by Kelli Babcock, Sunny Lee, Jana Rajakumar, Andy Wagner
Introduction
The University of Toronto Libraries (UTL) system consists of over 40 libraries located on three university campuses. It serves over 14,000 faculty members and more than 90,000 undergraduate and graduate students [1]. The UTL Information Technology Services (ITS) department provides digital library services to the UTL system, including the Collections U of T service.
Collections U of T provides search and browse access to U of T digital collections. It currently contains 375 digital collections and over 197,000 digital images, and typically includes archives or special collections material from libraries and archives across the library system, as well as digital collections owned by university departments, faculty, or external project partners. Each collection often has unique metadata requirements as well as custom requests for presentation of web content. The Collections U of T service is currently supported by a single static HTML site at the main URL. This static HTML site links out to multiple International Image Interoperability Framework (IIIF) enabled Islandora 7 websites that act as the point of access for each top-level collection in the repository. Digital objects for each collection are stored in a single Fedora repository. Images are served by a Loris IIIF image server that retrieves them from Fedora and provides a caching layer. IIIF manifests are generated through customized Islandora ingest scripts and stored in a MongoDB instance. Like many institutions using Islandora 7, the Collections U of T service is now confronted with Drupal 7 end of life by November 2021. The department has begun to investigate a migration path forward, with research efforts coordinated by Kelli Babcock, Digital Initiatives Librarian.
This article summarises the first phase of our research, including a brief history of Collections U of T, lessons learned from experience with our current technology stack, and our selected path forward after reviewing various technology options. The first phase of our research has included investigating both out-of-the-box platforms and emerging “pluggable” technology solutions for digital collections. Note that our research is focused on reviewing technology solutions for providing access to digital collections, and not preservation. We have decoupled the long-term preservation of our digital objects from their discovery and access with the launch of Project Canopus, a preservation focused digital repository at the University of Toronto Libraries.
Where We Started: Our Initial Context
Collections U of T began as an initiative to create a web portal to support the discovery of multiple U of T digital collections. In 2013, the Collections U of T web portal was created in response to increasing requests from faculty members, external partners, U of T archives and library departments – “collection owners” – for technology support to make their digital collections available online. We refer to “collection owners” throughout this article to identify Collections U of T users that are either the archive or library that cares for the digital collection, or the faculty or department that sponsored the collection’s publication to the web. Collection owners often request similar features for technology support, including: presentation; search; collection theming; the ability to customise metadata per collection; a WYSIWYG editor interface to manage the contextual web content surrounding collection objects; and “preservation” functionality. Within the library, there was also an interest in providing users with the ability to search both across collections and within a specified collection. Prior to 2013, ITS used the ColdFusion programming language to create digital collection websites. [2] Each of these digital collections existed in its own siloed ColdFusion site. The idea, at the time, was to unite the collections through a central access point for users.
A review of proprietary and open source repository platforms was conducted in 2013. Islandora 7 was identified as the best fit for the requirements and context of Collections U of T at the time:
- Islandora 7 could be set up as a multi-site environment: one “parent” site to search across collections with separate “child” sites per collection
- Out of the box, Islandora 7 provided support for MODS and Dublin Core metadata. The use of both standards would meet most descriptive needs of the proposed collections
- Islandora was also flexible enough to accommodate other metadata schemas if needed in the future
- Metadata search and display could be customised through the user interface by collection owners
- Islandora 7 had been, or was being, adopted by many Canadian and international academic libraries. This meant Islandora came along with a strong open source community (with incredibly helpful volunteers, as it turned out)
- UTL ITS already maintained many Drupal websites. Staff in the ITS department had existing expertise in building Drupal sites. The department had also gained experience with Islandora 6 while creating the Heritage U of T site in 2013, [3] a project that preceded and somewhat inspired the Collections U of T portal
- Though ITS had not yet hired a Digital Preservation Librarian at the time of the 2013 platform review, there was some attraction to Islandora because it was thought that Fedora could be a candidate for supporting some of the workflows and infrastructure of future preservation services. Since 2013, other technology solutions were selected to provide preservation services at UTL [4]
After the platform selection, ITS set up an Islandora instance for Collections U of T in 2014 (initially set up as one Fedora 3 with multiple Islandora/Drupal 7 sites). A number of collection owners were eager to get their collections online by joining Collections U of T upon its initial set up. The repository grew quickly. There were many lessons learned following the initial set up. Most importantly, we realized that adjustments to the architecture of our Islandora instance were required to improve internal development workflows for a digital collections portal at this scale. [5]
Next, we created custom ingest scripts combined with mediated ingest – ITS now runs ingest scripts upon request by collection owners, as opposed to collection owners submitting GB of digital object data through their web browsers. This mediated workflow has become common practice because the custom ingest scripts also provide more control over the permanent identifiers (PIDs) assigned to digital objects. For example, it is not possible to control the full PID of digital objects in Islandora 7 if they are ingested through the batch ingest user interface (only the namespace can be assigned, leaving the second half of the PID to be a random number). Our ingest scripts enabled us to create meaningful PIDs – from collection objects down to page-level objects. This meant that we could maintain legacy identifiers for objects migrated from ColdFusion and also ensure each object had a meaningful PID in its corresponding URL. Mediated ingest also meant that developers could resolve any ingest issues more efficiently. Collection owners were, and are still, required to prepare the images and metadata for ingest, but they no longer experience the wait times of ingesting through Islandora’s batch ingest user interface, or the burden of reporting failed ingests for developers to triage and resolve.
