by Julia Kim, Rebecca Fraimow and Erica Titkemeyer
As professionals in the field of archival science, we aim to follow ‘best practice’ procedures, established standards that have been tested and proven to provide access to collections over the long term. However, for archivists aiming to preserve born-digital audiovisual files, ‘best practices’ often boil down to ‘it depends.’ The Federal Agencies Digital Guidelines Initiative (FADGI) Audio-Visual Working Group, for example, recommends that archivists “develop selection criteria based on business needs,” “determine and document criteria for when (if ever) it is appropriate to change the video file’s technical properties,” and “create copies with appropriate technical characteristics to meet expected use cases.”[1] And while numerous reports and papers have assessed and compared standardized formats for long-term video preservation, arguing the benefits of losslessly compressed codecs designed for audiovisual digitization, such as JPEG 2000[2] and FFV1[3], the vast majority of born-digital audiovisual formats that an archivist is likely to encounter in the wild are significantly less well-documented and discussed in the field.[4] ‘Best practice’ is hard enough to determine and follow when you have control over the creation of the media, but even more challenging when accessioning files created by donors, producers, and folklorists that never followed ‘better’ practices to begin with.
The sheer conditionality of recommendations leaves practitioners mired in a sea of questions as they struggle to set realistically adhered to policies for their institutions. Should files be accepted as-is, or transcoded to an open and standardized format? When is transcoding to a preservation file specification worth the extra storage space and staff time? If transcoding, what are the ideal target specifications? When developing policies and workflows for batch transcoding a variety of different formats, each with different technical specifications, how do you make sure that preservation files maintain all the perceptible, let alone “significant” characteristics of the original files?
This paper presents case studies from three institutions — a university special collections library, a federal government department, and a public broadcasting station — demonstrating how the factors listed above might lead to ‘tiered’ processing and decision-making around ‘good enough’ practices for the preservation of born-digital a/v files. Erica Titkemeyer, the University of North Carolina at Chapel Hill Project Director and Audiovisual Conservator; Julia Kim, the Digital Assets Specialist at the American Folklife Center at the Library of Congress; and Rebecca Fraimow, the Digital Ingest Manager at the WGBH Media Library and Archives and the American Archive of Public Broadcasting will each discuss how factors such as institutional mission, stakeholder needs, and available resources play into management of risks such as format obsolescence, file complexity, and preservation backlog.[5]
University of North Carolina at Chapel Hill
By Erica Titkemeyer
I coordinate large-scale digitization of obsolete audiovisual recordings at Wilson Library Special Collections, but I also provide guidance on born digital processing of audiovisual files across collecting units in the library. One of our biggest challenges is adapting born-digital workflows to include audio and video files of mixed formats, with the goal of documenting, processing and ingesting collections as efficiently as possible with the few dedicated staff we have.
Within Wilson Library Special Collections at the University of North Carolina at Chapel Hill (UNC), acquisitions of born-digital content have begun to grow in parallel to our large-scale digitization efforts for analog audiovisual and manuscript materials. Looking specifically at born-digital audiovisual media, content appears most frequently in the Southern Folklife Collection, which collects, preserves and disseminates vernacular music, art, and culture related to the American South. Acquisitions can include a myriad of recordings, from live musical performances and oral histories to raw documentary elements.
Any given accession can range from a handful of gigabytes to well over a terabyte in some of our larger acquisitions. Originally, these files had to remain on the media they arrived on (most often external hard drives and optical disks) due to storage limitations, but as digital storage capabilities have improved over the last decade, long term preservation of these files has become increasingly possible.
At the moment, the primary long term digital storage location for UNC Libraries is the Carolina Digital Repository (CDR), a Fedora-based digital archive “for scholarly works, datasets, research materials, records, and audiovisual materials.”[6] Ingest into the CDR is typically the final step in our processing workflows, followed only by the creation of MODS metadata records by our Technical Services department, allowing everything to be accessible to UNC students, faculty, and scholars.
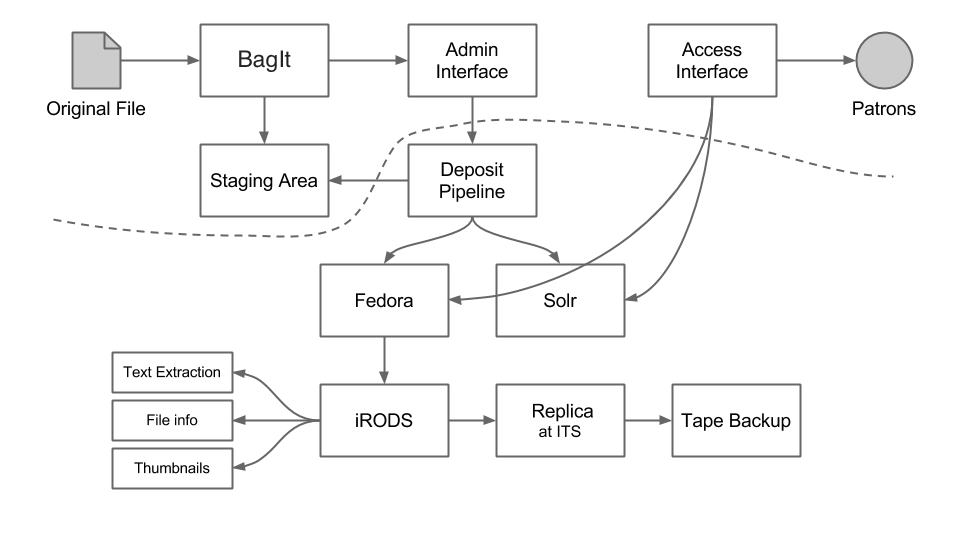
Figure 1. Carolina Digital Repository architecture represented below dashed line, and pre- and post- ingest steps shown above dashed line.
