by Janina Mueller
Introduction
As a result of a collaboration between the library, instructional technology, the IT department and the software company Instructure, the Graduate School of Design (GSD) at Harvard University successfully designed and implemented a school-wide software tool that allows for the systematic collecting of student assignments from courses, embedded in Harvard’s chosen enterprise Learning Management System, ‘Canvas’ by Instructure. For the first time in the history of the GSD, a school-wide system is now in place that allows the library to build an archival collection of digital student work. The collected student works and their metadata are used by various departments within the GSD for a range of activities such as exhibitions, publications, marketing of academic programs, the accreditation of academic programs and for archival purposes. This paper outlines the history of student work collecting at the GSD, and the processes that led to the successful implementation of the tool we call the “Student Work Harvester” (SWH). The goal of the new collection process was to develop a simple, intuitive and flexible tool that facilitates the selecting and gathering of student work, and allows for the creation of a centralized depository of student work that is searchable and archived long-term.
Context and History of Student Work at the Frances Loeb Library
When the Harvard Graduate School of Design (GSD) was founded in 1936, it brought together Harvard’s departments of architecture, landscape architecture and urban planning into one graduate school. The GSD’s Frances Loeb Library has samples of student work going back to the 1920s. However, student work had been collected in a haphazard and uncoordinated way throughout the decades. Thus, the collection of student work is inconsistent in content and format.[1]
Until 2013, the Frances Loeb Library at the GSD had a passive role in the collecting of student work. Academic departments that needed student work for various purposes, including for publications, accreditation and promotion, collected the files themselves. Often times this meant that administrative staff and faculty had to contact students who graduated several years prior and ask for examples of their course work. Since there was no or little coordination, students were often contacted multiple times by different people at the GSD. Recognizing the redundancy caused by decentralized and uncoordinated processes, the Library proposed to manage the process of collecting student work at the GSD.
As Harvard began rolling out a new Learning Management System (LMS) in 2015, the Library and the Instructional Technology department decided to explore the feasibility of using course websites as a way to gather student files, reasoning that collecting items and metadata as closely as possible to the source, and requiring no extra work on the students’ part, was the most efficient. By working with different stakeholders both inside and outside of the Library, we worked with the software company Instructure and designed a Learning Tools Interoperability (LTI) plug-in tool within the Canvas LMS.[2] Our new tool allows us to collect all student work submitted as course assignments, or subset collections based on specific metadata criteria. Instructure developed this customized, proprietary solution for us; regrettably, it is not open source and we are not able to share the tool.
Functionality of the Student Work Harvester
The Student Work Harvester (SWH) allows GSD instructors to identify student submissions that meet certain criteria and tag them so they can be made available as needed for inclusion in exhibitions, publications, accreditation or open house presentations. Once work projects have been identified and tagged by instructors, Canvas administrators are then able to search for student work that matches their search criteria and export it to a cloud-based storage location.
