" src="http://www.youtube.com/embed/jpPDkxWA2Q4?hd=1&modestbranding=1&version=3&autohide=1&showinfo=0&rel=0"
frameborder="0"
allowfullscreen>
</iframe>
</li>
<li class="item-info">
<p><span itemprop="name" property="name">Greg Pape, Montana Poet Laureate</span></p>
<p><span itemprop="description" property="description">Greg Pape, Montana Poet Laureate, reading selections of his poetry at Montana State University (MSU) Library.</span></p>
<p>Duration: <span itemprop="duration">00:34:56</span></p>
<p>Uploaded: <span itemprop="datePublished" property="datePublished">Jan 31, 2012 11:18:59</span></p>
<p>Rating: <span itemprop="aggregateRating">0</span> | View(s): <span itemprop="interactionCount">42</span></p>
</li>
<li class="item-social">
<p><a class="permalink" property="url" title="permalink for Greg Pape, Montana Poet Laureate" itemprop="url" href="http://www.lib.montana.edu/channel/item/jpPDkxWA2Q4">Persistent link</a></p>
...
Of course, the web service model and distributed nature of using an external service and data source to power a local application also had some drawbacks.
- Ownership of data: Questions about who owns the data have to be addressed. What do the Terms of Service (TOS) say about ownership of data and how data can be consumed via the API? YouTube’s TOS (http://www.youtube.com/t/terms) allows the creator to retain ownership and local archiving of files and associated metadata ensured that we would have access to the data.
- Accounting for the network: Building the application to work well over a network, to route around latency issues, to use local files when necessary requires some development overhead and planning. It is not prohibitive, but external data brings some complications into the mix.
- Working with an external partner: Using a web service is an implicit contract with a partner. This partner can change the TOS and the types of data can be used in your applications. Taking time to understand the agreement between the two parties sharing data is essential.
Web as Database: Using the YouTube Data API
In order to apply YouTube as a data store layer for the app, we needed to learn a number of things: how the REST API could be used; how to apply metadata control to that environment; and finally how to parse and turn the JSON-C response into HTML for display in the app. To give us a bit of context going forward, the logic and display for the application is built around five main files:
- config.php – configuration settings and common variables used throughout the app
- index.php – home page for the application with main navigation
- list.php – sort page for the application listing related videos
- search.php – search routine and search results page
- item.php – item level view of a video (includes video player and metadata for each video)
A first step in our using the YouTube Data API was registering a developer key.[3] (If you are interested in developing your own app, you can get a developer key, by visiting http://code.google.com/apis/youtube/dashboard/.) Once we had a key, we were ready to get started making calls to the API. Typical calls to the API are made using simple HTTP GET requests via specific URL values. For example, the API request that produces the JSON-C data behind the home page for the application looks like:
https://gdata.youtube.com/feeds/api/users/msulibrary/uploads?v=2&alt=jsonc&max-results=10&key={YOUR_API_KEY_HERE}
And the request to the above URL returns a JSON result like the one below.
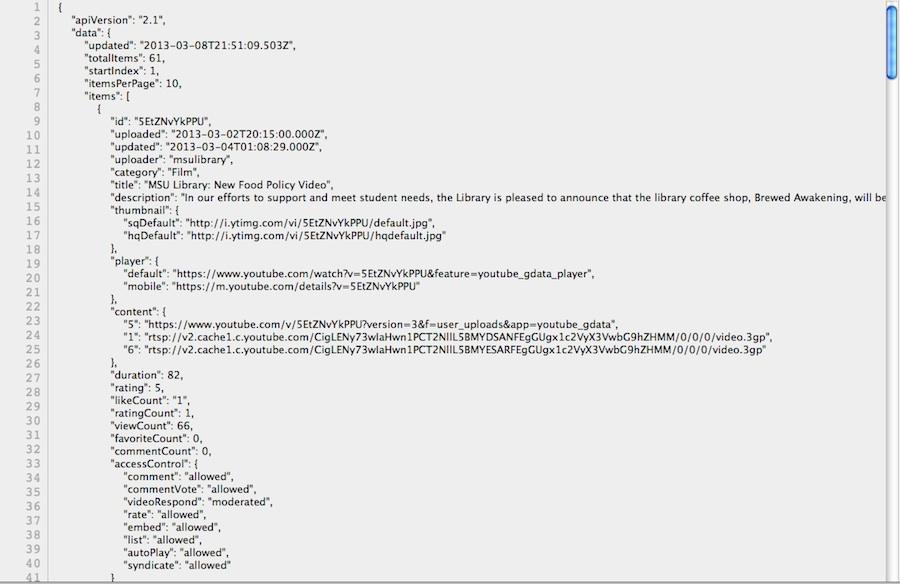
Figure 2. Structured data result from YouTube Data API JSON-C call
Converting this data into something meaningful for a user was another significant piece of the development time. However, once the application settings, API call, and parsing routine was in place, we were able to develop the other application views relatively quickly. Here’s an example of the PHP code template that allows us to filter and list all videos based on the assigned subject (list.php).