We also found that using a CMS like Drupal provided some opportunity to distribute the work of content creation and site maintenance to collection owners, but not in all cases. For many collection owners, there was a big learning curve in navigating Drupal 7, let alone having to learn the search and metadata configuration possibilities in Islandora 7. Initially, frequent training was provided to collection owners alongside detailed documentation for support. Eventually, ITS took on most of this work for the sake of efficient site set up and to ensure search and browse worked well for users. Collection owners now interact with their sites primarily through Drupal WYSIWYG editors to modify page content. Shortly after Collections U of T was created, the Exhibits U of T service was set up in ITS by Digital Scholarship Librarian, Leslie Barnes. Exhibits U of T uses the Omeka platform. Compared to Drupal, Omeka has proved to be a truly DIY solution for enabling collection owners to create and manage their own web content. Generally, Collections U of T (Islandora) is used when search facets and querying metadata are requirements of the collection owner. Exhibits U of T is preferred for simple exhibit building that does not require search features.
In terms of building a parent site to search across collections, usage statistics from Google Analytics revealed that very few users were searching across collections using the Collections U of T “parent” portal site. The parent Collections U of T site was retired in 2017 and replaced with a static HTML site directing to each child collection. In the future, we will instead be focusing on promoting discovery of collections through our library catalog, search engine optimization, and connecting with consortial discovery portals and digital collection aggregators. Collections U of T also evolved from simply being a portal for UTL digital collections to becoming a full service provided by ITS to support the management of U of T digital collections. The service now includes consultations to those interested in creating digital collections, including tools and templates for metadata creation, advice on technology selection, and – when the technology fits the needs of the project – development support for setting up and configuring a Collections U of T site for collections owners.
From 2015 to 2016, IIIF was integrated into our Islandora instance while collaborating on the French Renaissance Paleography project. [6] During this project we also implemented Mirador [7] as a viewer for Islandora Book and Page objects. Eventually, IIIF became seamless with our Collections U of T ingest workflows – all image objects and collections in the repository came to have a IIIF manifest. The Islandora Mirador viewer and IIIF manifest generation functionalities are implemented as a custom module called Islandora Mirador. Manifests can be generated and posted to MongoDB (part of the IIIF Presentation API) via a “Generate IIIF manifest” button in the Islandora user interface when “managing” an object, or through command-line interface (CLI) using a custom Drush (Drupal shell scripts) command. We create collection-level IIIF manifests per collection and also keep a top-level Collections U of T collection manifest containing all collections and objects. [8] As described in Figure 1, IIIF is now core to the Collections U of T service to enable the delivery of digital objects.