However, as the following case studies will show, we have found that audiovisual media challenges many of our pre-ingest workflows while questioning policies in ways that text-based files have not. This has required staff to review and amend exceptions to policies to introduce feasible alternative actions for audiovisual files before they are ready for ingest.
Case studies
The following examples of born-digital audiovisual acquisitions help to explain the types of hurdles we encounter and the ways in which making exceptions to our standard born-digital preservation workflows help us to produce best possible results considering our limitations at the time. In all instances we have to consider the level of quality of the content and how much storage it warrants, and the amount of time and resources we can dedicate to it at the time of processing.
Limiting files sizes
It’s usually not the case that we don’t have enough digital storage space for a large file, but we have to recognize that if the size of the file can be decreased, it means more space for future priorities down the road. In my environment, the decision of whether or not to compress a file or to alter it in any way has to include input from the curator who acquired the collection where the file resides. The curator is more often than not the individual with the most knowledge about the content and the consequences of these actions to the patrons.
The first case involving compression happened with an acquisition by the University Archives and Records Management Services department and related to non-professional, unedited footage of a recent graduation ceremony, for which the department already had professional footage. The file was 112 gigabytes and encoded using the Apple ProRes[7] codec. Apple ProRes is considered an intermediate lossy codec (though Apple prefers “virtually lossless” when referring to its high-end flavors of the codec). Its primary use is in editing environments, and it allows for files to be more easily manipulated and rendered compared to their original raw masters. Even though it is small enough to be managed by editing software, the encoding still permits high enough quality that the file can exist as a base for creating derivatives of lower quality to distribute across different platforms.
As an experiment, the graduation file was transcoded to meet our digitization specifications (FFV1 in the Matroska wrapper[8]). FFV1 is a lossless video codec, meaning it is capable of compressing and uncompressing a file without permanently losing bits (unlike lossy codecs, which shave off bits during compression). In audiovisual digitization, it is ideal for minimizing the size of uncompressed files typically generated in digitization workflows. As we suspected, this solution did not work, as the file did not decrease in size. Instead, it doubled in size.
Knowing that the ultimate solution would likely be to use a lossy codec, the curator was contacted about the necessary deletion of bits from the file itself if we were to expect a decrease in size. Since this was not the only footage of the ceremony, and it was already low quality in terms of production value, the curator agreed to the compression. Ultimately, we decided on the h.264 codec,[9] as it is common in media player libraries and thus could be played back by users using a variety of software programs. Another benefit is that it is a relatively stable format that it is well documented and known by users in fields beyond audiovisual preservation.
We used the following command for transcoding the original:
ffmpeg -i -c:v libx264 -pix_fmt yuv420p -crf 12 -c:a copy [destination]
After transcoding, the resulting file was 53 gigabytes, roughly half the size of the original. The -crf (Constant Rate Factor) option is where we were able to manage control over quality, and consequently, file size. An alternative we could have used was the Two-Pass Average Bitrate (ABR) option, which accepts a target bitrate to control file size output, but does not give us control over quality.
The value of 12 was chosen based on FFmpeg’s documentation[10], which outlines the scale values for the CRF option (0-51), where 0 is lossless. Output files using values of 1-18 remain visually lossless (but not technically lossless). From testing, the value of 12 was sufficient enough in decreasing file size, while also remaining within the 1-18 target range.
Is this thing on? Video files with no video
Another situation that I come across with surprising frequency is a video file without actual video. Usually the lens cap is left on, as the producer only wishes to have an audio recording, or they wish to keep the speaker anonymous. Either way, the presence of video means the file is much larger than it really needs to be if we’re only concerned about the audio stream within it. In all cases where this has taken place, I have used FFmpeg[11] to create a standalone audio file from an audio stream in a video file, which is then considered the preservation file for ingest. Depending on the duration of the file and the original video stream encoding, this alteration can greatly decrease the amount of digital storage needed.
The command I used came from ffmprovisr[12], a resource for using FFmpeg with example commands for archivists:
ffmpeg -i -c:a copy -vn [output file]
For these cases, it is important to note that documentation of what has been done to the original will be valuable information to future stewards and researchers, so a note (.txt file) is added to an admin folder, along with additional submission documentation, including technical metadata about the original file. This admin folder is bagged along with the media and ingested into the CDR.
The case of the hybrid hard drive
In Fall 2016 I started working through a backlog of digital media, including a one terabyte hard drive from a local musician that had been included in a larger acquisition. Fortunately, the drive wasn’t completely full, but it did contain a few hundred gigabytes of data. Unfortunately, the content was far from consistent in file types. In addition to JPGs, PDFs and Word documents, there were close to 1600 audiovisual files representing twelve different file formats and fifteen different variations of formats and codecs. The actual identification of these files was the first challenge, as many tools used in born-digital processing do not always identify specific stream codecs, only formats. In addition to using DROID[13] to identify extensions (we have now moved onto using Brunnhilde[14]), I also employed FFmpeg’s FFprobe feature, which can reliably report out audio stream and video stream codecs. It was at this point that I realized identifying the codec of each file early on would be helpful in determining file quality and the available possibilities for normalization or migration, either pre-ingest or in the future.