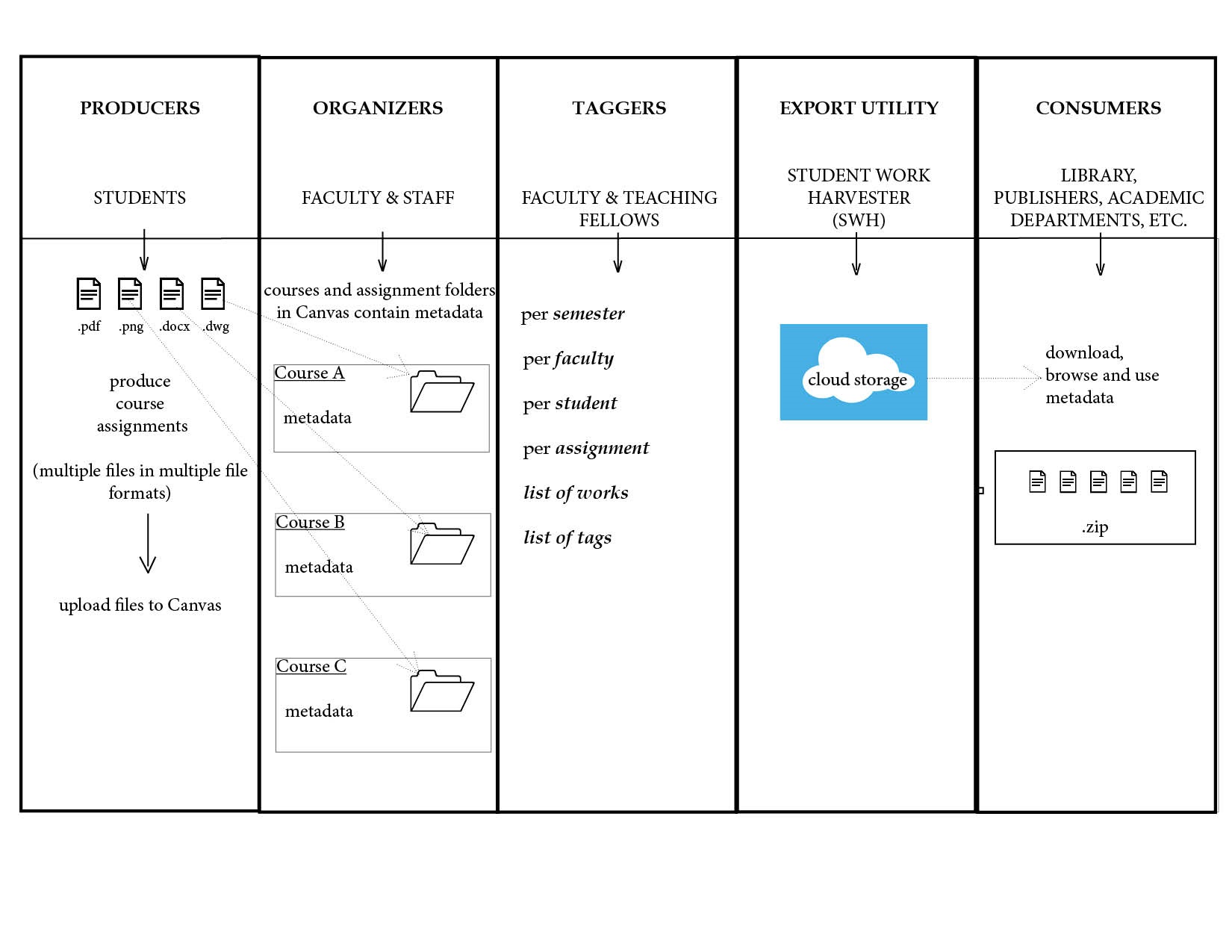
Figure 1. Workflow diagram.
The Student Work Harvester has the following two interfaces: A tagging or selecting interface, and an export interface. The tagging interface is accessible only to teaching faculty and teaching fellows (TFs) of a course. In this interface, student files can be nominated by assigning tags to assignment documents.
