by Kyle Huynh, Natkeeran Ledchumykanthan, Kirsta Stapelfeldt, Irfan Rahman
Editorial note: This post was updated on 14 November 2022 to include changes requested by the author. Please examine the Wayback-computed difference between the original article and this version to see the changes.
Introduction
“Persistence is a complex and expensive undertaking, eased only here and there by technology.” (Kunze, J., 2003)
As an increasing number of digital objects enter library collections, the challenge of persistence becomes ever-more germane for memory institutions. Most institutions with repositories are making some kind of promise of continual access, and one manifestation of this promise is the stable, opaque, ‘clickable,’ identifier — a persistent URL— based on an ARK, PURL, URN, Handle, DOI, Wikidata QID, or ORCID ID (to name but a few). These identifiers promise both continual access and disambiguation on an increasingly complex information stage and facilitate librarians’ professional commitment to act as stewards of the distinctive collections/datasets of their local communities.
The University of Toronto Scarborough’s Digital Scholarship Unit (DSU) provides access to complex, multimedia digital objects across several web applications (maintained in the open-source digital management system Islandora). Recently, the unit has received increased requests for citation features so digital objects can be referenced in other contexts. There is also increasing interest in providing and using machine-readable endpoints. Furthermore, the DSU understands that OAI-PMH feeds and IIIF Manifests both benefit from greater reliance on a single, authoritative URL. Finally, as the unit has been developing a system based on Islandora 2x and preparing for a migration, the timing seemed appropriate to revisit the potential of having a PID (Persistent IDentifier) URL system.
This article outlines the logic for adopting the Archival Resource Key (ARK) system and introduces the DSU’s application for minting, binding, resolving and tracking ARKs.
Selecting a Persistent Identifier
There are many excellent descriptions of the multiple systems provided for minting and maintaining PIDs. Leggott et al (2016) provides an overview of the major types and functions of persistent identifiers, and Barsky (2020) makes specific recommendations in the Canadian context. Koster (2020) provided a similar comparative overview of PIDs, and the Heritage PIDs project maintains a detailed chart of comparative features of PIDs (Kotarski, 2021).
DOIs, which use the Handle system, are readily recognizable in the academic context, particularly for published literature. According to DOI.org, eleven registries currently provide DOI services. Despite representing what could be argued as an industry standard, the fee structures for these services exceed both the DSU’s budget and mandate for unique identifiers. (See DataCite as an example of the fee structure of one such service.) The underlying Handle system is appealing with a nominal annual fee to maintain prefixes and register with a resolving agency. However, in the end, several features of the ARK system made it a better fit for the DSU.
Introducing ARKs
ARKs are similar to other systems, such as DOIs, in that they give users the ability to author and maintain a persistent URL for long-term access to an object. ARKs, introduced in 2001, appear to be associated most strongly with digitized collections, although the specification supports digital, physical, and conceptual objects of many types. An ARK URL consists of a domain name, the ARK label, and a Name Assigning Authority Number (NAAN), which can be registered for free. Under a NAAN, institutions can assign names, sub-parts and other variants to the ARK (See Figure 1). There are no fees for creating ARKs.
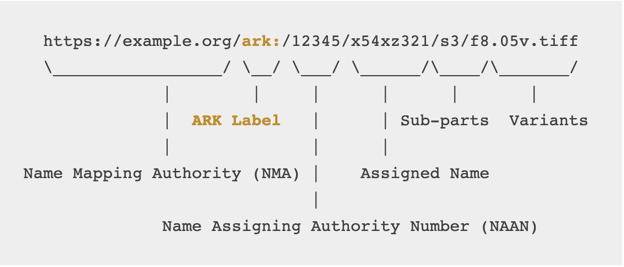
Figure 1. “A Peek at ARK anatomy” from https://arks.org/about/.
Although centralized services for resolving ARKs are available (via https://n2t.net/), they are not required. The ARK Alliance (the community maintaining ARKs) is supported by over 40 organizations and is a member of the National Digital Stewardship Alliance (ARKs.org, Community). The actively updated NAAN registry table currently contains over 900 institutions globally that have registered to assign ARKs. For the DSU, perhaps the most attractive features of the ARK system relate to metadata management.