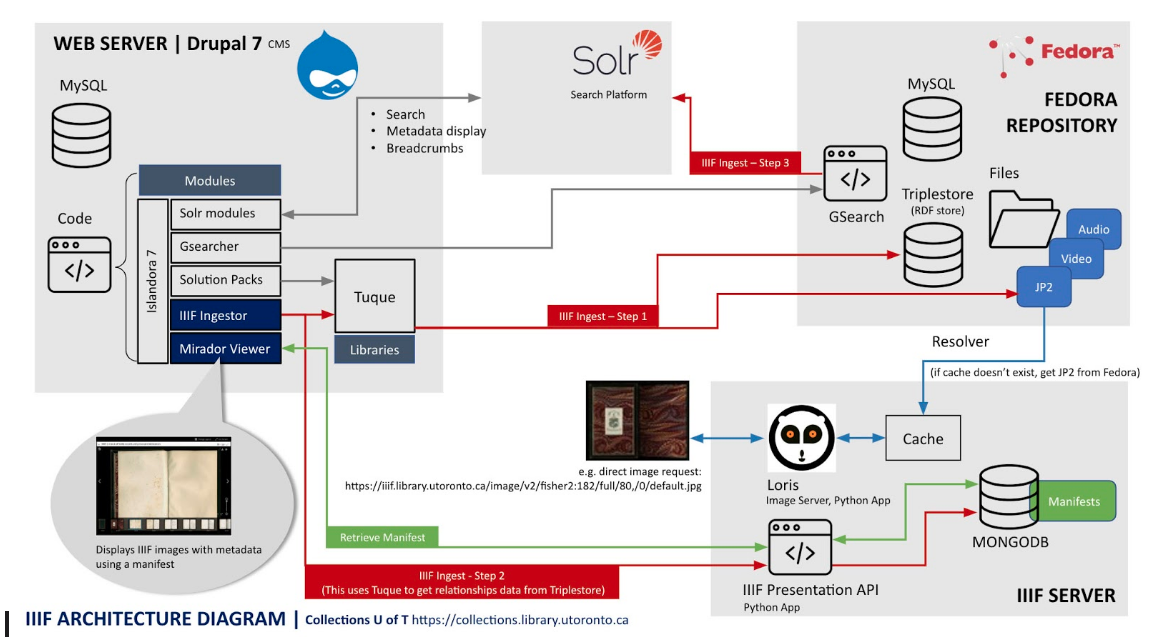
Figure 1. Diagram of the current technology supporting the Collections U of T service, described by Sunny Lee, Digital Initiatives Programmer Analyst. Collections U of T’s Web Server component uses Drupal, with IIIF Ingestor and Mirador Viewer, combined with Solr for search, and Fedora for object management. Loris IIIF image server fetches the images from Fedora and a microservice provides IIIF manifests which are stored in MongoDB. IIIF manifests are created through customized Tuque ingest scripts and posted to MongoDB via the microservice.
Collections U of T digital objects are no longer limited to being accessible through only one Islandora site. Digital objects can now be embedded in an iframed Mirador viewer on any faculty or library website, regardless of platform, while simultaneously being shared with any IIIF aggregator. IIIF has drastically changed how and where Collections U of T digital objects can be presented. This has led ITS to investigate alternate presentation opportunities for digital collections. For example, we are currently testing a simple solution for embedding archives and special collection digital objects from Collections U of T into UTL’s archival description platform, Discover Archives, [9] an Access To Memory (AtoM) instance.
In early 2017 ITS began work on Project Canopus, a two year partnership with Scholars Portal [10] to implement a preservation platform for UTL. After an evaluation of extant solutions and ongoing community initiatives it was decided that no existing solutions would provide an implementation that would scale to accommodate the University of Toronto Libraries’ needs, let alone a multi-tenanted offering from Scholars Portal for the larger Ontario Council of University Libraries (OCUL) community.
With the understanding that all technological systems will have a lifetime shorter than the life of the preserved objects, a number of small microservices were built to provide an API for a uniform and consistent experience for interacting with the underlying modular components of the platform, and allows them to be transparently swapped out for new versions when needed without any impact to users or software. Currently the main components used in Canopus are MarkLogic, Kafka, and the Elastic Stack.
Put into production in April 2019, Canopus has grown to contain information on 240 million objects representing 220 terabytes of data. Further work is planned for 2020 and beyond to extend the implementation to allow multi-tenancy.