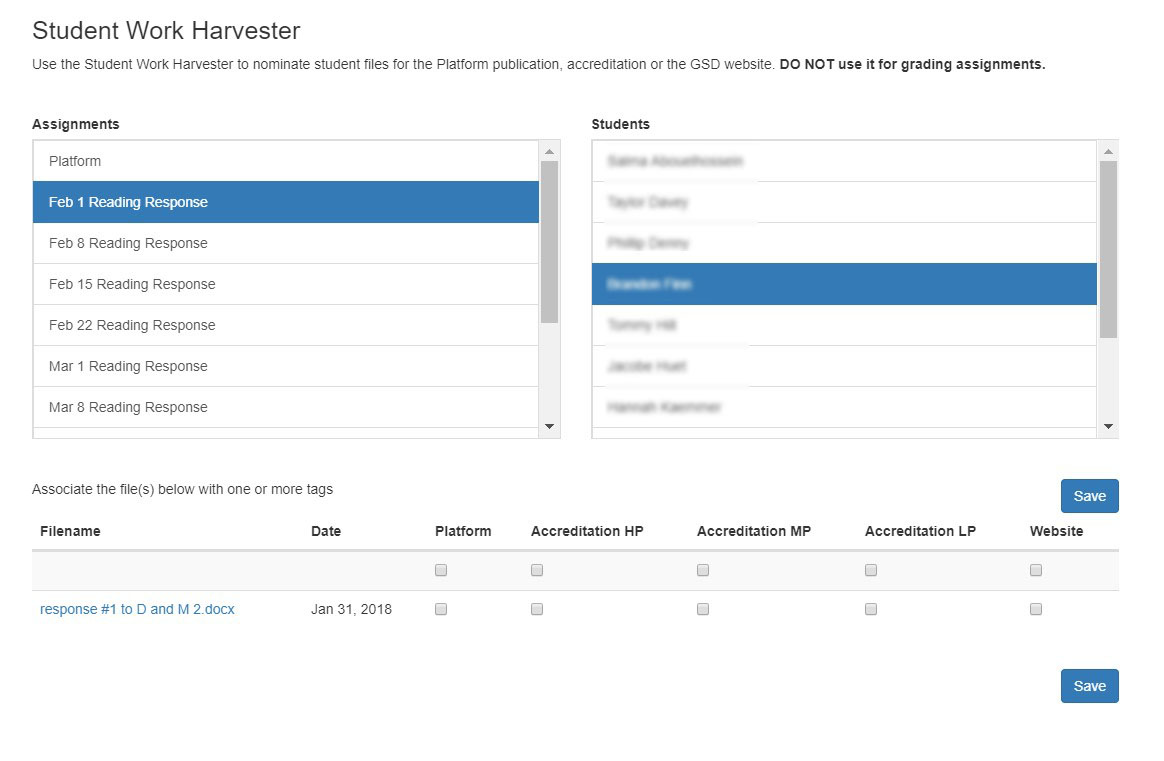
Figure 2. Student Work Harvester tagging and selecting interface.
In the tagging interface, for any course, an instructor selects an assignment on the left-hand side of the screen from the assignments entered in Canvas and displayed on the course website. This action populates to the right a list of students who have submitted at least one file against the assignment. The instructor then selects a student’s name. By clicking on the name, a table below populates with all the files the student submitted for that assignment. The instructor then checks a box according to which tags should be associated with the file. This is the way that student work is selected and tagged, for each course, for each assignment, for each student.
The SWH lists student file uploads that are submitted as “assignments” within Canvas. To be specific, student submissions must be a “file upload” submissions type as other types (such as “text entry”, “website URL” or “media recording”) are not recognized formats for the SWH.
The export interface is accessible to the library staff and a selection of GSD administrative staff who have ‘Administrator’ roles in Canvas. This interface allows administrators to search for student work and export it to a cloud-based storage system, which, in our instance, is an Amazon S3.