ARKs and Metadata Management
“ARKs should be created at object birth, or even before. We sometimes name our babies before they’re born, and we name and refer to objects in the conception stages, sometimes long before they bear fruit.” (ARK Implementation Best Practices)
Of particular interest in the ARK system is the support for ‘early object creation.’ Every digital object that is gestated in the Digital Scholarship Unit spends some time period in development and enrichment stages, often among many staff and stakeholder groups, and generally involving spreadsheet-based workflows that are well supported by ARKs. ARKs are minted and then can be appended to a metadata record at any stage of the object development process. In the Islandora 2x system, the application Islandora Workbench supports direct, spreadsheet-based metadata ingest and update. Drupal’s views and other serialization tools then allow for flexible exporting of object information, making roundtrips for metadata straightforward. As objects go through stages of description, reformatting, quality assurance, and publication, they bring their ARK with them. In the past, the DSU has minted local Identifiers or used identifiers from associated systems (such as identifiers from archives) to serve this purpose. However, these systems are inconsistent, and the resulting identifier rarely serves a clear purpose as part of the final metadata record. By forming part of a URL that can be directed and redirected to other online locations, the flexibility of ARKs supports collaborative work on object creation and maintenance. To implement ARKs with the metadata manager in mind, the DSU developed the ARKs-Service application.
ARKs-Service Application
Introduction and Setup
The ARKs Service is a PHP standalone application with a user interface based on the Noid4PHP by Daniel Berthereau. This package is a PHP solution for the popular Perl-based Noid project written by John Kunze. Furthermore, this application adapts the work of Akio Sensei who has integrated a MySQL database into Noid4PHP, improving its performance. Running the playbook will set up a web application with a public website that simplifies the process of minting, binding, and resolving ARK URLs by providing both a UI and templates for common ARK tasks. The locations to which ARKs point can be changed in the application, and the number of redirects performed by the application is tracked in the application database. The DSU believes this advances a potential turnkey solution for ARK management, particularly for smaller software development teams. This application supports both the older and emerging ARK standards.
The application provides a public website and a back-end interface (in the DSU environment, the back end is protected by a firewall). The public site contains the resolver that will direct an ARK URL user to the digital object referenced. (see Figure 2).
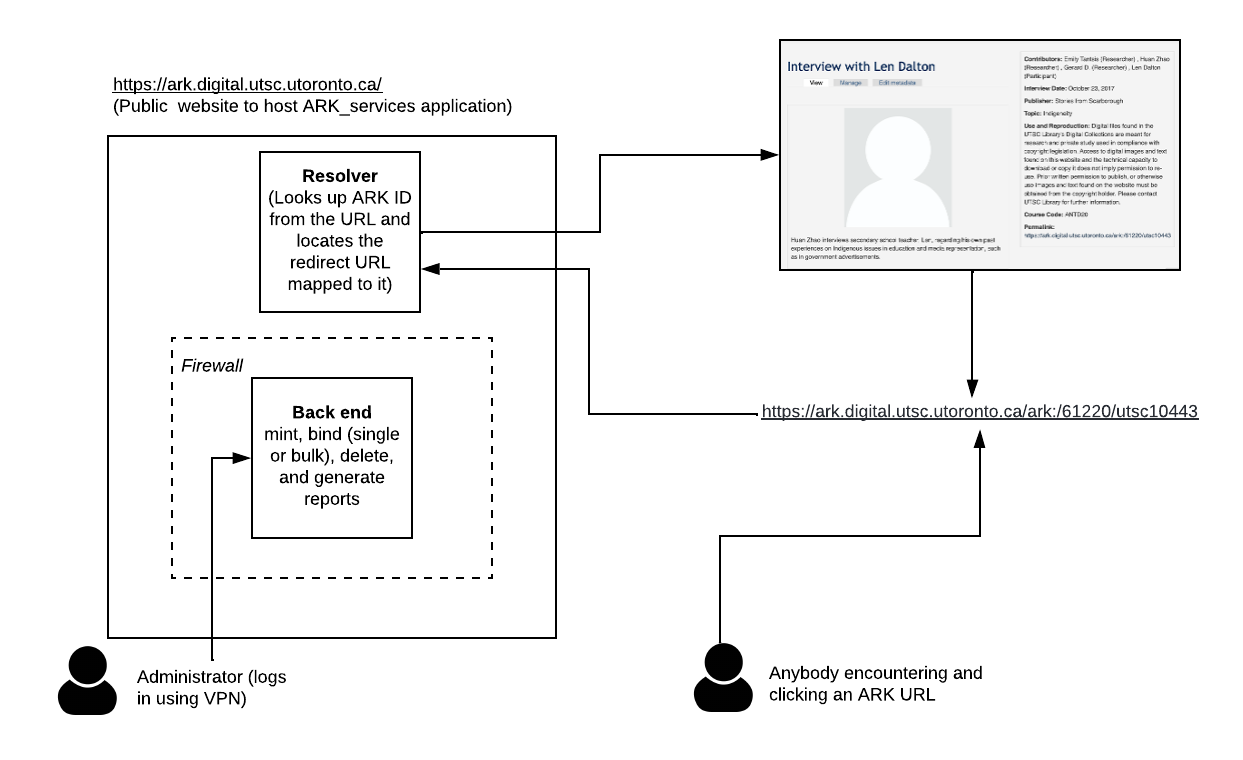
Figure 2. Systems overview of ARKs-Service deployment.