Figure 2. Example DROID output of MOV files without any codec information. The PUID, MIME_TYPE, FORMAT_NAME and FORMAT_VERSION fields were all empty
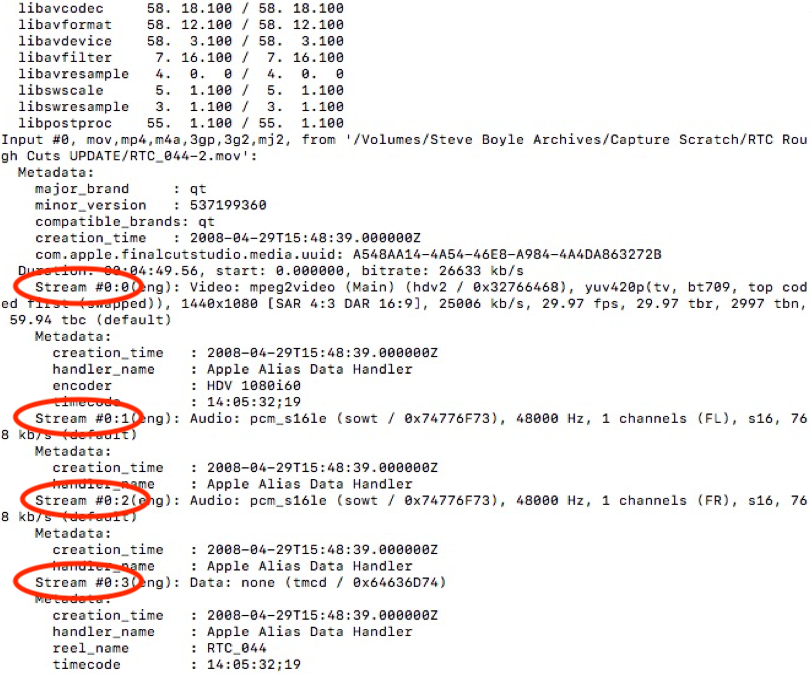
Figure 3. Default output using command ffprobe [file]. Metadata is reported on all four streams, including codecs for audio and video streams.
The additional FFmpeg step also allowed me to see if there was any embedded metadata within the files that would need to travel with the ingest package into the repository and that would be at risk of loss if we were to choose to transcode files prior to transfer. Fortunately for me (or unfortunately, from a metadata perspective), most of the files found did not contain descriptive information (title, artist, copyright statement, etc).
Now that I knew as much as I could about the files, it was time to make decisions about what, if anything, to do to them prior to ingest. Knowing that transcoding the files to our preservation specifications would increase their size greatly and unnecessarily, I struggled to find a solution, especially for the files that were wrapped or encoded with proprietary and/or obsolete formats and codecs. Considering my position priorities to coordinate analog audiovisual digitization, I had to make the difficult choice of putting the work of ingesting such a large drive back in my backlog of work to do (after creating a duplicate copy on our servers). I had, however, succeeded in documenting as much as I could about the files.
Since then, and under the leadership of Jessica Venlet (UNC, Assistant University Archivist for Records Management and Digital Records) we have developed more robust format policies and a more substantial set of expertise (from full-time staff to graduate student assistants) to enlist for guidance and to carry out born-digital processing tasks. These additional aids will inevitably help in tackling more complex ingests such as the hybrid hard drive, and it will be interesting to see how it eventually finds its way through our workflows. Potentially we will ingest the files as is or transcode a certain subset of files to a more stable format. Either way, we now have familiarity with the additional steps required for documenting audiovisual file specifications to get us started.
American Folklife Center at the Library of Congress
By Julia Kim
The American Folklife Center (AFC) at the Library of Congress was created in legislation to honor the United States’ Bicentennial in 1976, and charged with a mission to capture all manner of folklife. AFC is thought to be the largest folkloric and ethnographic archive in the world, and in recent years, AFC’s acquisitions have become primarily digital.[15] As the sole full-time digital staff member in the department, I create workflows for our multi-format digital and digitized collections; train and manage staff; support our databases and applications; and, increasingly, liaise with donors, vendors, and cultural organizations. Until recently, AFC was not a part of the Library Services or Special Collection units. The geographic and information technology systems separation from the Culpeper Audiovisual facility also impacts our division’s audiovisual workflows.
One of our key archival workflow strengths is that we have essentially limitless long-term tape server storage. We currently store approximately 600 TB on long term tape servers, with an additional 30 TB for online web-accessible collection space, and 20 TB on processing server space. This will dramatically increase as we begin systematically digitizing all our audiovisual assets.
In addition to serving researchers and visitors in the reading room, AFC has pushed more of its multi-format content online, essentially reprocessing many of its digitized and born-digital collections to meet the technical requirements for online access.
As the major time-based media special collection division on Capitol Hill at the Library, audiovisual files skew our long term digital repository server space needs to the very high end. This naturally influences our workflows. File format normalization upon ingest is not routine, and migration and normalization of time-based media only occasionally happens when preparing content for online access platforms.[16] AFC’s born-digital video collections vary greatly in size and complexity. This means that I have to take a conscientious approach to assessing collections, which I do by giving collections numbers on a 1-4 scale to denote first, the 1) complexity and technical challenges to the collection, and 2) the resources the department is going to allocate to the processing.[17] As our collections increase rapidly in size, I’m more often forced to give most collections minimal processing for the time being. This is noted in the case studies below.