*Note that the default values at the beginning of the code sample here would be in the config.php file and included when needed as application settings. They are included here to provide a full picture of the script.
<?php
//set default value for developer key
$key = isset($_GET['key']) ? $_GET['key'] : '{YOUR_API_KEY_HERE}';
//set default value for user, page will show this user's videos
$user = isset($_GET['user']) ? strip_tags(htmlentities($_GET['user'])) : 'msulibrary';
//set default value for API version
$version = isset($_GET['v']) ? strip_tags((int)$_GET['v']) : '2';
//set default value for API format
$form = isset($_GET['form']) ? strip_tags(htmlentities($_GET['form'])) : 'jsonc';
//set default value for page start index
$start = isset($_GET['start']) ? strip_tags((int)$_GET['start']) : '1';
//set default value for page length (number of entries to display)
$limit = isset($_GET['limit']) ? strip_tags((int)$_GET['limit']) : '50';
//set default value for ordering results
$order = isset($_GET['order']) ? strip_tags(htmlentities($_GET['order'])) : 'published';
//set default value for subject (based on playlist title)
$subject = isset($_GET['subject']) ? strip_tags(htmlentities($_GET['subject'])) : null;
//set default value for subject id (based on playlist id)
$sid = isset($_GET['sid']) ? strip_tags(htmlentities($_GET['sid'])) : null;
//set feed URL
if (is_null($subject)) {
$feedURL = 'http://gdata.youtube.com/feeds/api/users/'.$user.'/uploads?v='.$version.'&alt='.$form.'&start-index='.$start.'&max-results='.$limit.'&orderby='.$order.'&key='.$key.'';
} else {
$feedURL = 'http://gdata.youtube.com/feeds/api/playlists/'.$sid.'?v='.$version.'&alt='.$form.'&start-index='.$start.'&max-results='.$limit.'&orderby='.$order.'&key='.$key.'';
}
//call API and get data
$request = file_get_contents($feedURL);
//create json object(s) out of response from API
$result = json_decode($request);
$totalResults = $result->data->totalItems;
//assign value for title of page
$pageHeading = is_null($subject) ? 'All Videos (library channel) - '.$totalResults.' videos' : $subject.' (library channel) - '.$totalResults.' Videos';
?>
<h2 class="mainHeading" id="media"><?php echo($pageHeading); ?>
<?php include 'meta/inc/nav.php'; ?>
</h2>
<?php
//parse returned data elements from api call and display as html
foreach ($result->data->items as $item) {
$title = is_null($subject) ? htmlentities($item->title) : htmlentities($item->video->title);
$id = is_null($subject) ? $item->id : $item->video->id;
$timestamp = is_null($subject) ? strtotime($item->uploaded) : strtotime($item->video->uploaded);
$uploaded = date('M j, Y', $timestamp);
$watch = is_null($subject) ? $item->player->default : $item->video->player->default;
$image = is_null($subject) ? $item->thumbnail->sqDefault : $item->video->thumbnail->sqDefault;
$description = is_null($subject) ? $item->description : $item->video->description;
$viewCount = is_null($subject) ? $item->viewCount : $item->video->viewCount;
$duration = is_null($subject) ? gmdate('H:i:s', intval($item->duration)) : gmdate('H:i:s', intval($item->video->duration));
?>
<ul class="object">
<li class="play">
<a title="<?php echo $description; ?>" href="./item.php?id=<?php echo $id; ?>"><img width="240" height="160" src="<?php echo $image; ?>" alt="<?php echo $description; ?>" /></a>
</li>
<li class="info">
<p><a title="<?php echo $title; ?>" href="<?php echo './item.php?id='.$id.''; ?>"><?php echo $title; ?></a></p>
<p><?php echo $description; ?></p>
</li>
<li class="social">
<p>View(s): <?php echo $viewCount; ?></p>
<p>Uploaded: <?php echo $uploaded; ?></p>
<p>Duration: <?php echo $duration; ?></p>
</li>
</ul>
<?php
}
?>
This code template holds up for most of the application with some tweaks here and there to accommodate specific data and interface needs, such as the microdata template that is part of the item level view for the app. Once this code was in place, we then adapted the routine for other data views – search, browse, item, etc. The other part of our development time was spent in understanding the YouTube Data API documentation and learning how to get the proper JSON-C results to return. But the learning curve here isn’t very steep, as the API documentation is clear and full of examples, including an interactive demo that allows you to run sample API requests at https://developers.google.com/youtube/articles/view_youtube_jsonc_responses.