After installing this application successfully, users will be prompted with the initial step of setting up an Organization’s name and URL as well as System Administration credentials (see Figure 3).

Figure 3. Launch page after installation.
Creating (“Minting”) ARKs
After setup, a user can log in using these credentials in a browser and create a database to hold a ‘collection’ of ARKs (see Figure 4). After naming a collection, a user is asked to select a template. These templates define the way that ARKs are generated by the system. For example, if a user would like to mint ARKs that have a “sequential 4-mixed-digit numbers with constant prefix of ‘sdd’” they would select the template called “sdd.sdede.” If a user would like the ARKs to be a “random 3-digit numbers, stopping after 1000th,” they would select the template .rddd. More information about the various available templates and their characteristics are available in the NOID documentation. The DSU is using a single sequential series of ARKs for most of its collections; the ”.zd” template is used because it provides sequential numbers without limit. The “prefix” is a substring for the ID that must be unique if the user intends to host multiple ARK databases.
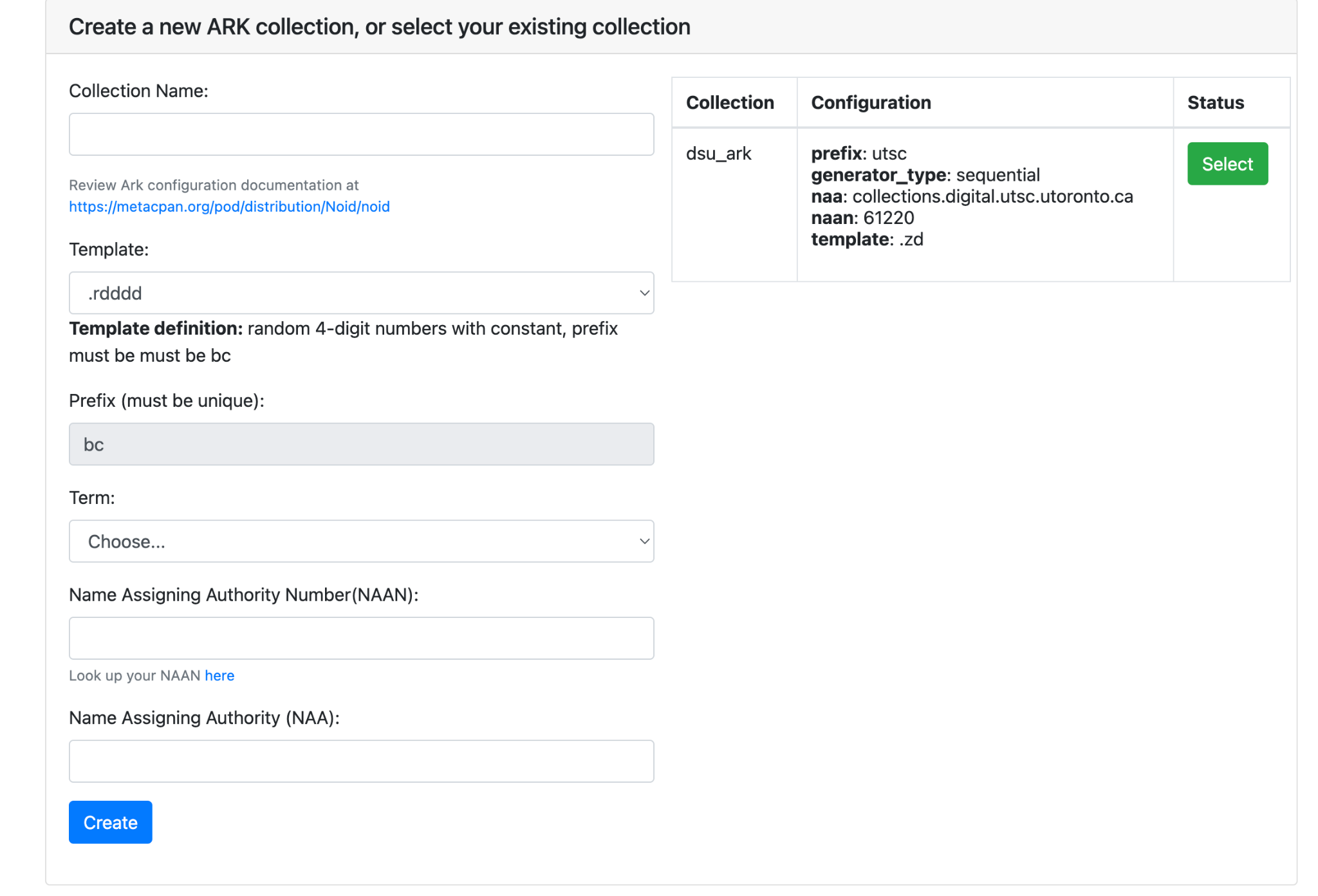
Figure 4. Creating a collection of ARKs.