Like many institutions, our workflows are hampered by strict security restrictions that make common software tools and streamlined workflows difficult to implement. Our biggest challenge, however, is that other than myself we have no dedicated digital processing staff. Most standard workflows are carried out by part-time temporary staff external to our department. Other than that, we have one full-time archivist who dedicates a handful of hours a week to digital processing, dependent on priorities. This can easily mean that many part-time individuals handle the processing of a single large collection over a long disparate period of time.
The majority of the collections I handle had been ingested many years ago, but have been earmarked for reprocessing. My processing priorities mostly involve reprocessing work with external vendors, donors, or for publishing collections online.
Case Studies
Many of our born-digital collections have been created “in the field” in un-ideal environmental conditions or with a mind to the cultural content rather than technical specification. They may also have followed a specification from another geographic area with a now-bypassed broadcast standard, and most of our content creators are not experts on these technologies.
Cleaning out our closets
This recent test case is part of a much larger department initiative to uncover our hidden “fugitive media” and then, subsequently, migrate all the optical media.[18] This particular collection was earmarked early on because of its cultural value and its large size – over 400 optical disks – but it was part of a large-scale batch processing workflow, so for the initial pass, it was processed minimally. Work was streamlined as much as possible by migrating all the optical content and files “as is,” while also retaining all disk images and logs.[19] This means that each submission package has unusually complex file and directory structures that go 5-6 layers deep.
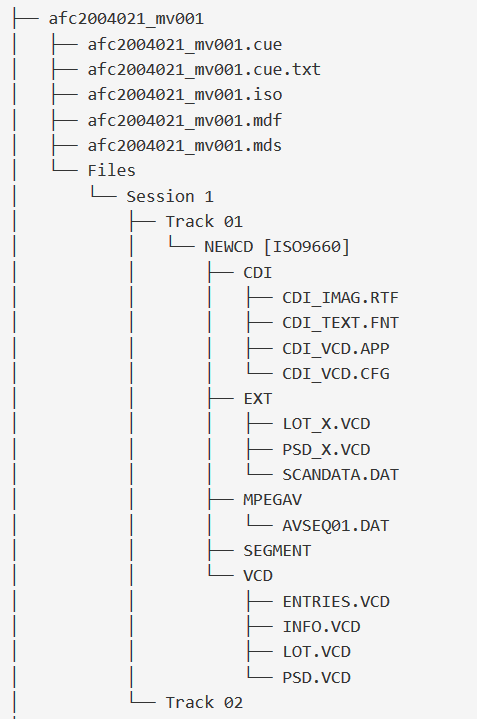
Figure 4. Top level directory and file level hierarchy created
But there are some ambiguities: the optical DVD are all encoded with the older VCD MPEG1 encoding in the PAL (or “Phase Alternating Line”) broadcast standard. Their native resolution is very poor; it’s not in current use or widespread.[20] The MDF and MDM disk image formats are also proprietary and obsolete disk image types.
The norm, however, for these types of collections is to leave them as-is. This is true for many of the obsolete files uncovered through the media migration project this collection was a part of. The priority for these uncovered collections, many over a decade old, is migrating them from their unstable and deteriorating carriers and, essentially, accessioning and ingesting them. AFC is able to initiate this project in large part because the staff primarily undertaking the work are non-AFC technicians who rotate through the department. Future work will necessarily involve active preservation work on at-risk obsolete files uncovered in this migration project, including quality control of outputted files and improving systems to streamline migration of the many different flavors of optical uncovered through this project. One small step I’ve taken for this collection subsequently was combining the MDF and MDM file into a more generic and singular disk image ISO.
Give a folklorist a camera
AFC often directly creates or funds many of its collections through supporting fieldwork fellows, public programming, lectures, and concerts that become documented and accessioned as archival collections. These collections are unusually heterogenous and non-standardized, so workflows must be tailored anew each time. These collections were urgently prioritized for online display. While the videos themselves are static, captured from a camera on a tripod focused on the interview subject in nondescript rooms, the unnecessary complexity – as well as the ambiguities of the technical specifications – are a good case study for why we need to have interventions with the content creators earlier.
In preparing these videos for publication online in our access system, I noted some odd unintended visuals called “combing,” which is a perceptible error noted in digital environments when the content creator creates interlaced audiovisual files meant to conform to analog technologies.[21] While I could deinterlace for access and maybe preservation, I still had to ask myself: was this intentional? This small collection of 20 born-digital audiovisual files had at least 4 different flavors of files with varying aspect ratios, audio, and moving image codecs, and of course, extensions. It seemed reasonable to assume that these were accidents rather than artistic choices. Other than normalizing for online browser display, they’re not earmarked for transcoding.[22]

Figure 5. Technical metadata from “ffmpeg -i” command with information on the component video, audio, and data streams in this collection’s audiovisual files.