Metadata Standards
Setting metadata standards to organize and tag the videos was another essential requirement. We went with singular identifying keywords in the YouTube “tag” field to help create searchable keywords for the index. All content editors were given the preferred terms and asked to assign them. Populating the search index with relevant metadata was important, but even more crucial was finding a way to organize the browse headings for the application. The “Playlists” component of the Video Manager interface allowed us to group sets of videos and proved to be the best method in this regard.
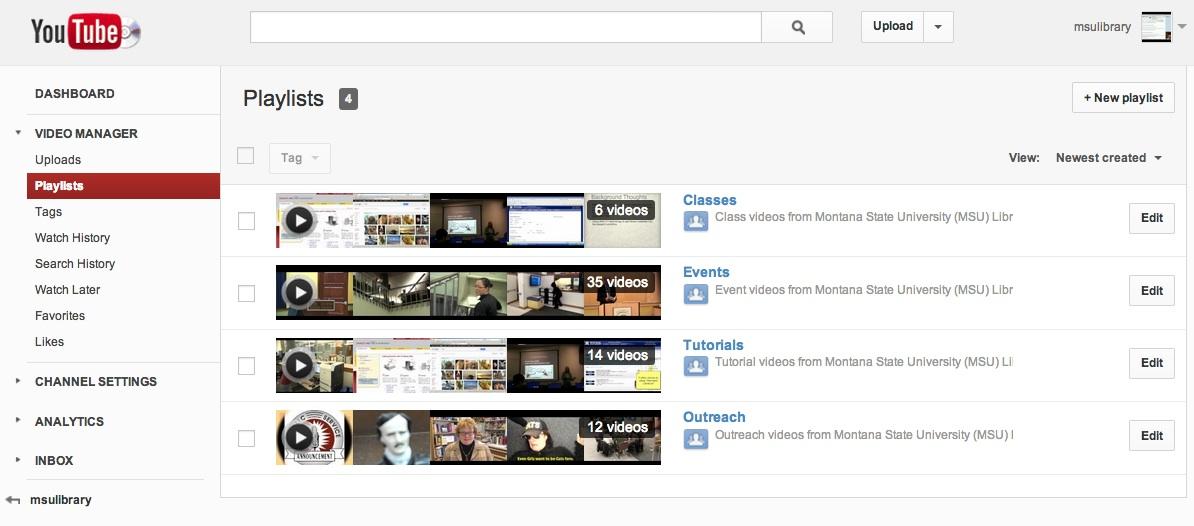
Figure 3. YouTube Video Manager interface applying playlists as subject categories
After creating a series of playlists in the Video Manager interface (see Figure 3), we could use them to create two essential views in the public interface for the app: a dynamic list of controlled vocabulary subjects for the index page (index.php) and a browseable list of all videos organized around a particular subject for use on the list videos page (list.php). As a core method in the API, the Playlist query parameter enabled these two essential data views.[4] First, we used a query to the “list user’s playlists” parameter of the API to set up a controlled vocabulary of subjects.