Once the ARK collection has been created, new affordances are available for a spreadsheet-based process of minting, binding, and updating ARK IDs.
As depicted in Figure 5, end users can choose to create or “mint” a number of ARK IDs, based on the schema selected on setup. The user enters a number of ARKs (for example 100) and then these are created in the database. They can then be downloaded in .csv format, which can be opened by Excel and other spreadsheet programs.
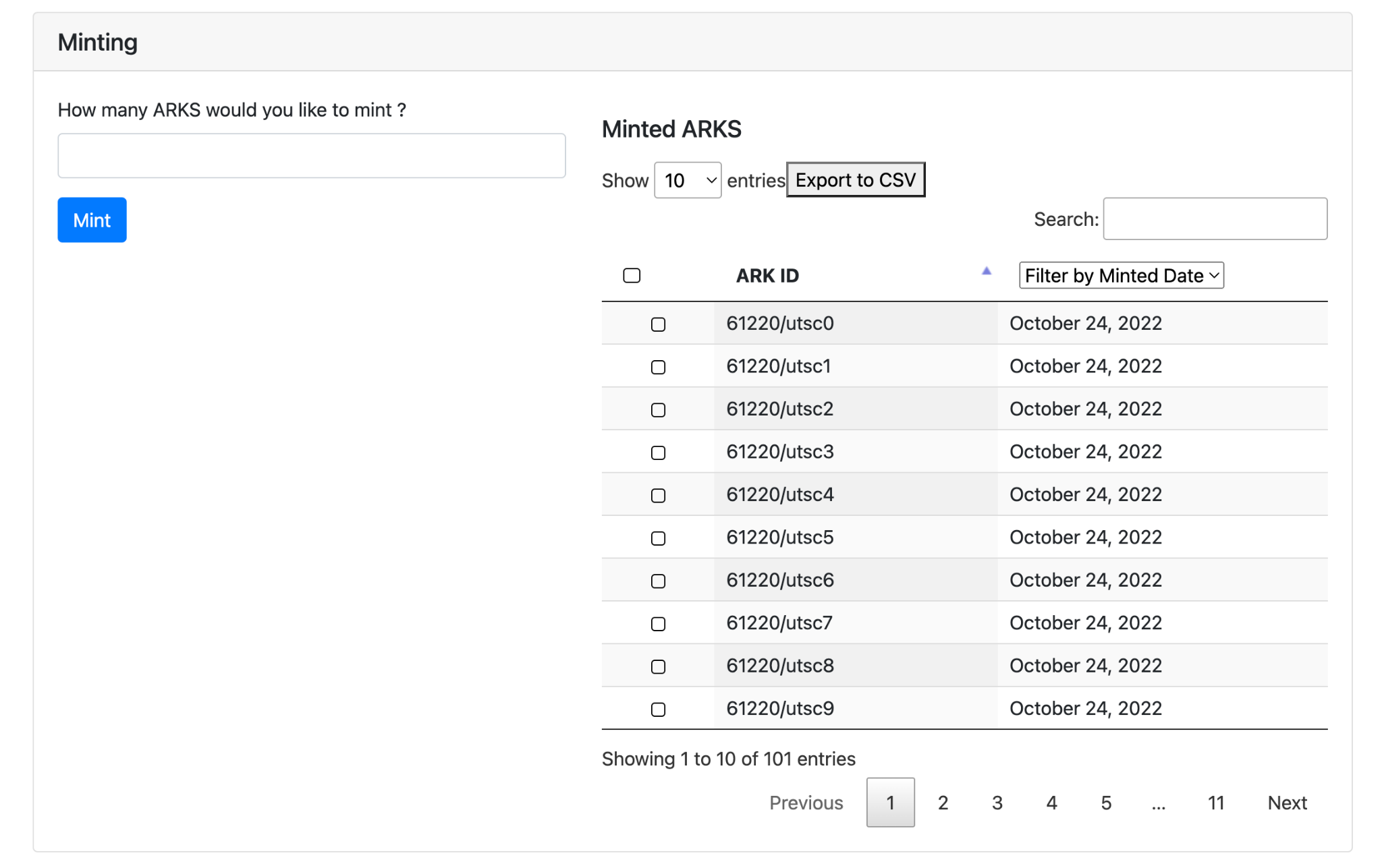
Figure 5. Minting ARKs.