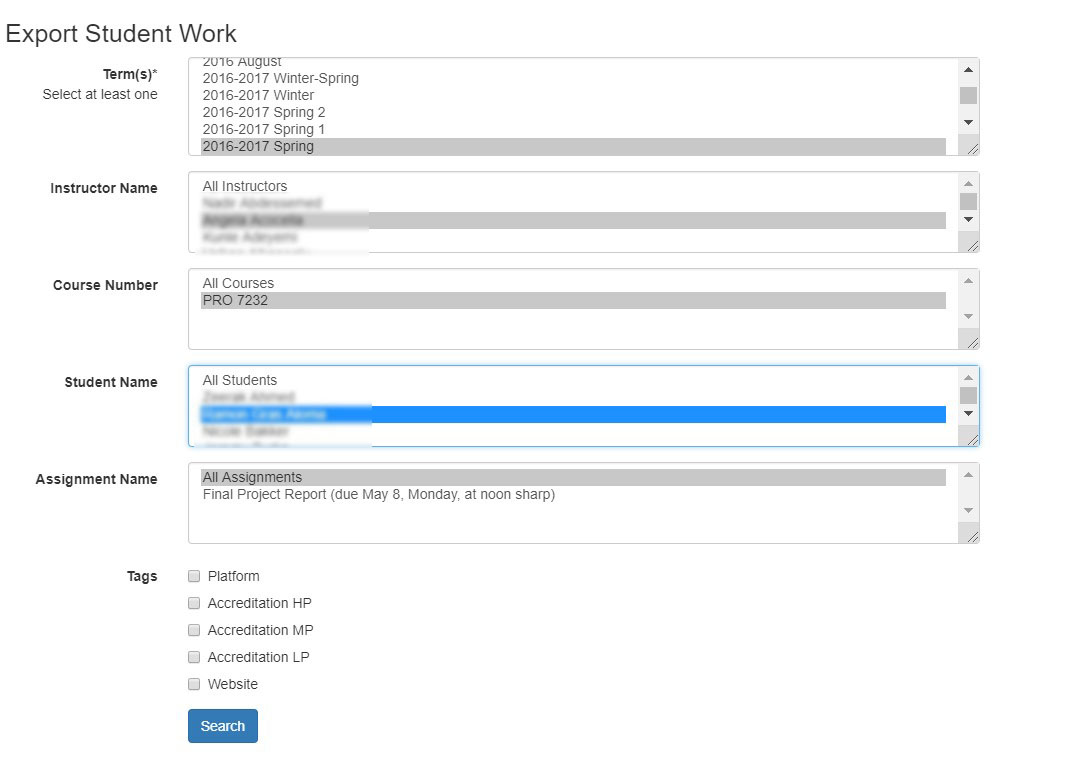
Figure 3. Export interface.
The Export View has a sequential selection process and works in the following manner: One or more terms can be selected in the Term(s) field, after which all people enrolled as “teachers” in any of the courses from those terms are listed in the Instructure Name field. The Export View allows you to select all or specific instructors, after which the Course Number field is populated. Courses that the specified instructors taught in that term are listed. The Student Name and Assignment Name fields work in the same manner; the list of student names is determined by the selection made for the previous field, and either all or a selection of students can be selected. The same goes for the Assignment Name field. Finally, the user of the Export view has the option to export all files or only files marked with specific tags for specific purposes.
When an export starts to run, the SWH selects the indicated student files together with relevant student and course information from Canvas. Those files are placed in a temporary, cloud-based application platform, in our case Heroku. Once the processing is complete on