by Whitney R. Johnson-Freeman, Mark E. Phillips, and Kristy K. Phillips
Introduction
Like many other institutions, the University of North Texas (UNT) Libraries operates an institutional repository to collect, preserve, and make available the scholarly and creative output of its faculty, staff, and students. The institutional repository, UNT Scholarly Works (https://digital.library.unt.edu/scholarlyworks/), has been implemented as a collection in the UNT Digital Library (https://digital.library.unt.edu/) alongside other collections such as the UNT Electronic Theses and Dissertations, UNT Data Repository, UNT Graduate Works, and UNT Undergraduate Works. UNT Scholarly Works has been in operation for nearly a decade and has grown to include over 6,100 items. The collection has been managed through a combination of email-based communications and workflows for receiving new materials, and an existing folder-based workflow that is used for digital projects throughout the UNT Libraries’ Digital Libraries Division. In early 2020, there were two events that caused the team to review our workflows. First, a new repository manager took over the role and needed to learn the workflow. This necessitated the review of existing documentation, recognizing that it was not as thorough as needed, and the consideration of new tools and workflows for managing the repository. The second event that caused a shift in thinking was the COVID-19 pandemic, which moved all work with the repository to remote work. This change further demonstrated the need to have documented, repeatable workflows so that multiple people could work on adding new content without getting in each other’s way.
As a way of fixing these issues, we turned to a project management tool that was being used successfully by our software development team to manage their projects. This common software suite called GitLab was used to create a method for tracking items and tying our processes together. In addition to GitLab, we further codified our workflows on a departmental wiki that empowers us to keep our documentation more up-to-date as workflows and processes change. Finally, we took advantage of the existing folder-based workflows used in other areas of the division and further refined our workflows to take advantage of this simple system for keeping track of files and digital objects on our shared network space. So far, it’s been a successful, simple solution that has been able to evolve as our needs and working arrangements change.
Workflows: Moving from Old to New
As in most institutions with long-running projects like our UNT Scholarly Works repository collection, the process for collecting, processing, and ingesting content into our digital library system has evolved over the years. Since the beginning of the collection, the preferred mechanism for faculty to submit content has been emailing the repository manager at a shared repository email address. The shared nature of the email address allows for multiple members of the team to have access to new submissions but also causes challenges in trying to keep track of these same submissions as they are moved through the workflow.
While many messages to the repository email address are content submissions in digital format, others are requests for help in digitizing legacy resources such as publications, datasets, and grey literature. This content is also handled by the repository manager and involves several additional steps that are not present in born-digital workflows. Examples of these steps include receipt of the physical material, digitization of the material including quality control, and then finally loading the material into the repository.
We’ve tried to keep our workflows simple, so they can apply to most types of submissions. The majority of our submissions are currently received in digital format. The workflow for these items revolves around confirming rights for hosting, preparing the files to be ingested, and creating the metadata record for the item. Figure 1 provides an overview of the workflow in place for processing new items into UNT Scholarly Works.

Figure 1. Workflow for Processing Digital Items into UNT Scholarly Works.
GitLab overview and our workflow
GitLab is a web-based project planning and source code management application that is built on top of the Git distributed version control system [1]. GitLab can be used as a hosted solution or its Community Edition can be installed on local servers. The UNT Libraries has been using a locally hosted version of the Community Edition of GitLab to successfully manage many of its software development projects. Additionally, in 2018, the UNT Libraries’ website was migrated from the Drupal content management system to a static site generator using Jekyll. To manage the content creation for the website, we used another installation of GitLab and configured it for that type of content. With so much existing expertise with this software platform, it made sense to try using it to manage the content workflows for UNT Scholarly Works.
To get started with GitLab, we established a new project called unt-scholarly-works. In GitLab, a project is the primary unit of organization and includes a number of components that are useful for managing a software project. The new unt-scholarly-works project includes features such as a Git enabled repository for managing code, an issue tracker for creating issues, discussing specifics of an issue, assigning responsibility, and managing the issues. A project in GitLab also includes a wiki that can be used to develop documentation about the project. Finally, a suite of access controls can be used for a project to designate who can perform different tasks such as viewing, changing, and deleting content.
Once the unt-scholarly-works project was created, the primary component we were interested in using was the issue tracking system. We had seen it used in a number of different configurations in software development projects and had ideas of how it might be useful for managing the UNT Scholarly Works workflow.