Metadata and URL (“Binding”) ARKs
Once ARKs have been minted, they can be associated with their library-managed location (i.e., the URL of the object in the digital repository), as well as any additional metadata using another spreadsheet (.csv file). The application provides a template to download, where additional columns can be added for specific fields. Only the URL field is strictly mandatory, although other fields are recommended. Any number of additional metadata fields can be added to the ARK. Figure 6 shows the two screens available for bulk binding, although binding can be done at the level of a single object via the interface.
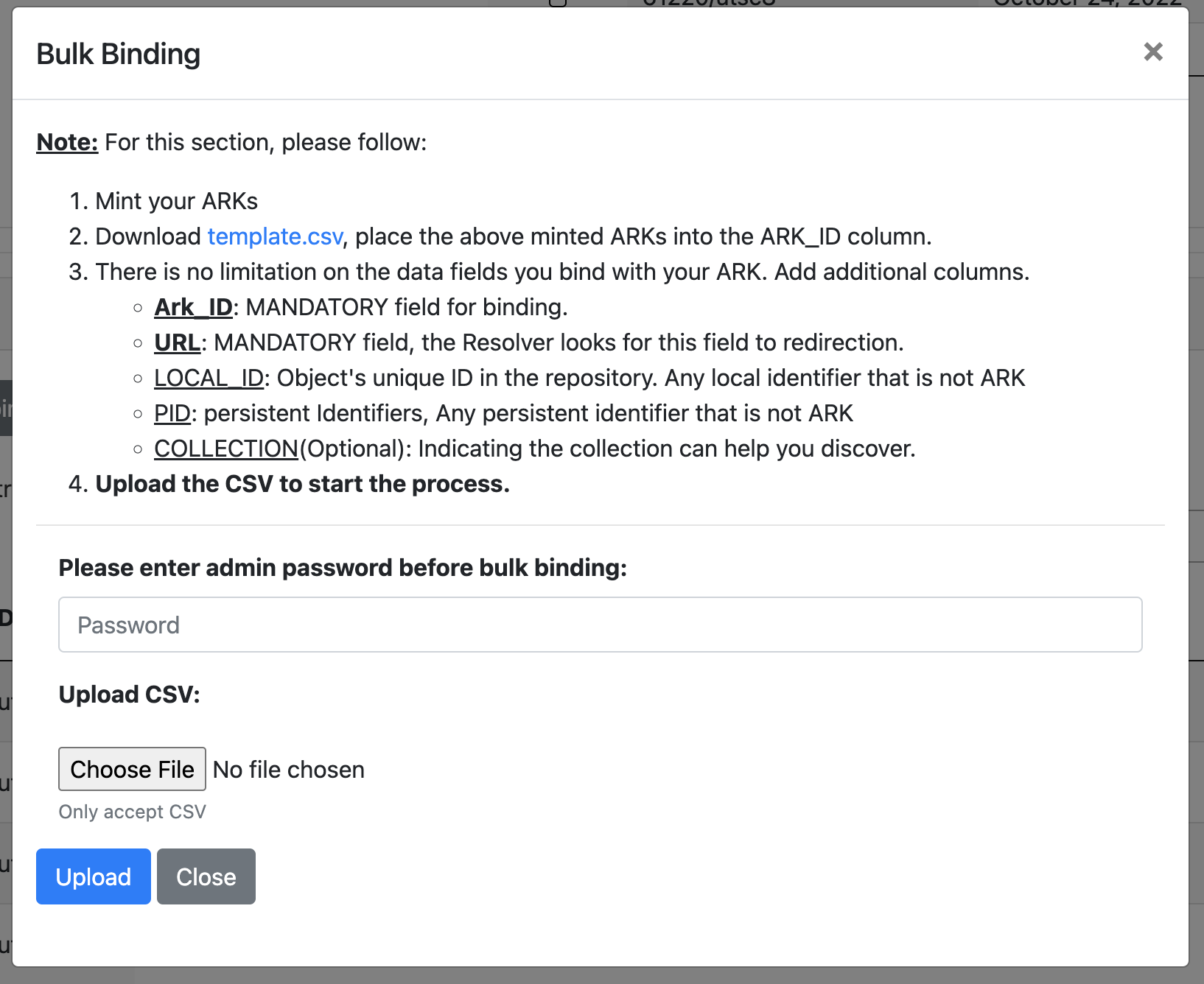
Figure 6a. Bulk binding ARKs screen 1.