Heroku, the final export, in the form of a zipped folder, is placed on the Amazon S3. When the processing is complete, an email notification with a link to that zipped file is sent to the person who ran the export in the Student Work Harvester.
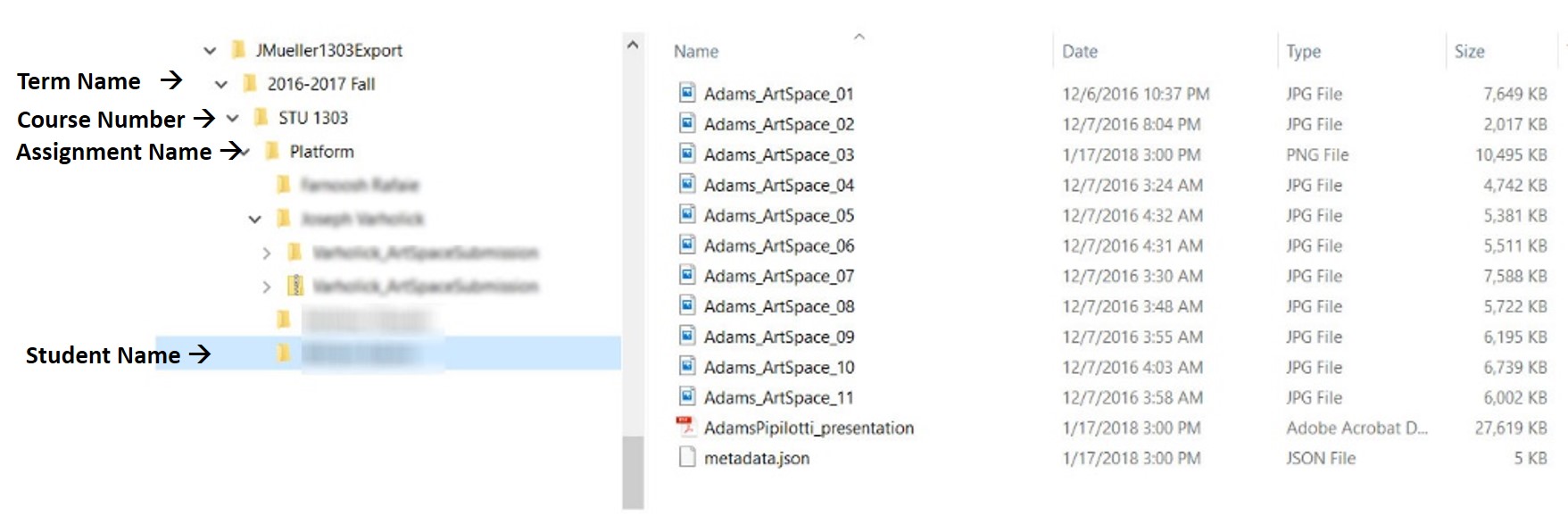
Figure 4. File hierarchy example.
The top-level folder can be named by the exporter when running the export; its default name is the timestamp of when the export was created. Within that folder are the following hierarchical folders: Term Name > Course Number > Assignment Name > Student Name. Student work files are stored in the lowest folder (Student Name). The names of the files are the original filename from Canvas. Additionally, a JSON metadata file is generated and stored in each folder. The JSON file in the top-level folder contains a hierarchical representation of all data in the entire export. Going one level down, JSON files within a subfolder contain metadata from the export scoped to that particular term [see Figure 5]. The information for the metadata fields is pulled from the course information on Canvas.
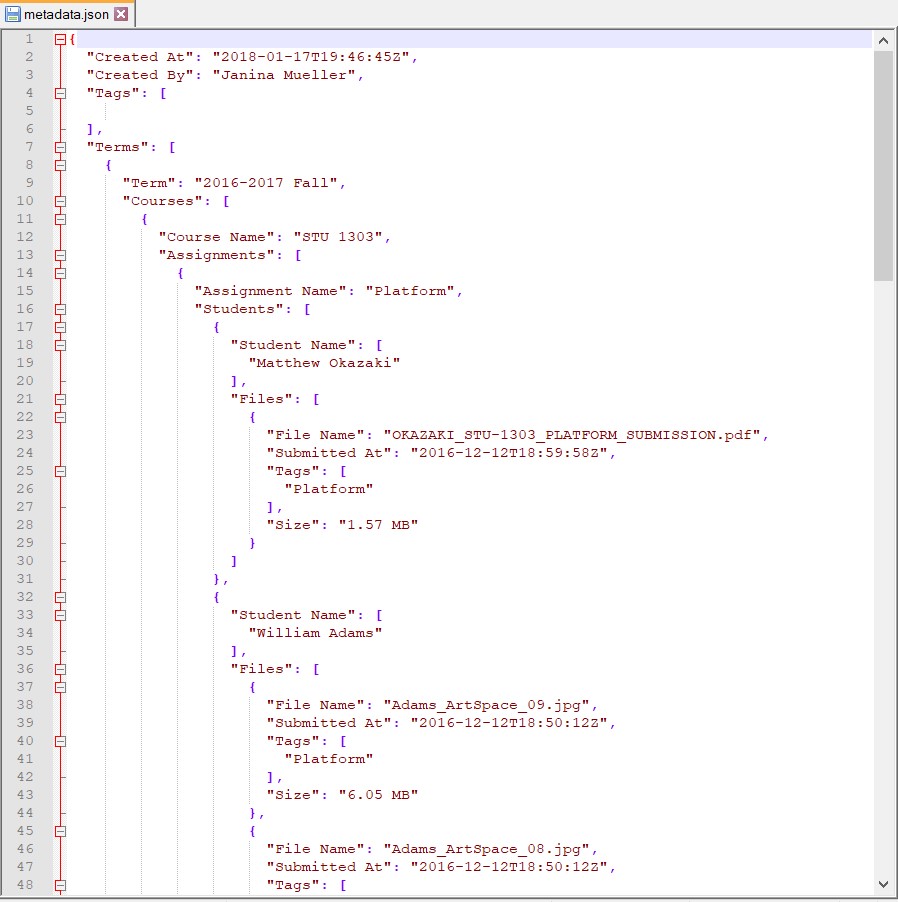
Figure 5. JSON metadata example.