https://gdata.youtube.com/feeds/api/users/msulibrary/playlists?v=2&alt=jsonc&key={YOUR_API_KEY_HERE}
With the results from this API query, we could build the internal navigation on the index page and allow the interface to adapt to new playlists (subjects) if they were needed in the future. We could also use the “list user’s playlist entries” parameter of the API to create the listing of related videos when viewing the list videos page (list.php) at http://www.lib.montana.edu/channel/list.php. The actual API call is below.
http://gdata.youtube.com/feeds/api/playlists/PLVFp_Q_GRmrCgJrODEUSw0qG1c8geWFwm?v=2&alt=jsonc&start-index=1&max-results=50&orderby=published&key={YOUR_API_KEY_HERE}
We actually used the interface layer of the application to reinforce the controlled vocabulary by pointing editors to the listing of subjects in the browsing sections of the application and reminding editors how assigning videos to certain playlists would make a video appear under a certain public list view. You can see the subject “Classes” at http://www.lib.montana.edu/channel/list.php?subject=Classes&sid=PLVFp_Q_GRmrD3h1bOXL3gq4kZ2zRA_jE4
The broader metadata categories prescribed within the YouTube Video Manager interface were only helpful in classifying our videos for the broader Google and YouTube search indexes. As such, most of our videos are categorized as “Education”. We also ran into some quirks in identifying authors/creators within the standard YouTube fields. As an institutional account, the creator was always identified as “msulibrary”, our institutional username for YouTube. Our workaround was to include author/creator info in the “title” and “description” fields. Not a perfect solution, but it did enable author/creator data to be discovered in searching and browsing values from our API requests.
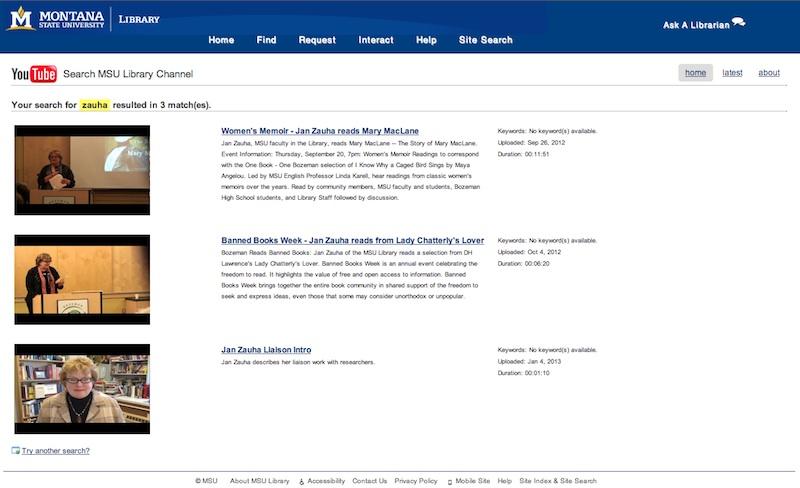
Figure 4. Search result view based on author/creator values
Caching, Optimizing, and Archiving
Using an external data service can be liberating, but also requires some extra thought related to architecture and performance for the app. The YouTube Data API has a terms of service (TOS) and responsible use policy – https://developers.google.com/youtube/terms. While the TOS is not overly restrictive, it does provide some rules for non-commercial use of the data and guidelines for attribution (recognizing somewhere in your design that YouTube data is making your application run).
Our library staff is active in creating and uploading videos, but there is no real need for dynamic, real-time querying of our YouTube data. To keep application performance steady, we created a caching routine that stores API requests as local files for a few minutes. This not only helped with performance, it made us a more responsible consumer of the API since we used only the data and API calls needed to run our app. Our caching routine keeps our use of the YouTube Data API within responsible limits.[5] These “stored” files located in a /cache/ directory are served up until a timestamp on the file expires. The /cache/ directory is writeable by Apache and dynamically stores the files as necessary. The caching routine is dependent on two PHP code snippets. The first snippet (cache-begin.php) is included as the first lines in any file that needs to be cached locally.