GitLab Issues
The component of GitLab that we use for creating tickets is called issues. In a software development project, this is the method for submitting new features, changes, or updates to a project, but we use it as a tracking tool within our workflow. When we receive a content submission at the repository email address, a new issue is opened with details from the submission email. The required parts for an issue are:
- Unique title
- Processing checklist
- Submitter’s email
- Notes
- Labels
A unique title is necessary for tracking items between GitLab and our folder system, especially when multiple items are submitted at once. Our titles are structured with underscores separating these parts:
- Submission Date, in year-month-day format_
- Submitter_Name, last name followed by first name
For instance: “2020-11-25_Last_First”. When multiple items are submitted at once by the same person, identifying details are added to the end of the title, like keywords from an item’s title or the item description: 2020-11-25_Last_First_Repository_Workflow or 2020-11-25_Last_First_Handout. This unique title is used for the corresponding folder name on our network drive to encapsulate the files for this item and move it through its folder-based workflow. A full description of that process is included later in this article.
A checklist is included in the issue to ensure that all steps have been completed. These checklists are added based on templates we’ve saved in GitLab. The GitLab issues system has a method for creating different templates for issues that get created within a project. These templates can be customized to the workflow and allow for adding placeholders to each issue so that important information for an issue is not missed. We have developed templates for two types of submissions: new item submissions or item replacements. Examples of these two templates are provided in Figure 2 and Figure 3. The templates include the relevant steps for the different processes required for the different submission types. More information on creating issue templates is available from GitLab [2].
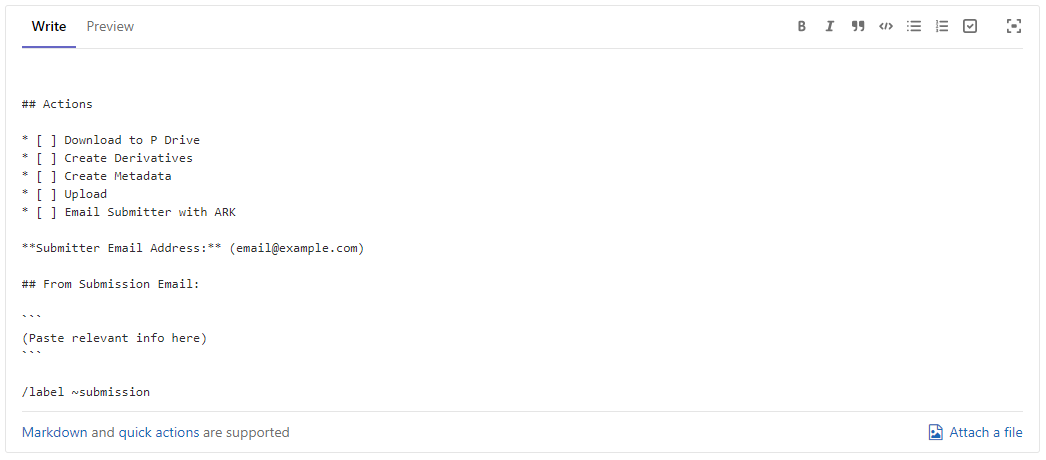
Figure 2. Issue Template for New Submissions.
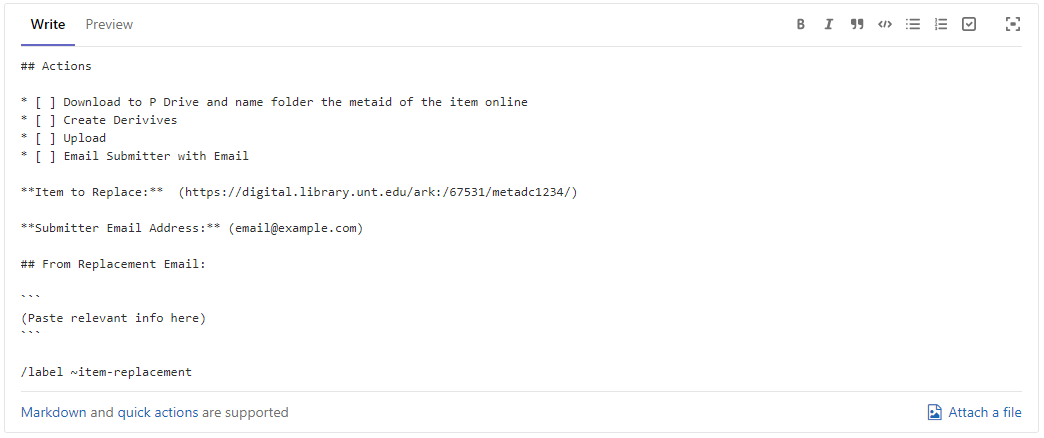
Figure 3. Issue Template for Item Replacements.
Because most of our submissions arrive via email, the submitter’s email address is also included to help connect the issue to the repository account’s inbox.