Figure 6 Detail of interlacing or “combing” in born-digital video
Let’s Try Again… a few more times now
Unlike the last three collections, this collection is one that I’ve been involved with earlier in its life cycle. I now often engage content creators before accessioning to discuss how their work impacts my preservation work down the line. In this case, the content creator was an ethnographer who had recently switched from still image work to audiovisual work. While the documentarian shot in a proprietary format (HD AVCHD – MPEG 4 avc/h264 .mt2s), he edited down hundreds of hours of footage in another proprietary software program to overlay separately captured audio interviews. So before I received any files, he had already twice modified the technical characteristics in producing the final films. In this case, we are not accepting the raw footage; all stakeholders agree that this is not warranted. After discussions with the donor, we decided to also receive the uncut audio files. After some research, I discovered that the files sent represented a loss of significant data and resolution from the edited down files (see table below). In addition to more obvious changes in the video codec, the table of excerpted technical metadata below also shows that data was lost and resolution decreased from 1920×1080 pixels to a significantly lower resolution of 1440×1080. Another potentially highly perceptible change are the different aspect ratios noted by SAR (screen aspect ratio) and DAR (display aspect ratio, what most people think of when they say “widescreen), but these different ratios indicate that the pixel aspect ratios will also be different, ultimately influencing the image. This was an inadvertent loss only caught through understanding the entire content workflow chain, pre-acquisition. In this and many other cases, just giving content creators specifications without ensuring they understand their context misses the point.
| File assessed | Video stream codec | Color sampling and encoding, resolution, aspect ratios, data rates, frame rates, and more |
| Interim video | Stream #0:0[0x1011]: Video: h264 (HDMV / 0x564D4448) | yuv420p(top first), 1920×1080 [SAR 1:1 DAR 16:9], 29.97 fps, 59.94 tbr, 90k tbn, 59.94 tbc |
| Final Edited Output | Stream #0:0[0x810]: Video: mpeg2video ([2][0][0][0] / 0x0002), | yuv420p(tv, bt709, top first), 1440×1080 [SAR 4:3 DAR 16:9], 29.97 fps, 29.97 tbr, 90k tbn, 59.94 tbc |
The content creator re-exported his finalized files to a compromise codec that kept the most significant characteristics intact, but he was concerned over whether or not his home computing environment could handle the processing. In this case, because of the combined aesthetic and technical value in the content captured, these extra processes were something that both the content creator and I were happy to spend additional time on. Unlike the previous collections, these moving image files captured minute technical work and had aesthetic and scenic value. This arrangement is also foundational for our ongoing acquisitions with this donor and has new accessions planned. This new type of workflow, in which there are often months of intermittent conversations with a donor pre-accessioning, is now something I engage with on a regular basis across many collections.
WGBH
By Rebecca Fraimow
I’m the digital ingest manager for the Media Library and Archives within WGBH, Boston’s public television station. As an archivist embedded within a production organization, I’m often making decisions based on significantly different factors than the ones that impact my colleagues at more traditional institutions.
The WGBH Media Library and Archives (MLA) collects production masters, original media, and supporting and ancillary assets created on behalf of WGBH (including raw footage, original photographs, and promotional materials), as well as other materials deemed valuable by departments on a case-by-case basis.[23] Over the past ten years, original media materials delivered to the archives have shifted from almost entirely analog to almost entirely born-digital; within the past two years, the same has become true of finalized master programs as well. The vast majority of this material is audiovisual.
One of the key factors that distinguish our use case at WGBH is that the producers who provide the bulk of the MLA’s assets are also the primary stakeholders in the archive. The production departments generally want to receive their original materials back exactly as they delivered them to the archive — same format, same folder structure — so that they know exactly how to find what they’re looking for, and can drop the footage back into their existing project files for video editing. (Relatedly, productions generally want us to store Avid and Adobe project files and other edit materials as well, even though this isn’t officially a part of the MLA’s mandate.) Practically speaking, this means that an archival policy of normalizing everything and then storing only the normalized files is out of the question.
However, the archive also serves the needs of other users, including producers and editors from other internal departments who want to reuse WGBH-owned footage rather than pay for external stock footage and external producers who pay for the rights to use WGBH’s original footage and interviews. Many of the materials created by WGBH also have long-term historical value, including the full programs and raw interviews around topics of public interest, and unedited footage of significant places, persons and events. When possible, this material is made available for free in low-quality proxy formats through the MLA’s Open Vault website[24] and/or contributed to the American Archive of Public Broadcasting=[25] (a collaboration between WGBH and the Library of Congress.) Researchers and other non-production viewers generally do not require high-quality production formats, but the access formats that will be most valuable for them are likely to change with technological shifts.
To meet all these use cases, in an ideal world we’d like to have the camera original, a reliable preservation master, and a contemporary access format for all of our masters and raw production footage. However, as the rate and digital footprint of production increases every year, we currently don’t have the resources to keep up with that amount of processing and transcoding. Since we began our current digital preservation program on LTO tape in 2015, we’ve generated 1.3 PB of unique materials (2.6 PB when including redundant duplication on offsite LTOs); our rate of growth is approximately 500 TB/year and increasing rapidly as more productions shift from HD to 4K.
Storage is, of course, a consideration, but the bigger limiting factor is time — not just human time, but also processing time on a relatively small number of computer stations and LTO decks. Right now, we have only four LTO computer stations and two staff members who work on digital preservation part-time.
Running material through our standard ingest process generally takes about 24 hours of machine time (on one computer) per TB. Batch transcoding the same amount of material can take 48 hours or more, especially if the transcode is processing-intensive, as lossless transcode generally is. While some of these operations can happen simultaneously, attempting to do too many at once risks overloading the machines and losing hours or days of work in the process.