The combination of IIIF opening up presentation possibilities, Canopus removing the need for preservation capabilities, and Drupal 7 end of life fast approaching in November 2021 has initiated our investigation into new technology solutions to support the Collections U of T service. November 2021 may seem some time away, but migrating 197,000 digital images plus 14 parent collection sites will be no small task. The first phase of our research, a scan of technology options, is now complete. Preceding this first phase was an initial broad review of digital collection platforms in anticipation of a Library Services Platform procurement process. This was completed in early 2019 by our ITS colleagues Leslie Barnes, Rachel Di Cresce, and Mariya Maistrovskaya. Their review recommended that Vital, Portfolio, and Alma-D were not suitable for Collections U of T. It highlighted a custom Samvera Hyrax or turnkey Samvera Hyku, Blacklight/Spotlight, Omeka-S, and Collective Access as solutions to continue monitoring.
Since May 2019 the department has continued to scan digital collection platform options, including further assessment of Islandora 8, the emerging Archipelago Commons platform, ResourceSpace, and Adam Matthew Digital’s Quartex solution. [11] Throughout the Spring and Summer of 2019 we were also inspired by institutions publishing and presenting on “microservices”-like digital collection solutions, such as Project Electron from the Rockefeller Archive Centre. [12] These ideas led to initiating an exploration of what we have been calling a “pluggable pieces” solution for Collections U of T. It should be noted that the “pluggable pieces” solution has relied heavily on the expertise of ITS developers and network services staff in the department, while the packaged platform solutions have been more easily explored by librarians. Framing all of this research is a set of functional requirements of the Collections U of T service in its current context. The high level functional requirements break down into 5 categories:
- Collection management and object storage
- Indexing
- Search and discovery
- User management and authentication
- Statistics (collection and usage)
Related to these high-level functional requirement categories, there is an interest in developing linked open data and annotation tools for digital collection objects. Both of these goals have been on our minds while conducting research but are ultimately “nice to haves” and outside of the scope of requirements for this first phase of research. Another important consideration during the course of our research has been UTL’s pending migration to Alma and Primo in 2020. We have been learning about Alma and Primo while concurrently researching other digital collection technology solutions. Additionally and importantly, accessibility is a priority for any technology we move forward with and will be assessed in greater detail during the next testing phase of our research process.
As a result of our research to date, we have proposed that ITS does not pursue any implementation of the packaged platforms that have been reviewed thus far. Instead, we have recommended that ITS focus on a “pluggable pieces solution” to prepare for migration away from Islandora 7/Drupal 7 and Fedora 3. We will not be investigating digital preservation repository solutions, as this service is now performed by Project Canopus. We will be replacing Fedora 3 with a simpler digital object storage solution. For the sake of brevity in this article, our notes on each platform reviewed from May 2019 to date are available in a public Google document. [13] Within this article, we have chosen to include our Islandora 8 considerations alongside our proposed “pluggable pieces” path forward, along with brief mentions of the institutions that have inspired this approach.
Islandora 8
Islandora 8 [14] is an obvious option to consider first for migration. For us, the benefits of using Islandora 8 (i.e. Drupal 8, Solr, and a self-described “bento box” of other technology) include continuing to leverage the Drupal expertise we have in ITS. We have already begun to use Drupal 8 for other digital library projects in the department. Using Drupal 8 for Collections U of T would beneficially build on that existing knowledge and infrastructure. Islandora 8 is more closely tied to Drupal 8 than Islandora 7 was to Drupal 7, especially in terms of managing collections and object storage. For example, metadata is no longer just an XML file in Fedora that gets indexed in Solr. With Islandora 8, metadata is actually stored and managed as fields in the Drupal database. The Introduction to Islandora 8 webinar [15] notes that “metadata profiles are created via Drupal content types” and “it can be serialized into other formats (XML, JSON, JSON-LD) on demand”. Batch metadata updates are made possible through Drupal’s Views Bulk Operations by a “Modify Field Values” operation. Metadata display is configurable in the Drupal View associated with the object type. Islandora 8 promises to make good use of Drupal this time around.
Islandora 8 community developers are also proposing interesting ways of integrating IIIF, such as generating IIIF manifests from Drupal Views results. [16] The downside of continuing to use Drupal for Collections U of T is that we will still be using technology that has a steep learning curve for collection owners – possibly even steeper for Islandora 8, since the level of configuration possibilities has increased dynamically compared to 7, upon first look. Continuing down the Drupal path means that the Collections U of T service must continue to offer collection owners with sufficient Drupal 8 training and support. The question that hangs on Drupal 8 is: will it complicate or simplify collection building for our collection owners?