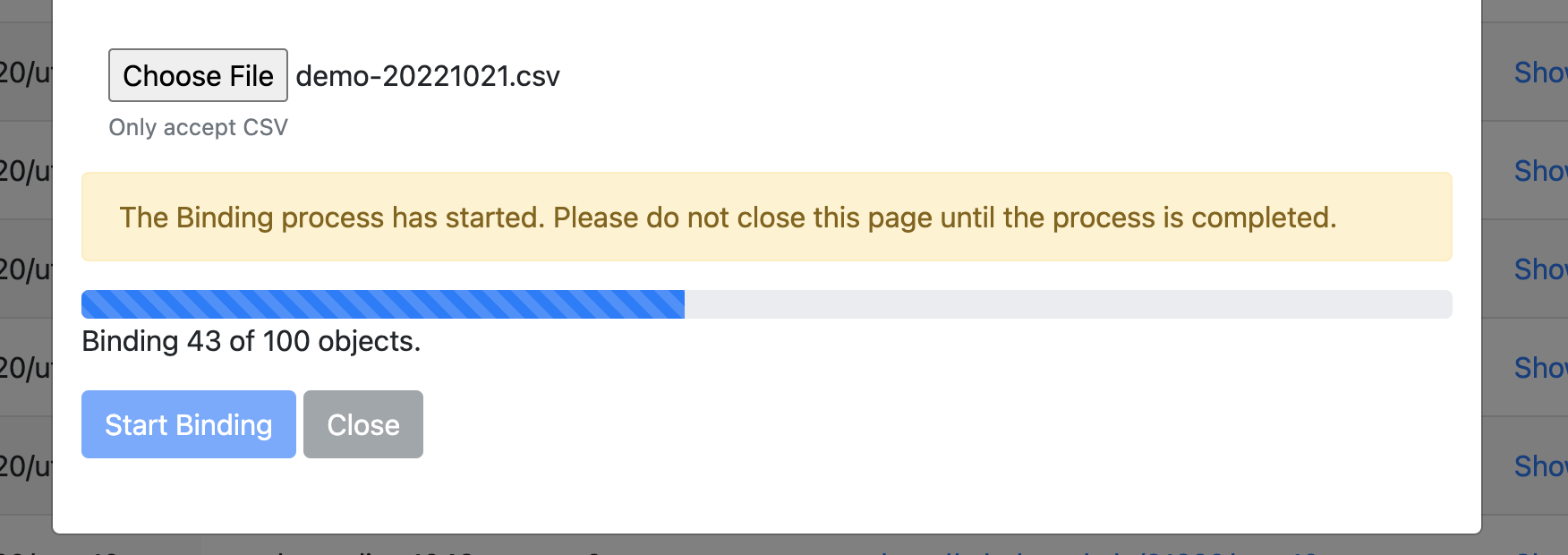
Figure 6b. Bulk binding ARKs screen 2.
These bindings and all associated metadata can also be updated in bulk or individually (which is useful for content migrations, as described below). Once a URL is bound, the ARK URL will take a user directly to the digital object (as depicted above in Figure 2). Appending single and double question marks to the ARK URL will also display a metadata panel with all of the previously bound metadata fields (see Figure 7, which shows a minimal metadata record brought back by appending a question mark to the end of the ARK URL).

Figure 7. bringing back bound metadata using the ARK URL.
Note that the metadata here is not sufficient for the ARK standard, but is provided here as an example of this affordance in the application. Metadata enrichment will be part of the work undertaken in the DSU upcoming data migration, particularly developing a persistence statement (a vocabulary is suggested in Kunze, 2017) and adjusting the application to provide this on request.
Reporting features for ARK IDs
At any point, a list of ARKs and their corresponding data can be exported from the system for review. An overview of the screen for this is provided in Figure 8 – Reporting for ARKs. An end user can search for individual records using the metadata and export the existing mappings. The system also records the number of times an ARK redirect URL gets used, enabling a user to see which ARKs are in use (in column ‘Number of Redirects’).