The bright side is that (when everything’s running correctly), this work takes a relative minimum of human time — maybe an hour for setup, and 2-3 hours for post-processing and ingesting metadata into institutional databases. However, individualized assessments of each delivery for problematic file formats increase that time exponentially, so for the most part we don’t do them. We’re racing so fast to make sure everything is backed up for our users that we just don’t have time to tackle much extensive curation the way we would if our use case focused more on the historical record, and less on reuse for production.
Case studies
I’ve talked a lot about our standard workflow, and — unlike my colleagues at UNC and the Library of Congress– we do follow a pretty standard (albeit constantly evolving) workflow for handling born-digital video most of the time. That said, every rule has its exceptions, so first I’ll discuss what we do with most of our regular production drives, and then a project that we did develop a specialized workflow for.
Everything and the kitchen sink
A sample 2TB production hard drive we recently ingested included MP3 files from audio-only interviews; AVdn animation files in a Quicktime wrapper;[26] uncompressed PCM audio narration files in a .wav wrapper;[27] raw camera original footage in a couple flavors of MPEG-2V codecs, wrapped in QuickTime or MXF, depending on camera of origin; a number of .jpg still images;[28] and stock footage in a variety of common formats such as h.264 and .avi. As per our standard practice, we used our standard preservation script to back up all content onto two preservation LTO tapes. This Ruby script uses standard file utilities to copy the files over to two locations and compare them on the the bit level; the Sophos command line tool to run a virus check; and Harvard’s File Information Tool Set (FITS)[29] to document technical and preservation metadata, including MD5 checksums. The script creates a virus scan report and text reports verifying the bit-level comparison for each file tested, as well as a detailed report on the codec and wrapper of each individual file. It’s open-source and can be viewed on GitHub here.
We then created low-res h.264 viewing proxies for all video and .mp3 proxies for all audio. This might not have been necessary for the audio interviews, which were already in .mp3 formats, and for some of the stock footage, but it’s easier to run a batch script on the whole drive than try to sort out what does and doesn’t need to be transcoded. Our batch script for creating video proxies uses bash scripting to call up an
FFmpeg command similar to the ones my colleagues have quoted above; it’s available on GitHub here, and the batch script for audio proxies is available here. The proxies can be viewed by internal producers in our local Filemaker database to help them better determine what they might want to use in a production. We’ll also store the original drive, and until it dies we’ll use that as the primary means of return to the original production if they want access to their materials.
A number of the formats that were delivered on this drive are proprietary, and as time goes on it may become increasingly challenging to play them back. However, right now we don’t have the human time to determine what would be the best preservation formats for all these different kinds of files, and we also don’t have the computing time or storage space to transcode everything to a standard lossless preservation format, so we’re putting off the decision until we run into a use case that requires transcoding these materials further.
Quality and quantity
For a recent high-profile documentary, one of our production units recorded a large number of interviews which were delivered to the archive on 49 LTO tapes — over 100 TB of footage. Because of the size of this delivery, and because it was already on LTO tape, we simply copied each of these tapes over to a backup LTO tape using our standard preservation ruby script and stored both tapes, one onsite and one offsite. We didn’t create viewing proxies for this material at the time of ingest; the time it would have taken to copy each of these files off of LTO, create proxies, and then copy back to a second LTO would have significantly delayed a project that was already set to take approximately 100 days of machine time. This choice was also made in part because many of these interviews were sensitive and unlikely to be available for access in the near future by anyone outside of the original production unit.
However, although the files in this collection are extremely large, there actually aren’t all that manyof them — on average, 4-5 files per LTO tape — and they all share the same technical characteristics (AVdh, 8-bit, 4K, in a Quicktime wrapper.)[30] When we migrate our LTO-6 tapes forward to LTO-8, we also plan to replicate our footage onto a local server which has more transcoding capabilities than our in-house computers. At that time, not only will we be able to create access copies, but this collection will be a good candidate for a batch migration to a more stable and less proprietary format, since we only have to analyze one type of file and we expect that this material will provide significant value to the historical record in the long term.
Conclusion
While each of our institutions has unique characteristics that have led to different decisions, across the board we have found that enforcement of a strict born-digital audiovisual file format policy is unrealistic. This is not just due to the aforementioned lack of consensus around preservation file format targets, but also a result of the complexity and variation in original file formats received; under current conditions in the field, one size just doesn’t fit all.
As you can see in our text, a file’s technical specifications can include not only the extension, but also its codec, resolution, and many other significant characteristics that one would want to maintain across file migrations — information that often can only be fully determined with knowledge and tools that may not be available to all stakeholders. Determining and researching a file’s characteristics is a time consuming prerequisite to migrating, and as our use cases demonstrate, practitioners need to make judgment calls about when the effort is worth the time. Additionally, more than one of us has noted that our policies and workflows are provisional and are apt to change yet again in the near future due to continuing shifts in audiovisual production and preservation.
In other words, this is both a technical issue and a much larger issue involving the administration of limited resources.
While these issues have no easy solutions, an important first step is for institution must develop transparent policies and workflows addressing interim steps and potential file migration workflows. These policies, shared among practitioners, can help the field as a whole work towards developing programmatic solutions that can better address the diversity of born-digital specifications.