<?php
$url = isset($_SERVER['REQUEST_URI']) ? strip_tags(htmlentities($_SERVER['REQUEST_URI'])) : null;
if (parse_url($url, PHP_URL_QUERY)) {
$file = basename($_SERVER["SCRIPT_NAME"], '.php');
$query = str_replace("=", "-", parse_url($url, PHP_URL_QUERY));
$cachefile = 'cache/cached-'.$file.'-'.$query.'.html';
} else {
$file = basename($_SERVER["SCRIPT_NAME"], '.php');
$cachefile = 'cache/cached-'.$file.'.html';
}
//set app to cache file for 3 minutes
$cachetime = 180;
//serve from the cache if it is younger than $cachetime
if (file_exists($cachefile) && time() - $cachetime < filemtime($cachefile)) {
echo "<!-- Cached copy, generated ".date('H:i', filemtime($cachefile))." -->\n";
include($cachefile);
exit;
}
ob_start(); // Start the output buffer
?>
With the caching routine started, a second snippet (cache-end.php) is included at the end of the file to be cached.
<?php // Cache the contents to a file $cached = fopen($cachefile, 'w'); fwrite($cached, ob_get_contents()); fclose($cached); ob_end_flush(); // Send the output to the browser ?>
With both snippets in place, the file is written to the cache directory and served on subsequent requests until the timestamp on the file shows that 3 minutes have passed.
Caching files was a primary way of ensuring snappy performance and responsible use for the app, but we put other methods in place to keep load times at a minimum. Our pages were loading well, but we used both Google’s PageSpeed (https://developers.google.com/speed/pagespeed/) and Yahoo!’s YSlow (http://developer.yahoo.com/yslow/) to find performance bottlenecks and gotchas. With guidance from these tools, mod_deflate compression directive was added to the Apache .htaccess file to make sure all relevant files were as small as possible to reduce bandwidth over the network. An example of the mod_deflate directive which compresses Javascript files, CSS files, HTML files, and PHP files is below.
#compress files for web optimization <IfModule mod_deflate.c> <FilesMatch "\.(js|css|html|php)$"> SetOutputFilter DEFLATE </FilesMatch> </IfModule>
Preservation
Along with the performance and bandwidth concerns, we looked into archiving and how to best provide a record of the application if an external service, like YouTube, went away or discontinued the API. We had an advantage in archiving the video objects as all the library video content had been created in house. These master copies of videos are stored within an /objects/ directory in the app. We also downloaded the web-processed .mp3 files from the YouTube Video Manager interface as derivative copies of our videos. Videos are identified as “web” or “original” and the filenames use the unique YouTube id that is assigned once the videos become part of the MSU Library YouTube account. We also archive a primary thumbnail that is identified in the JSON-C feed and add it to the /objects/ directory. With these video and image objects archived, we needed to find a way to preserve all of the metadata that was part of the YouTube data store. A simple command line procedure allows us to make an API call and store a text file with all of the data.
wget --no-check-certificate -O _msu-channel-meta-archive.json 'https://gdata.youtube.com/feeds/api/videos?author=msulibrary&orderby=published&start-index=1&max-results=50&prettyprint=true&alt=json&v=2' 'https://gdata.youtube.com/feeds/api/videos?author=msulibrary&orderby=published&start-index=51&max-results=50&prettyprint=true&alt=json&v=2'
By using a wget command and concatenating two separate API requests into an output file, we are able to produce a .json file that has all the metadata from the first 100 objects in our YouTube account. As the account grows, we can adjust the archive by adding additional requests for the next 50 objects using the start-index= parameter. In the longer term, a CRON job will be set up to run this wget command and create the metadata archive automatically.
Next Steps and Future Directions
We see the work mentioned here as the first phase in the development of this digital video app. There is more room to adopt these methods for a larger scale digital library project. With the next phase of the project, we would like to integrate the YouTube Analytics API into how our videos are prioritized in search results and browse points. On the management side of things, building an interface that allows for batch uploading and prescribes tighter metadata controls would be a logical next step. Additionally, a more atomic approach to user authentication within the application would help in making it more suitable for multiple editors spread across different workspaces. From an interface perspective, a mobile view for the videos is a necessary improvement. To this end, we have put together a little widget to help generate interest in the mobile possibilities for the project at http://www.lib.montana.edu/~jason/files/video-widget/index-youtube.php. And finally, we think there is a real opportunity to repurpose the video data and format it to be harvested by other channels and distribution outlets. Reworking the JSON feed into a sitemap.xml file for the Google search index or an XML feed which would create a presence in iTunes or the Google Play store could be one more way to apply the API and get our videos found and watched.