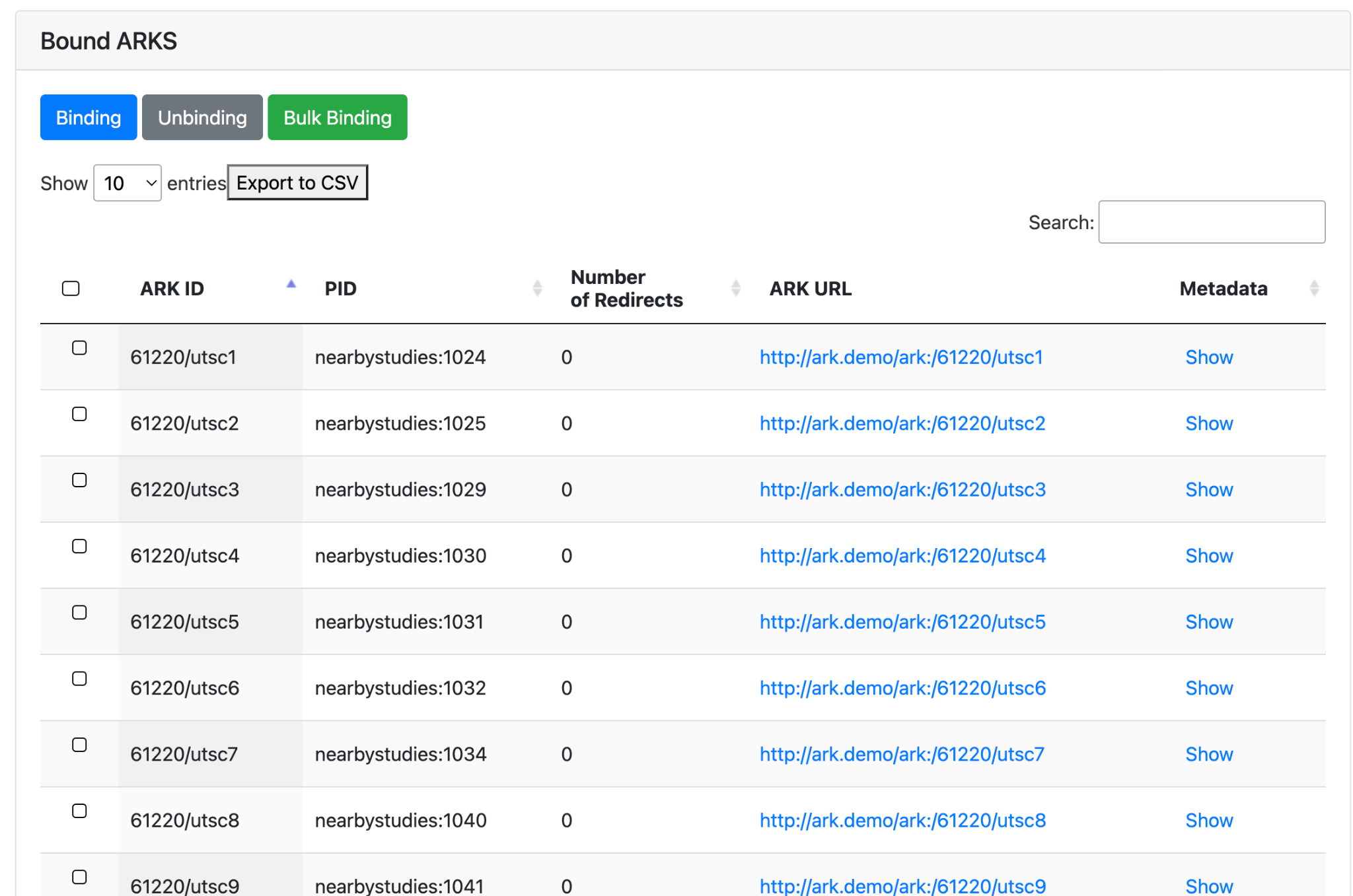
Figure 8. Reporting for ARKs.
The full suite of interface features and REST API documentation, as well as explanatory videos, is available in the Github wiki for the project. Edits and pull requests are welcome.
Persistent Identifiers in Islandora
In Islandora Legacy (Islandora 7), Fedora 3x provides a persistent identifier (PID) under a specific namespace, accessible as a specific part of the object URL. In the DSU system, where multiple individual Drupal sites are serviced by the same underlying Fedora, this often leads to varied URLs. For example, the following two URLs lead to the same object.
- https://gundagunde.digital.utsc.utoronto.ca/islandora/object/gundagunde:17492
- https://collections.digital.utsc.utoronto.ca/islandora/object/gundagunde:17492
This approach also requires maintaining multiple subdomains (both gundagunde and collections), when either might change. The Islandora provided PID (in the example above, gundagunde:17492) could uniquely identify the object in both cases but was not guaranteed to be universally unique. The unit also encountered challenges with the level of semantic meaning associated with the first part of the PID (the PID namespace, in this case, “gundagunde”) which stakeholders would request to change. Adopting a more opaque naming strategy going forward is a priority in the unit.