Our use cases document difficult compromises that are realistic and part of our actual day to day practices, not our much rarer examples of especially laudatory practices done when resources are unconstrained and there’s a clear and documented path for managing what is in front of us. These use cases were chosen because they have ambiguous answers that, in almost all cases, are only provisional and will need to be revisited by future processors. In each case, we’ve had to make policy priorities and treat collections differently based on its content, its stakeholders, and its future potential uses. However, across the board, we have all made sure to assess the risks against our own capacity and make sure we’re preserving the characteristics that are most significant to our users — even though those characteristics are different for each of us.
Through the course of our research and work, all of us have explored other potential options and made adjustments. In sharing our workflows with one another, all of us have amended policies. Over this period of time, conversation in the field has also gradually begun to turn towards the development of more format-specific recommendations and best practices. Recently, Crystal Sanchez and Taylor McBride, Video Specialists at the Smithsonian Institute launched a shared Google document for practitioners to aggregate information and develop best practices around the preservation of camera original formats currently in use in the field. The lack of transparency around the multitude of proprietary camera original formats in use will otherwise continue to be a major stumbling block for digital preservation.
Another encouraging development is the work initiated by the FADGI Audio-Visual Working Group to define and address what audiovisual “significant properties” are exactly. These two developments will help the audiovisual field answer still unresolved questions important to understanding seemingly basic questions such what is a file’s characteristics and whether or not we need to preserve them. We’re optimistic that research into format-specific practices will allow for the development of improved policies that reflect the complexity of born-digital audiovisual media, as well as the development of tools that can actually make programmatic decisions based on those salient file characteristics.[31]
While ‘best practices’ may become more attainable over time, our hope from exploring our own institutions here is to encourage a frank discussion of the cost-benefit analysis that goes into developing workflows for these materials, helping to demystify the decision-making process around digital video and encouraging institutions to take their first steps towards developing ‘good enough’ practices that are right for them.
About the Authors
Rebecca Fraimow is the Digital Ingest Manager at the WGBH Media Library and Archives and the American Archive of Public Broadcasting, where she oversees digital archiving workflows and the development of the PBCore metadata standard. Rebecca was a founding member of New York City’s XFR Collective, a nonprofit organization focused on the preservation of at-risk media, and previously managed the Dance Heritage Coalition NYC Digitization Hub before joining WGBH as part of the National Digital Stewardship Residency program.
rebecca_fraimow@wgbh.org, @rhfraim
Julia Kim is the Digital Assets Specialist at the American Folklife Center at the Library of Congress. She manages the division’s born-digital and digitized assets, workflows, and systems. She has published and presented on audiovisual workflows, digital forensics and emulation use cases, researcher access to born-digital collections, and at-scale digital access workflows. She is active with the Society for American Archivists, the Association for Moving Image Archivists, and the International Conference on Digital Preservation. She helped cofound the XFR Collective, and is a New York National Digital Stewardship Program alumna.
Erica Titkemeyer is the co-Principal Investigator and Project Director on an Andrew W. Mellon Foundation grant titled Extending the Reach of Southern Audiovisual Sources: Expansion. In this role, they coordinate digitization of audiovisual materials from Wilson Library Special Collections at UNC, as well as collections held by institutional partners across the state. They also support digital preservation policy development as a member of the UNC Libraries’ Digital Preservation Stewardship Committee, while providing guidance on born-digital processing of audiovisual files in the Southern Folklife Collection.
etitkem@email.unc.edu, @ekemeyer
Acknowledgments
The authors would like to thank members of the audiovisual and digital preservation community for their positive feedback and encouragement. Of special note are the contributors to FFimproviser, a community supported audiovisual resource mentioned throughout this paper. While there are too many contributors to acknowledge individually, we would like to especially thank Dave Rice and Ashley Blewer. We would also like to thank our audiovisual colleagues Kate Murray and Crystal Sanchez for their invaluable feedback. Finally, we’d like to thank Shira Peltzman and Karen Cariani for moderating panels on this topic, as well as the Association of Moving Image Archivists and iPRES for providing us the opportunity to discuss these challenges at their annual meetings.
[1] Federal Agencies Digital Initiatives, “Creating and Archiving born-digital Video,” Available from: http://www.digitizationguidelines.gov/guidelines/video_bornDigital.html?loclr=blogsig
[2] JPEG 2000 Part 1, Core Coding System [internet]. Library of Congress; [cite 2019 Jan 9]. Available from: https://www.loc.gov/preservation/digital/formats/fdd/fdd000138.shtml.
[3] FF Video Codec 1 [internet]. Library of Congress; [cite 2019 Jan 9]. Available from: https://www.loc.gov/preservation/digital/formats/fdd/fdd000341.shtml.
[4] For more discussion of the pros and cons of various preservation file formats, see Peter Bubestinger, Hermann Lewetz and Marion Jaks’ “Comparing Video Codecs and Containers for Archives,” Indiana University’s white paper “Encoding and Wrapper Decisions and Implementation for Video Preservation Master Files,” and Emmanuel Lorrain’s “A short guide to choosing a digital format for video archiving masters.”
[5] Fraimow F, Kim J, and E Titkemeyer, Never Best Practices: Born-Digital Audiovisual Case Studies from Production, University, and Federal Government Environments, discussion panel at the International Digital Preservation Conference, Boston,September 26, 2018. Portions of this resulting paper were discussedin this panel.