Conclusion
With a little planning, these REST-based web services can be used to create digital library apps that work in production settings. These types of web services can help a smaller web development shop build a scalable digital video library. Using the administrative and processing tools that are default parts of YouTube services limits the need for additional staff to finalize video objects. Learning to harness the metadata controls that are part of the YouTube Video Manager interface allows a small team to create filters and views around a controlled vocabulary to organize the digital library. And finally, writing simple, reusable code to parse and display the structured data returned from API calls, enables a single developer to create an HTML interface that has all the features of a simple digital library video application. With these methods in place, digital library development is within reach for all types of libraries.
* The complete code for the digital library video application is available on my github page at https://github.com/jasonclark or as a .zip file on my site at http://www.jasonclark.info.
Notes
[1] Full details of the YouTube Data API JSON-C developer’s specifications are at https://developers.google.com/youtube/2.0/developers_guide_jsonc
[2] Schema.org is a collection of schemas (controlled vocabularies and entity relationships) that govern how HTML microdata markup can appear on a web site. Google, Bing, and Yahoo created the schemas as a means to guide intelligent, semantic markup creation for web properties. Visit http://schema.org/ to learn more.
[3] A key is usually a unique alphanumeric string that allows for the API provider (YouTube) to identify the API consumer (the developer). In the case of the YouTube Data API, we also get access to analytics and usage rates related to use of our digital video library app.
[4] The Playlist API parameters of the YouTube Data API are documented in detail. Version 2.0: https://developers.google.com/youtube/2.0/developers_guide_protocol_playlist_search and Version 3.0: https://developers.google.com/youtube/v3/docs/playlists
[5] Responsible use quotas for the YouTube Data API are fairly generous. Version 2.0 of the API has limited information on rate limits, but Version 3.0 allows for 5,000,000 units/day.
Works Consulted
Fu, Liuliu, Kurt Maly, Harris Wu, and Mohammad Zubair. “Building Dynamic Image Collections from the Internet.” Digital Humanities, King’s College London – July 7-10 (2010). http://dh2010.cch.kcl.ac.uk/academic-programme/abstracts/papers/html/ab-863.html. http://dh2010.cch.kcl.ac.uk/academic-programme/abstracts/papers/pdf/ab-863.pdf
Lara, Juan Alfonso, David Lizcano, María Aurora Martínez, and Juan Pazos. “Developing front-end web 2.0 technologies to access services, content and things in the future internet.” Future Generation Computer Systems (2013). http://www.sciencedirect.com/science/article/pii/S0167739X13000204
Maximilien, E. Michael, Ajith Ranabahu, and Karthik Gomadam. “An online platform for web apis and service mashups.” Internet Computing, IEEE 12, no. 5 (2008): 32-43. http://ebiz.u-aizu.ac.jp/~paikic/lecture/2008-2/adv-internet/Presentation/WebAPIServiceMashup.pdf
McWilliams, Jeremy. “Developing an academic image collection with Flickr.”Code4Lib Journal 3 (2008). http://journal.code4lib.org/articles/74
Steiner, Thomas, Ruben Verborgh, Rik Van de Walle, Michael Hausenblas, and Joaquim Gabarró Vallés. “Crowdsourcing event detection in YouTube video.” (2011): 58-67. https://biblio.ugent.be/input/download?func=downloadFile&recordOId=2003129&fileOId=2003140
Topps, David, Joyce Helmer, and Rachel Ellaway. “YouTube as a Platform for Publishing Clinical Skills Training Videos.” Academic Medicine 88, no. 2 (2013): 192-197. http://journals.lww.com/academicmedicine/Abstract/2013/02000/YouTube_as_a_Platform_for_Publishing_Clinical.20.aspx
About the Author
As head of Digital Access and Web Services, Jason A. Clark builds library web applications and sets digital content strategies for Montana State University Library. He writes and presents on a broad range of topics including mobile design & development, web services & mashups, metadata & digitization, Javascript, interface design, and application development. When he doesn’t have metadata and APIs on the brain, He likes to hike the mountains of Montana with his wife, Jennifer, their daughter, Piper, and their dog, Oakley. You can find him online at http://jasonclark.info/ or on the twitters at @jaclark. You can reach him by email at jaclark@montana.edu.

Subscribe to comments: For this article | For all articles
Leave a Reply