Customization
Several parameters controlling SWH’s functionality are customizable, including a) the tags that can be assigned to student files, and b) the server destination where the exports are placed. The tags are customizable in the export interface by administrators of the SWH. The tags currently used were agreed upon by the academic departments and they reflect their needs for the use of student work. The tags label student work to be used for accreditation, in publications and the school’s outward-facing website. Additionally, the final destination of the file exports, which currently is set to an AWS S3 instance, is customizable. The export specifications are flexible enough to export to other endpoints.
Challenges
Even though we wanted our LTI tool to be open source, we ultimately did not have a choice in this matter. Because our LTI tool is based on Instructure’s Canvas platform, working with Instructure in creating this tool was the most efficient and cost-effective approach in the long run. Canvas is not an open source platform, and the code for the SWH was not shared with us either. This, in addition to the fact that an LTI tool is inherently based on the functionality of the original platform (in this case Canvas) can pose limits the tool. For example, the SWH is based on roles and permissions of the GSD’s Canvas instance; these, in turn, are in tune with other systems that are used at Harvard, including the Student Information System. Changes that are made to any of those systems can affect the functionality of the SWH. Many times we are not informed about changes that could affect the SWH and accidentally find out about broken features of the tool. Due to the fact that the SWH is not open source, debugging is dependent on developers and scheduling priorities from Instructure. Additionally, because the SWH is a customized LTI tool, reporting a bug to Instructure often requires us to repeatedly explain the SWH’s functionality and purpose to Instructure’s employees. This probably has to do with the fact that the SWH is not a core functionality of Canvas and consequently, customer support staff and developers at Instructure are unfamiliar with it.
Implementation: The Need for Cultural Change
The implementation of the SWH in the GSD’s Canvas instance took place at the beginning of December 2015. Getting teaching faculty to use a new tool, including a new LMS, can be very challenging.[3] People get used to a system and its interfaces, and are often not interested in learning a new tool. Faculty members generally care much less about the technical platform of their course websites than the content they teach. In other words, their priorities do not lie in spending the time to learn a new system.
In order to minimize some of the frustrations that come with the implementation of new courseware and a new LTI tool, we worked with the administrative staff of the departments to encourage and support the use of the SWH. We also presented the tool in faculty and departmental meetings and offered faculty individual assistance if needed.
One of the biggest takeaways from the implementation process of both Canvas and the SWH is that getting users to accept a new workflow and system takes time; faculty needed time to learn and understand the new platform, as well as gain an understanding of our intentions behind them using the SWH tool. Today, Canvas is an integral part of any GSD course, and faculty are aware that part of their responsibility is to nominate student work at the end of their courses by means of the SWH. Additionally, the benefit of the SWH for administrative staff and publication editors has led them to promote the tool to faculty as well.
Other Major Advantages
One of the biggest advantages of collecting student work through the SWH is that we can run very large exports, well above 100GB. This is a major advantage as it allows us to export not only a selection of files but potentially all files submitted to a Canvas course. In our current environment of ubiquitous digital files – particularly pronounced in fields such as architecture, landscape architecture and urban planning – student assignment submissions are often made up of a number of files in different formats and sizes, and image files can be very large! Our Canvas assignment batch export mechanism accommodates these file size and format conditions.