Overall, Islandora 8 does a lot. It is an impressive and powerful repository platform, but it might do a lot more than we need – especially considering all of the preservation functionality it comes along with. We have considered that Drupal is the primary data store and Islandora 8 can be configured so that you don’t have to use Fedora or any preservation functions. Avoiding it is possible through Islandora 8’s use of the Drupal Context module [17] and editing the field containing the file for a media content type. For example, within the Image content type, field_media_image’s Field Settings can be set to either Drupal’s public file system or Fedora. Other preservation workflows, such as generating derivatives when original files are ingested, are also configurable through the Context module. Out of the box Islandora 8 is set up to perform these actions. [18] This makes sense, since most institutions use Islandora for preservation. For Collections U of T, preservation is not a functional requirement. The depth of configuration necessary to remove preservation from Islandora leads us to wonder how much work will be required by our team to avoid the preservation functions baked into Islandora 8 per top-level collection in Collections U of T (a reminder that, for us, each top-level collection is equal to one site/discovery point – meaning that, if we were to use Islandora 8, each site would require this level of customisation).
Finally, at the time of our review, Islandora 8 did not yet have the functionality to support some requirements that we needed for a migration test – though many of these requirements have since been completed or are on the Islandora 8 roadmap [19] and may become available with time. More anecdotally, a migration to Islandora 8 feels like it would boil down to replacing one large repository platform (Islandora 7) with pieces and functions that we no longer need with the new version of that large repository platform (Islandora 8). Most reviews of “packaged platforms” left us with this feeling and so our interest turned to colleagues publishing and presenting on an alternate route forward.
Pluggable Pieces
Investigating options for pluggable pieces of technology to support Collections U of T has not been as straightforward as researching packaged platform solutions. We celebrated the publication of “BC Digitized Collections: Towards a Microservices-based Solution to an Intractable Repository Problem” from Boston College Libraries in Issue 44 of Code4Lib [20] and are also very interested in the work of the University of Denver Libraries in building a digital collections “ecosystem.” [21] We have spent some time over the past few months discussing what a similar approach would look like for Collections U of T. It might have been our Senior Application Programmer Analyst, Bilal Khalid, who said to make it “pluggable”. While the Rockefeller Archive Center proposed microservices as a visual of stitching seams together, we have run with Bilal’s visual of plugging pieces in and out based on the functions and needs of the Collections U of T service. This approach appeals because it feels more flexible than implementing an entirely new platform that might expire in under 5 years, and seems resource efficient because it allows us to consider existing technology infrastructure in our large department that we can potentially re-use. It is early days and more exploration is needed, but the ideas we are considering are described below.
Collections management and object storage
Our current practice for creating collections starts with images and metadata being prepared for ingest by collection owners. In most cases, collection owners compile their image files along with corresponding xml files (usually MODS) and give us access to these files through shared network drives or other media storage devices. File structure follows Islandora ingest requirements (note that the ingest process is preceded by one, or many, consultations on the needs and structure of the collection). Our Islandora ingest scripts then create the digital objects in our Collections U of T infrastructure, which includes depositing JP2 copies of the images (we do not store the original TIFFs) plus metadata into Fedora. The ingest scripts also generate IIIF manifests that are stored in MongoDB.
In a “pluggable” scenario, ITS developers have proposed simplifying this ingest process by untangling our ingest scripts from Islandora and Fedora and instead creating a platform-agnostic ingest process. In this scenario, what we are calling a “Collections Manager” interface would be built upon existing APIs to enable collection owners to create and manage collections and deposit digital objects and corresponding metadata files through a simple user interface. This will make use of some components (independent and reusable bits of code) which will be built in-house – and can potentially be reused for other services or digital projects. An “Uploader” component will take in raw files and upload them to a remote location. As soon as the Uploader finishes a process, a “Converter” component will verify and convert the files ready for ingesting. Using these two components, the Collections Manager will upload the media and metadata files to the object storage and populate a database while also sending metadata to an indexing service. Upon requests from the public, IIIF manifests will be generated by the Presentation API based on the relationships specified in the database. Images will be served by the IIIF Image Server downloading JP2s from the object storage. To replace Fedora, we are looking at using MinIO for digital object storage.