The notes section is used to document any relevant information provided from the submitter, like conference information, and any other information that we might need during processing, like licensing guidelines from a publisher.
Labels
We make extensive use of labels that can be applied to an issue as part of the GitLab issues system. It is possible to add one or more labels to an issue and later these labels can be used to sort and filter issues. For each new issue that is added to the system, we use at least two labels, one based on the type of content of the submission and the other a high-level label designating the type of submission. These labels are helpful for tracking where an item is in the UNT Scholarly Works workflow.
We’ve opted for broad labels that can help identify a submission at a glance. Two high-level labels are used to label what kind of submission was deposited:
- Submission
- Correction
Another set of labels reflect the major content types that we receive as submissions. Each of these content types have similar workflows but it is helpful to differentiate between them. Here is a listing of the major content types we have designated as labels:
- Audio
- Correction
- Data
- Poster
- Presentation
- Text
- Video
There are two additional labels we use that aren’t related to item type but that relate to the state of the item in the workflow:
- Checking Rights
- Embargo
These are steps that tend to hold up processing, so these labels let us see why an issue hasn’t been closed. For embargoed items, we can also add a due date to the issue which will remind us to confirm that the item’s access rights are updated in the repository and notify the submitter that their item is now publicly available.

Figure 4. Example Issue for a newly submitted item.
In addition to improving issue tracking, another benefit of this label system is that we can go back to see what types of submissions we’ve received. This additional use of the label system provides a data layer that we can reference in the future to see any trends with our submission process. For example, we can select the Poster label and see quickly how many Poster issues have been closed or that are still open. An example of an issue is provided in Figure 4.
Other Benefits of GitLab
Once an issue has been opened, there are a few different features we use to create an additional layer of documentation and support for our team. The first is that GitLab tracks all changes or updates to an issue with the person, date, and time. The next is the comment feature. Comments can be added to issues, and others can respond to that comment or create their own. We can also direct a comment to an individual who is also a member of the unt-scholarly-works project, and they will be notified that there is a comment waiting for them in GitLab. The final feature we’ll mention is the ability to assign individuals to an issue. This adds the issue to the assignee’s list of issues and presents the user with an updated list of activities that need to be completed for items being added to UNT Scholarly Works.
In addition to changes being tracked for issues in the system, almost everything is reversible. If an issue is closed but then something comes up where it needs to be reopened, that is a simple task in GitLab and doesn’t require much effort at all. As a team of GitLab users that are also working remotely, the ability to undo changes allowed us to experiment with how to use different features correctly and figure out how they might fit in our new workflows.
GitLab has allowed the repository team to monitor the submissions to UNT Scholarly Works through a system that is detached from the primary repository email account, but did not require custom programming or development. We made use of the existing features of GitLab to customize our unt-scholarly-works project to our local needs. Finally, it has allowed us to experiment with modifications to our workflows, and the overhead for each modification is very low as we only have to change labels on issues in order to find out if an idea will or won’t work. For example, as we explained earlier, when we initially started with GitLab we modeled our label system too closely to the folder-based workflows we use on the network drives. We were able to experiment with different approaches to labeling issues without affecting other parts of the workflow for UNT Scholarly Works.
There are a number of other features of GitLab that we haven’t fully explored, including some related to issues and labels. These include the board and milestones features. Milestones, which are a specific tool used to manage timetables, would allow us to indicate the time-sensitivity of a group of issues within a project, such as a deadline for uploading a number of items to the repository. Issue boards, which are a tool used for project management, would allow for a more visual way of organizing and managing our submission issues in the UNT Scholarly Works workflow. Both of these features are something we plan to explore as we continue with GitLab.
GitLab is how we track our ingesting process, but the folder-based workflow is where the processing of deposited files actually happens. As mentioned previously, we’ve created our GitLab checklists and labels to correspond to our folder-based system to help blend the workflows together.
Folder-based workflow
The concept of folder-based workflows has been present in the UNT Libraries’ Digital Libraries Division since it was formed. While it is a simple concept, it provides a fairly robust process for managing projects on our shared network drive. We have made use of folder-based workflows for both born-digital as well as digitized content workflows and they are flexible enough to allow for modification to suit a given project.
What are they?
The basic idea of a folder-based workflow is that each project has a folder created for it on a shared network drive. Each step in the workflow is used as a folder name. Objects within each folder are at that step within the workflow. This ensures that every step in the workflow is known and accounted for. This can be tailored to each project, and we use this workflow for submissions to UNT Scholarly Works.