[6] Carolina Digital Repository: https://cdr.lib.unc.edu/
[7] Apple Prores 422 Codec Family [internet]. Library of Congress; [cite 2019 Jan 9]. Available from: https://www.loc.gov/preservation/digital/formats/fdd/fdd000389.shtml.
[8] Matroska Multimedia Container [internet]. Library of Congress; [cite 2019 Jan 9]. Available from: https://www.loc.gov/preservation/digital/formats/fdd/fdd000342.shtml.
[9] MPEG-4, Advanced Video Coding (Part 10) (H.264) [internet]. Wikipedia; [cite 2019 Jan 9]. Available from: https://www.loc.gov/preservation/digital/formats/fdd/fdd000081.shtml.
[10] FFmpeg, “H.264 Video Encoding Guide”, available from: https://trac.ffmpeg.org/wiki/Encode/H.264.
[11] FFmpeg is a “leading multimedia framework, able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created.” Documentation and more information is available from: https://www.ffmpeg.org/.
[12] Ffmprovisr, “Extract audio fran and AV file”, available from:
[13] DROID “is a file format identification tool, which can process single or batched digital objects to determine their file type, size, age, and change history. DROID can currently identify over 250 file formats, with more formats being added regularly.” More information is available from: http://www.dcc.ac.uk/resources/external/droid.
[14] “Brunnhilde was written to supplement existing file format identification and characterization tools, with a focus on producing human-readable high-level reports for digital archives and digital preservation practitioners.” More information is available from: https://www.bitarchivist.net/projects/brunnhilde/.
[15] Library of Congress Fiscal 2018 Budget Justification: Submitted for the Use of the Committees of the Appropriations [Internet].[2017]. The Library of Congress/ [cited 2018 Dec 4]. Available from: https://www.loc.gov/about/reports-and-budgets/congressional-budget-justifications/, p.118.
[16]For more information on AFC’s digital preservation workflows, systems, and environments, see The Library of Congress, “The Signal [Internet].[2016]. “Minimal Digital Processing at the American Folklife Center” Available from: https://blogs.loc.gov/thesignal/2016/06/the-workflow-of-the-american-folklife-center-digital-collections/
and The Library of Congress, “The Signal [Internet]. [2018]. “The Workflows of the American Folklife Center.” Available from: https://blogs.loc.gov/thesignal/2016/06/the-workflow-of-the-american-folklife-center-digital-collections/.
[17] My approach is inspired and amended from Waugh D, Russey Roke E, Farr E (2016) Flexible processing and diverse collections: a tiered approach to delivering born-digital archives, Archives and Records [Internet] [cited 2018 Dec 4]; 37:1, 3-19. Available from: 10.1080/23257962.2016.1139493
https://www.tandfonline.com/doi/abs/10.1080/23257962.2016.1139493
[18] For some background on the term “fugitive media” and its use in archives, see Forstrom, M. “Managing Electronic Records in Manuscript Collections: A Case Study from the Beinecke Rare Book and Manuscript Library,” American Archivist, vol. 72 (Fall/Winter 2009), pp. 460–77. https://www.jstor.org/stable/27802697
[19] This project was presented earlier this year by Kim J, “Time to clean out our closet: challenges accessioning fugitive media” BitCurator User Forum, September 2018.
[20] Video CD [internet]. Wikipedia; [cite 2018 Dec 4]. Available from:https://en.wikipedia.org/wiki/Video_CD
[21] Interlaced Video [Internet]. [updated 2018]. Wikipedia. Available from: https://en.wikipedia.org/wiki/Interlaced_video
[22] While streaming moving image access targets are, in contrast, relatively stable, even in this case we had to transcode multiple times to meet the constraints of our streaming services. The anomalies meant that, for the first time, we had to ultimately outsource our derivative creation to meet our publication time frame.
[23] “What We Do” [internet]. WGBH; [cite 2018 Dec 7]. Available from https://www.wgbh.org/foundation/what-we-do/media-library-and-archives
[24] WGBH Open Vault [Internet]. WGBH Media Library and Archives; [cite 2018 December 7]. Available from http://openvault.wgbh.org/
[25] American Archive of Public Broadcasting [Internet]; [cite 2018 December 7]. Available from http://americanarchive.org/
[26] AVdn is a proprietary Avid flavor of QuickTime. WGBH primarily uses Avid editing software, so many of our materials come to us as Avid proprietary codecs. More information about these codecs is available at the Avid Knowledge Base: http://avid.force.com/pkb/articles/en_US/Download/en392959
[27] PCM, Pulse Code Modulated Audio [internet]. Library of Congress; [cite 2019 Jan 9]. Available from https://www.loc.gov/preservation/digital/formats/fdd/fdd000016.shtml
[28] JPEG Image Encoding Family [internet]. Library of Congress; [cite 2019 Jan 9]. Available from https://www.loc.gov/preservation/digital/formats/fdd/fdd000017.shtml
[29] FITS wraps together several file characterization tools, including DROID, ExifTool, and MediaInfo, and generates a standard output that includes all generated technical metadata. More information is available here: https://projects.iq.harvard.edu/fits/home
[30] Another flavor of proprietary Avid codec.
[31] The working document is available at https://docs.google.com/spreadsheets/d/1OvZkGkizNnx_nZ9OVDOkJJIVFuIMK_7FYKC77YhoUac/edit?usp=sharing

Subscribe to comments: For this article | For all articles
Leave a Reply