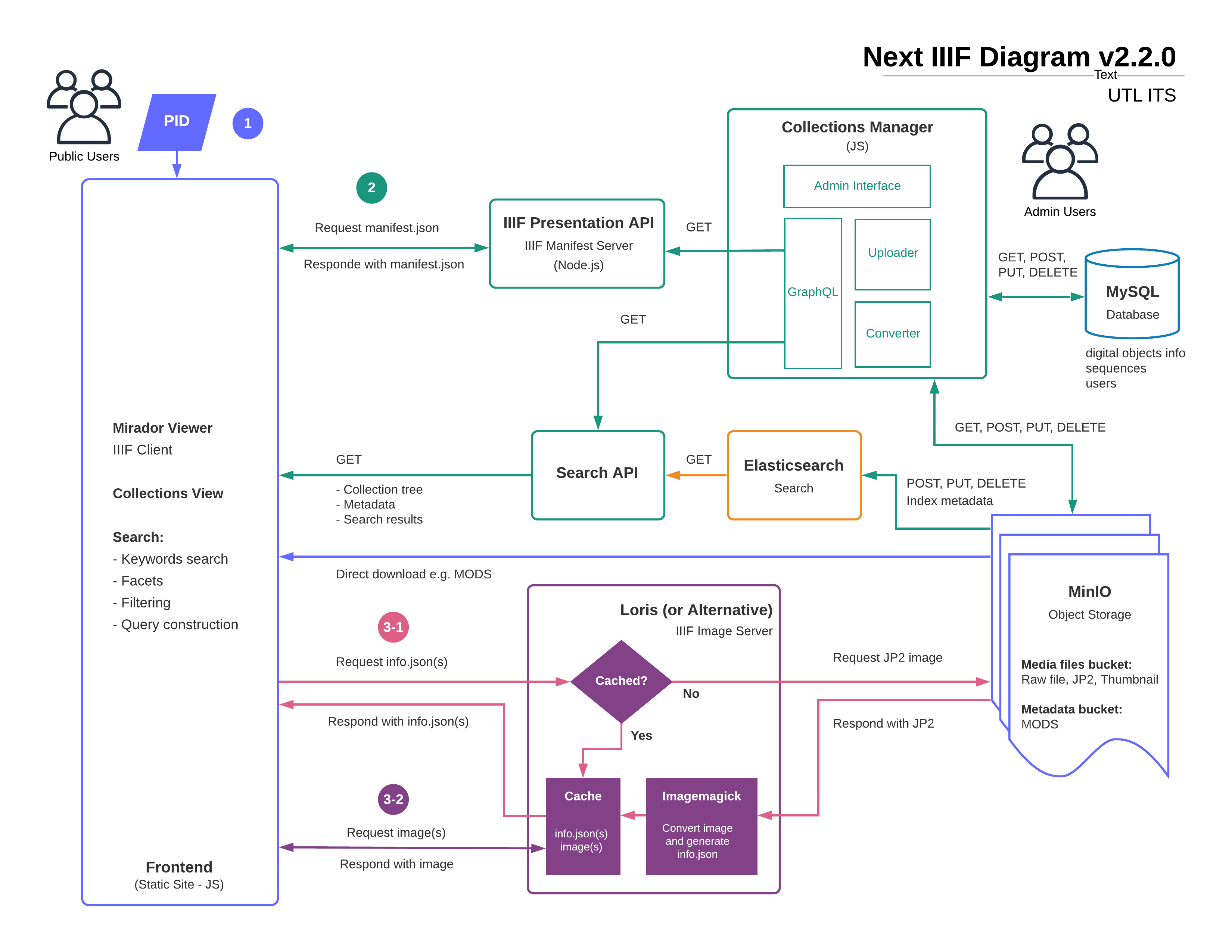
Figure 2. Diagram of proposed “pluggable pieces” to support the Collections U of T service, described by Sunny Lee, Digital Initiatives Programmer Analyst.