For each project, the workflow will be contained within its own folder. Even if the project is relatively small, for example digitizing four maps, it will receive its own workflow folder. This folder may be named something like “scanned_from_ohs” for a project that had digital materials originating at another institution. All of the files that are important to this project are stored in this folder structure. The folder names are based on local naming conventions.
The workflow is essentially an ordered sequence of folders that define the steps in a workflow. For example, there is often the process of applying Optical Character Recognition (OCR) to a set of scanned items. This step usually happens after other steps have been completed, like scanning the documents and performing quality control checks on the images. After OCR has been completed, we then need to create descriptive metadata and can stage the content for uploading to the digital library system. In the rough workflow just outlined, there might be one or more people involved in moving digitized items through a workflow.
To facilitate this we have outlined a workflow that looks like this.
scanned_from_ohs
0.Staging/ 1.Scanning/ 2.ToQC/ 3.Issues/ 4.ToOCR/ 5.ToMetadata/ 6.ToUpload/ 7.Uploading/ 8.Uploaded/
While the steps are somewhat arbitrary and are aligned with workflows at the UNT Libraries, a description of the steps is helpful to understand how items move through the workflow. Before we do that, it is helpful for us to establish a few guiding principles of these workflows.
- Only move content when you are ready for someone else to take it as part of the following step.
- Keep folders as shallow as you can.
- The location of an object in the folder structure should reflect the work that needs to be done to the object.
- Adjust the folder order and name to reflect the workflow.
With these guiding principles in place, we can talk about how content moves through a workflow.
First off, in the 0.Staging folder, we can begin to sort items that need to be digitized. In many cases, we can create directories that will act as containers for digital objects as they move through the process. We have found that representing a digital object as a folder and naming it with the unique identifier for the item is helpful. Then, all files related to that object are placed inside this object’s folder. Moving an object between steps in the workflow is now just moving a folder. By keeping the folder structure shallow with ideally just one level of hierarchy, the object folders can easily be moved around within the workflow folders making it easy to see how items are distributed throughout the workflow.
The next step in this workflow is called 1.Scanning. As an example, we will be digitizing a journal for a historical society. As a technician is digitizing the item, they can place working files into this workflow step’s folder. Once they have completed the initial quality control check, they will move the object folder to the next step’s folder in the workflow called 2.ToQC. In this step, another round of quality control is performed by another person in the unit. As this step is being completed, if there are any issues, such as missing pages or images that need to be rescanned, the person completing the quality control can move this object folder to the 3.Issues folder. If there are no problems, they can move the object folder to the 4.ToOCR folder in the workflow. At this step in the workflow, the person responsible for OCRing items will take items from this workflow folder and process them with an OCR engine. After that has completed, the object folder is moved to the 5.ToMetadata folder, where they will have descriptive metadata created for them. This step may involve full-record metadata creation or could involve the creation of basic metadata that will be updated and completed later when it is loaded into the system. After this metadata has been generated, the object folder is moved to the 6.ToUpload folder. The final three steps in this workflow outline the ingest activities of the UNT Digital Library where content is staged for upload and finally ingested into both the access repository, Aubrey, and the preservation repository, Coda. During this ingest period, the object folder is moved into the 7.Uploading folder to indicate that it is being uploaded to the system. Once verification of upload has taken place, the object folder is moved to the final folder, 8.Uploaded. At some point in the future when the project has completed, the files in the object folder are deleted to recover network space.
Folder-Based Workflow Discussion
With the overview of the folder workflow complete, there are some things to discuss. This is a very simple way of organizing projects. At UNT this method allows us to have multiple people working on a single project at different times and it is clear what is happening along the workflow with a given digital object because of its location. It is important for all participants in the project to remember to only move items into a subsequent folder when they are ready for someone else to take that object and process it further. If an object hasn’t finished the step that its location in the workflow folder designates, it shouldn’t be moved. This important rule allows for different team members to work independently and confidently within the workflows.
Because we try to keep the folder structures as shallow as possible, ideally with only one level of folders representing objects in each of the workflow folders, it is easy to see how much content is waiting in what steps for a project. Simply browsing the folder structure gives an overview of where things are in the workflow. We have found that it is important to keep objects at a single level within the workflow folders. As folders become more deeply nested or contain multiple other folders, it becomes harder to understand the progress of the overall workflow or tell when objects are incomplete.
Because workflows can differ depending on the type of project, type of content, or because of unique requirements, it is important for the folder names to be descriptive about the step in the workflow that it represents. The number preceding the step is important to define the sequence of the steps, but the name of the step in the folder’s name should be clear to make the step understood by others involved in the project.