By using existing permission roles within Canvas, we were able to have access controls to both the tagging and export interfaces. This was important, as we wanted to make sure that only teaching faculty and fellows – and not the students themselves – were able to assign tags to student files and that only administrators can trigger exports of files.
Future: What lies Ahead
Now that we have a robust collection platform and workflow in place, we plan to work with a digital archivist in developing a workflow for the long-term archiving of the student files in Harvard’s digital repository. Our goal is to record the history of the creative output of the GSD and to archive a selection of student work files for perpetuity. Challenges we have encountered thus far include the fact that Harvard’s current digital repository only accepts a limited number of file formats. As noted previously, one of the advantages of our Canvas LTI collection tool is that it can accept any file format. Thus, we need to find a way to archive all of the relevant files in their various file formats.
Moreover, we need to work on mapping our metadata JSON file to existing metadata schemas that are used for files in the digital repository. Connected yet separate from that issue are questions of access to the archived files and their metadata: When, who and how should access to student files be granted? In other words, in the future we will have to work on higher level issues such as the scope of the long-term archival collection, access and discovery policies and technologies, as well as technical issues of metadata crosswalks and file formats.
Conclusion and Summary
The development process for our customized LTI plug-in tool followed a typical software development cycle; however, it was constrained by proprietary software. The effort for developing this tool was well worth it for the entire Graduate School of Design, as it has centralized workflows and thus eliminated redundancies. Moreover, we have witnessed a change in the expectations and interest of students and faculty in the area of data management and archiving. Ideally, in the future, we hope to do more enhancements to the SWH, including adding additional content metadata that describes the geographic location and type of problem for each assignment.
To sum up, for the first time in the history of the GSD, a school-wide system – the Student Work Harvester – is now in place that allows the library to build an archival collection of digital student work. The collected student work and their metadata are used by various departments within the GSD for a range of activities such as exhibitions, publications, marketing of academic programs, the accreditation of academic programs, and for archival purposes. This paper outlined the history of student work collecting at the GSD, and the processes that led to the successful implementation of the SHW tool within Harvard’s enterprise Learning Management System, Canvas. The goal of the new collection process was to develop a simple, intuitive and flexible tool that facilitates the gathering and selecting of student work, and allows for the creation of a centralized depository of student work that is searchable and archived long-term. So far, that goal has been realized.
References
[1] The GSD’s Frances Loeb Library has a Special Collections that includes a collection of student work in both analog and digital formats. This collection contains files going back to before the founding of the GSD, when the three disciplines were housed in different buildings. The earliest student work examples are student prize-winning projects from the 1920s. The Library also holds a representative sample of student assignments from the 1940s and 1960s. In the 1980s, the GSD started to publish yearly print publications with examples of work students produced at the school. The Library holds copies of these publications, as well as some digital files of the student work displayed in them.
[2] The stakeholders included: a) GSD’s Computer Resources Group; b) Harvard’s Teaching, Learning, Technology (TLT)-group, which managed the university-wide Canvas roll-out; and c) Instructure, the software company owning Canvas.
[3] Conrad, Suzanna (2018). Spinning Communication to Get People Excited About Technological Change. Code4Lib Journal, (41). https://journal.code4lib.org/articles/13641.
About the author:
Janina Mueller (mueller.janina@gmail.com) has been working at the Harvard Graduate School of Design (GSD) since 2013. She worked as the Design Data Librarian from 2013-2015, and has since then worked as the GIS & Data Librarian. As the Design Data Librarian, she spearheaded a new, digital collection of student work, which centralized a number of disparate collection and work processes. She describes the design and implementation of this project in this article. Today, Mueller works as the GIS and Data Librarian at the GSD.

Subscribe to comments: For this article | For all articles
Leave a Reply