We are also considering Elasticsearch for search and indexing, as this is used for other services in our department, in combination with static html pages for presentation. We recently developed a small bit of Javascript that will direct each PID of a digital object in Collections U of T to a permanent URL that displays the object on a static page – for example, https://collections.library.utoronto.ca/view/storynations:2197711. The static page currently only contains a Mirador embedded viewer, but we will be expanding this page to include the metadata text of the object. We also plan to review how other static site tools might work for this approach, such as GatsbyJS,[22] or static site generators for digital collections, including the University of Idaho’s CollectionBuilder-GH,[23] Columbia University Libraries’ Wax,[24] and a React discovery tool maintained by Christopher Johnson. [25]
Plugging in to existing discovery points
After creating workflows for collection management, we then want to explore existing discovery points to present digital objects. In September 2019, UTL announced a migration to the Ex Libris Library Services Platform, Alma, including the Primo resource discovery service. In the coming weeks, we will begin to investigate connecting IIIF digital collections to Primo for discovery. For some time we have also been interested in connecting IIIF archives digital objects to Discover Archives, our Access to Memory (AtoM) instance. This will require considerations around performing item level discovery within an archival finding aid database and close consultation with archivists and users performing research on primary documents described hierarchically. We will also pursue other opportunities for distributing UTL collections to IIIF aggregators, such as the Biblissima Manuscripts & Rare Books aggregator,[26] and research into surfacing digital collection objects and their associated IIIF URLs through Wikidata.[27]
Testing the Path Forward
Layered on top of this research is our desire to build on the lessons learned after running the Collections U of T service for six years. Part of that desire is acknowledging that the context in which the department initially reviewed technology to support the service has shifted – and it will continue to shift. For example, IIIF has offered new presentation and access possibilities that we could not have anticipated. IIIF has allowed us to move beyond the goal of building one “portal” site to instead pursue multiple points of discovery – even moving between technology platforms by embedding digital objects into any number of existing or yet-to-be-created discovery access points. This both simplifies and complicates our goal of selecting technology to provide access to digital collections because there may not be one technology solution for access.
Moving forward with our research, we want to choose an approach to building infrastructure that will allow us to be more flexible and pluggable. Recognizing that these terms are contextual, our next phase of research will consist of in depth testing and pilot projects to explore the pluggable pieces solution we are proposing – both in our department, as well as facilitated testing with collection owners and users. Part of this testing will be strategizing how to best “plug into” existing technology infrastructure to deliver the Collections U of T service and meet our users where they want to find content.
It was thought that others in the Code4Lib community facing Drupal 7 end of life may find some value in the shifting context of the current Collections U of T Islandora 7 instance and the initial technology review we have conducted. While we move forward with the next testing phase of our research we are looking for opportunities to share our findings. As a start, we hope this article is helpful in contributing to the public discussions, in Code4Lib as well as associated communities, around the technologies our libraries select to support access to digital collections.
References and notes
[1] Quick Facts | University of Toronto. [accessed 2019 Dec 12]. Available from: https://www.utoronto.ca/about-u-of-t/quick-facts
[2] All of these ColdFusion sites have since been migrated, most were migrated to Islandora 7. We used Archive-It to capture the original ColdFusion sites – they are listed among UTL’s Digital Collections. University of Toronto Digital Collections | Archive-It. [accessed 2019 Dec 12]. Available from: https://archive-it.org/collections/6473
[3] Heritage U of T. [accessed 2019 Dec 12]. Available from: https://heritage.utoronto.ca/
[4] While splitting up technology solutions for access and preservation might not be possible or desirable for all institutions, it has worked well for the UTL ITS context. Anecdotally, not all collections intended for discovery within Collections U of T require long term preservation. Removing preservation as a functional consideration has freed our current Collections U of T technology review from being locked into considering only the, often weight-y, technology solutions that do both preservation and access