Finally, if we start a project and discover that the initial folder structure doesn’t meet the needs of the project, we change the structure to meet the needs. This is helpful because there are often many projects and a variety of types of projects being worked on at any given time. In order to keep track of what is happening within a specific project, it is important to make sure the folder structure matches the workflow.
While the folder-based workflow is not a particularly complicated management structure for projects, it has served its purpose well over the years.
UNT Scholarly Works Folder-Based Workflows
As we have mentioned before, the UNT Scholarly Works workflows are split between high-level tracking in GitLab in combination with object-level tracking in a folder-based workflow. There are different content types that are deposited for inclusion in the repository. We use different folder-based workflows for each of these content types so that their specific requirements are documented as part of the folder structure.
Each of these folders contains subfolders for each step we have for processing that item type.
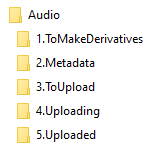
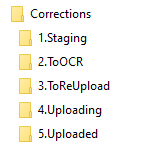
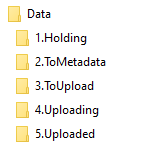

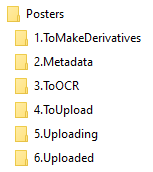
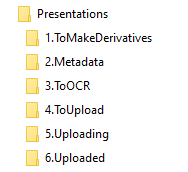
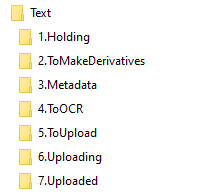
Figure 5. Example folder-based workflows for the different content type submissions in UNT Scholarly Works.
You will notice that in the seven examples in Figure 5 there are many steps or even whole portions of the workflows that are similar to others. This is seen as a feature of the folder-based workflows. In the case of the Posters and Presentations workflows, it isn’t so much the workflows but the final ingesting steps that are slightly different for oversized posters as compared to the presentations. By splitting them up into two separate workflows, it is easier for the person doing the final ingest to remember the different configurations needed to ingest the items into UNT Scholarly Works. Some of the workflows, specifically Audio, Video, and Data do not contain steps such as ToOCR because that step is not appropriate. This is another example of tailoring the folder names to the needs of the specific workflow.
When an item is received for ingestion into UNT Scholarly Works, an object folder is created in the first folder in the appropriate workflow. The object folder’s name is the same as the issue name in the unt-scholarly-works project in GitLab. Once an item has been successfully moved through the folder-based workflow on the network drive, the contributor is emailed with information about their submission and the GitLab issue is closed to complete the whole process.
Conclusion
It is important for us to occasionally rethink our workflows and examine the tools we use to manage projects. The occasion of having new staff is often a good time to make sure that documentation is up-to-date and reflects the actual workflows in place at the institution. A situation like the COVID-19 pandemic can further identify challenges to workflows when new requirements are placed upon them, such as completely remote workers and different people being involved with the process.
The UNT Libraries took a combination of these two events as an opportunity to do such a thing. By further documenting the use of folder-based workflows that had been used successfully in many other projects, we were able to adjust our processes so that they better reflect the items we were receiving from faculty, staff, and students submitting content to the UNT Scholarly Works repository. Likewise, we moved from an ad hoc email-based workflow for tracking submissions to a new process using the web-based tool GitLab. This software allowed us to further codify our workflow using the tools and features present in GitLab projects, such as issues, labels, and a wiki. By focusing our efforts on simple-to-adjust methods for organizing content, like the folder-based workflows, we are able to make changes to workflows without additional overhead. Likewise, working with a system that is already being used by several groups within the organization allows us to leverage existing infrastructure for our needs and doesn’t add additional tools to support in the organization.
Together GitLab and the folder-based workflows have allowed us to improve the productivity of the unit around submissions to the UNT Scholarly Works repository.
Notes
[1] For more information on Git and GitLab in a library context see Engwall K, Roe M. 2020. Git and GitLab in Library Website Change Management Workflows. The Code4Lib Journal [Internet]. (48). Available from: https://journal.code4lib.org/articles/15250.
[2] More information on creating Issue templates in GitLab is available at https://docs.gitlab.com/ee/user/project/description_templates.html#description-templates.
About the Authors
Whitney R. Johnson-Freeman is the Repository Librarian for Scholarly Works, the institutional repository, at the University of North Texas. Her primary focus is in digital curation, but she is also interested in data and assessment.
Mark E. Phillips is the Associate Dean for Digital Libraries at the University of North Texas. He has a wide range of research interests, including web archiving, digital library infrastructure, and metadata quality.
Kristy K. Phillips is a PhD student at the University of North Texas College of Information. Her research focuses on computational linguistics, with a particular interest in building tools for low-resource languages.

Subscribe to comments: For this article | For all articles
Leave a Reply