In Islandora 2x, the ARK ID, stored in the metadata of the object (a Drupal entity), can form the backbone of a URL alias authored automatically by the Drupal system (see: PathAuto). Node aliases that use ARK IDs mask the underlying Drupal “node ID” with something more persistent and unique. Associating the ARK ID with the digital object via a Drupal entity allows the system to use it in other system contexts. Figure 9 depicts a sample of the new ‘permalink’ in the Islandora 2x system, printed under the object but also available in features like citation generation.

Figure 9. Permalink in the new Islandora interface.
Conclusions
There are multiple excellent systems and technical strategies for providing persistent identifiers and URLs for digital objects. In the UTSC Library Digital Scholarship unit, the ARK system was found to be the most flexible, least resource-intensive method for minting, binding, and resolving persistent URLs. Although the migration to Islandora 2x is not yet complete, the ARK system is already being used in multiple contexts in the existing Islandora Legacy system. Persistent URLs provide a measure of confidence to end users when citing objects in other contexts and will provide continuity during the system migration. The DSU’s ARKs-service application builds on well-developed open-source software already existing in the community to provide additional flexibility and user interface affordances for authoring and managing ARK identifiers. The DSU hopes that this work will advance the ecosystem of lightweight, affordable, flexible open source tools for persistent identifier creation and management.
Works Cited
Alliance, The ARK. (2021, January 26). ARK implementation best practices. ARK Alliance. Retrieved June 28, 2022, from https://arks.org/about/best-practices/
Alliance, The ARK. (2022, February 23). Community. ARK Alliance. Retrieved June 28, 2022, from https://arks.org/community/
Barsky, E. (2020, December 3). Persistent Identifiers in Canada?: White Paper [R]. doi:http://dx.doi.org/10.14288/1.0395014
Jordan, Mark. Islandora Workbench (2022), GitHub Repository, https://github.com/mjordan/islandora_workbench
Koster, Lukas (2020) Issue 47 Code4lib journal 20202-02-17 Retrieved from https://journal.code4lib.org/articles/14978
Kotarski, Rachael, Kirby, Jack, Madden, Frances, Mitchell, Lorna, Padfield, Joseph, Page, Roderic, Palmer, Richard, & Woodburn, Matt. (2021). Developing Identifiers for Heritage Collections (v2.0). Zenodo. https://doi.org/10.5281/zenodo.5205757
Kunze, J. (2003). Towards electronic persistence using ARK identifiers. Retrieved from https://n2t.net/e/Towards_Electronic_Persistence_Using_ARK_Identifiers.pdf
Kunze, J., & Rodgers, R. (2008). The ARK Identifier Scheme. UC Office of the President: California Digital Library. Retrieved from https://escholarship.org/uc/item/9p9863nc
Kunze, J., Calvert, S., DeBarry, J.D., Hanlon, M., Janée, G. and Sweat, S., 2017. Persistence Statements: Describing Digital Stickiness. Data Science Journal, 16, p.39. DOI: http://doi.org/10.5334/dsj-2017-039
Leggott, Mark, Shearer, Kathleen, Ridsdale, Chantel, Barsky, Eugene, & Baker, David. (2016). Unique Identifiers: Current Landscape and Future Trends. Zenodo. https://doi.org/10.5281/zenodo.557106
Pathauto. Drupal.org. (2022, April 24). Retrieved June 28, 2022, from https://www.drupal.org/project/pathauto
Team, D. C. (n.d.). Fee model 2022. DataCite. Retrieved June 28, 2022, from https://datacite.org/feemodel.htm
Acknowledgments
The authors would like to acknowledge John Kunze’s help in editing this post-print version of the article. Note that further updates to documentation will be maintained in our GitHub organization.
About the Authors
Kyle Huynh is a software engineer at the University of Toronto Scarborough Library’s Digital Scholarship Unit.
Natkeeran Ledchumykanthan is a software engineer at the University of Toronto Scarborough Library’s Digital Scholarship Unit and a committer with the Islandora 2.x project.
Kirsta Stapelfeldt is a librarian and the Head of the Digital Scholarship Unit at the University of Toronto Scarborough Library
Irfan Rahman is a systems administrator at the University of Toronto Scarborough Library’s Digital Scholarship Unit

Subscribe to comments: For this article | For all articles
Leave a Reply