[5] Read more about Chris Crebolder and Andy Wagner’s work on this in their “From An Island to Islets: Reimagining Islandora in a Microservices World” presentation – goo.gl/r4TXCn
[6] View the project at https://paleography.library.utoronto.ca/ and learn more about IIIF at https://iiif.io/
[7] The work is available at https://github.com/utlib/islandora_mirador_bookreader. More information about Mirador is available at https://projectmirador.org/
[8] The Collections U of T IIIF manifest is available at https://iiif.library.utoronto.ca/presentation/collections
[9] https://discoverarchives.library.utoronto.ca/
[10] Scholars Portal is a service of the Ontario Council of University Libraries (OCUL). Founded in 2002, Scholars Portal provides shared technology infrastructure and shared collections for all 21 university libraries in the province of Ontario – https://scholarsportal.info/
[11] A very helpful starting point for anyone embarking on a digital collection platform reviews is Ashley Blewer’s spreadsheet: https://bits.ashleyblewer.com/blog/2017/08/09/collection-management-system-collection/
[12] Arnold H. Project Electron Update: Building Microservices for Integration. 2018 Dec 13 [accessed 2019 Dec 12]. Available from: https://blog.rockarch.org/project-electron-update-building-microservices-for-integration
[13] Our May 2019 research omitted platforms that do not support IIIF, since IIIF is core to the Collections U of T service. All Phase 1 – Collections U of T Technology Review research and notes are publicly available at http://bit.ly/2shxNfV
[14] Islandora 8. [accessed 2019 Dec 12]. Available from: https://islandora.ca/islandora8
[15] https://www.youtube.com/watch?v=ZaEQccS_9fY
[16] Generate a IIIF manifest from views results · Issue #1263 · Islandora/documentation. [accessed 2019 Dec 12]. Available from: https://github.com/Islandora/documentation/issues/1263
[17] Context. Islandora/documentation. [accessed 2019 Dec 12]. Available from: https://islandora.github.io/documentation/user-documentation/context/
[18] “By default, derivatives are generated from Media with the “Original Files” term selected. When an Original File is uploaded, if the node that owns it has an “Image” model, image derivatives are created.” – Media – Derivatives. Islandora/documentation. [accessed 2019 Dec 12]. Available from:
[19] Proposed Technical Roadmap. Islandora/documentation. [accessed 2019 Dec 12]. Available from: http://bit.ly/2EaisQY
[20] Mayo C, Jazairi A, Walker P, Gaudreau L. BC Digitized Collections: Towards a Microservices-based Solution to an Intractable Repository Problem. 2019 [accessed 2019 Dec 12];(44). Available from: https://journal.code4lib.org/articles/14445
[21] Pham K, Clair K, Reyes F, Rynhart J. 2019. In a third space: Building a horizontally connected digital collections ecosystem. Proceedings of Open Repositories; 2019 June 10-12; Hamburg. Available from: https://lecture2go.uni-hamburg.de/l2go/-/get/v/24782. See more information on the University of Denver Library system’s front-end and back-end is available at https://github.com/dulibrarytech
[22] Fast in every way that matters. [accessed 2019 Dec 12]. Available from: https://www.gatsbyjs.org/
[23] CollectionBuilder. [accessed 2019 Dec 12]. Available from: https://collectionbuilder.github.io/collectionbuilder-gh/
[24] Wax. [accessed 2019 Dec 12]. Available from: https://minicomp.github.io/wax/
[25] Ubleipzig. React Discovery. 2019 Sep 5 [accessed 2019 Dec 12]. Available from: https://github.com/ubleipzig/react-discovery
[26] Biblissima. IIIF Collections of Manuscripts and Rare Books. [accessed 2019 Dec 12]. Available from: https://iiif.biblissima.fr/collections/
[27] Poulter M. Build your own Digital Bodleian with IIIF and SPARQL. 2019 May 30 [accessed 2019 Dec 12]. Available from: https://blogs.bodleian.ox.ac.uk/digital/2019/03/13/build-your-own-digital-bodleian-with-iiif-and-sparql/
About the Authors
Kelli Babcock has been the Digital Initiatives Librarian with the University of Toronto Libraries since 2013. She coordinates the Collections U of T and Discover Archives services, in addition to a number of other digital projects at UTL.
Sunny Lee is a Digital Initiatives Application Programmer Analyst at the University of Toronto Libraries. She is currently working on the development and support of web-based applications for a wide range of ITS projects, with a particular focus on digital collections.
Jana Rajakumar is an Application Programmer Analyst at the University of Toronto Libraries. His recent efforts include building the IIIF presentation API used by Collections U of T and other digital projects, revamping the MyMedia service (an in-house media streaming service) and containerizing existing and new applications using Docker.
Andy Wagner works as a Senior Software Engineer and the Repository Architect at the University of Toronto Libraries and is involved in helping the library and the university preserve its growing body of digital content. Andy also coordinates the UTL MyMedia service.

Subscribe to comments: For this article | For all articles
Leave a Reply