by Gregory Wiedeman
Introduction
Archives are weird.
Or at least that seems to be the perception of many library technologists. While archives are often part of larger research libraries, archival methodologies are often misunderstood by our administrator, technologist, and librarian peers. This confusion has become more problematic as archives continue to need and develop more complex access systems to make description, digitized materials, and born-digital objects available over the web. Implementing these systems requires cross-domain partnerships, and the misunderstandings and miscommunications around archival description in particular have severely hindered the development of discovery and access systems for archives.
Archives access systems do not work like library catalogs or really anything else on the web and currently have major usability barriers. To those who work mostly with the bibliographic description used by libraries and most of the web, it can be unclear why archives cannot just use the same systems, or why archives systems and practices just seem so limiting for users. Archival methodology and its reasoning can be easily obscured among the more esoteric traditions of archives, like the celebration of famous men to demonstrate value to donors, Hollinger boxes, or finding aids. It is often hard to differentiate between the value and the dogma.
Archivists themselves often find it hard to articulate why their needs are just different than their librarian peers. It can be challenging even for many archival practitioners to acquire strong expertise in archival description. In the United States, archival training is a concentration within a library credential, which can mean merely one or two archives-specific courses. You might only get one single class that discusses archival description, and even that is often taught by a faculty member with a research focus rather than extensive practitioner experience. Archival description skills often need to be learned on-the-job and seem to be mostly effectively passed on through peer groups, mentorship, or other types of informal professional development that not everyone has access to. Even archivists that do have strong knowledge of archival description may not have a detailed understanding of how web applications or other technologies are designed or work in practice. While many archivists see firsthand the constant friction in current access systems, they often struggle to articulate how they can be designed better as web applications. The divide in domain knowledge between discovery systems and archival description is a challenging one to bridge.
I hope to clarify the core differences between archival and bibliographic description and outline a path towards more effective discovery systems. While bibliographic description is much more intuitive and commonplace in our web applications, archival methods free us to apply the valuable descriptive labor that is the main bottleneck in our digitization and born-digital acquisitions programs more thoughtfully and appropriately.[1] If used properly, archival description could enable us to better provide digitization services on user request at scale and make these materials available online for future users. The extensibility of archival metadata also makes it a perfect fit for using automated description, such as optical character recognition (OCR), entity extraction, or automated transcription to enhance discovery, as it combines imprecise output with human-created records. I try to make it much clearer why archival metadata makes discovery so peculiar, highlight the cases where it can be advantageous, outline a path forward to increase the usability of archives access systems, and make the case for privileging archival description when planning and designing discovery systems.
The misunderstandings around archival description have hidden an enormous problem: there are no available off-the-shelf systems that provide access to digital materials using archival description. Every digital repository, Digital Asset Management System (DAMS) or Institutional Repository (IR) uses bibliographic description as an unrecognized design assumption. To illustrate this, I provide a case study of UAlbany’s existing Hyrax and Arclight implementations which use archival description for discovery by linking data from these systems over APIs. This approach works functionally but has substantial usability and maintenance issues. In working to combine these systems into a single archives discovery system, I wrote a custom indexer that adds digital materials, full-text OCR and extracted text content to Arclight as a proof-of-concept example that I hope can illustrate a path forward towards designing access systems that work directly with archival methods. Finally, I will point to some ways we can experiment with how archival inheritance is indexed to potentially mimic bibliographic usability.
Archival vs. Bibliographic Description
By bibliographic description, I mean the creation of individual metadata records for each object with a set of descriptive fields. This has been the intuitive method of managing information going back beyond our relevant professional history. I’m sure you could go back thousands of years and find library workers creating some kind of discrete bibliographic record describing an individual item. Library catalog cards and Online Public Access Catalogs (OPACs) are canonical examples of bibliographic description. Each record has a set of descriptive fields and is self-contained – all of the available information is contained within the record. Dublin Core states this explicitly in its “one-to-one principle,” where it declares that each discrete entity “should be described by conceptually distinct descriptions.”[2] While Linked Data adds some complexity by potentially breaking up records into statements, data structures and descriptive practices usually remain the same. Most of the information on the web is displayed to users in a way that looks like bibliographic description. A search engine, a major e-commerce site, or Wikipedia will display records of objects to users that contain all the available information. These records often link to other records, but each record still describes an isolated object and is fully comprehensible by itself. The ubiquity of this format proves its intuitiveness and usability. I am sure that this is to some degree an oversimplified caricature of bibliographic practices, but it is a useful contrast to help us to better understand the impact of archival description.
While archives may appear to be just a specialized type of library, they have a fundamentally different methodology for managing and providing access to materials. Why did early archivists reinvent the wheel and develop incompatible practices that are less intuitive for both professionals and users? The answer is very practical: they simply had too much stuff. The early development of archival description in the United States illustrates how usability was a conscious and necessary tradeoff to be able to adequately manage the scale of records that were working with.
The American National Archives was first created in the 1930s and, since the government had been functioning and creating records for over 150 years, records had been previously managed by individual departments and offices, often with a variety of different methods and techniques. By 1941 archivists had accessioned 302,114 cubic feet of records from seventy-two different agencies.[3] These early American archivists actually wanted to use bibliographic methods to make all these records easily accessible in familiar ways. They made multiple attempts to use various forms of card catalogs to describe materials and established a Classification Division devoted to somehow providing subject-based discovery. However, “…given the diverse mass of materials in the National Archives, classification demanded vastly more time and expense than the agency could afford,” and the division was disbanded in 1941.[4] With truck after truck moving more and more records to the archives, all archivists were able to feasibly do was document the source of records and their existing arrangement. The provenance of each set of records was important because each source had a different arrangement system and discovery process. A user would have to use the “preliminary inventories” created by the archivists to find what office created the records they were seeking, and how that office arranged or maintained them to navigate that file series or records component.[5] These “preliminary inventories” evolved into paper and online finding aids over time.[6]
Of course, it would be simpler for users if all the records had a single discovery process, but to early American archivists, that was obviously (if regretfully) infeasible. Usability was a conscious trade off to make the enormous volume of materials even somewhat accessible. As a rule of thumb, the approaches used by archivists are useful primarily because of the scale of the materials they manage. Got a large but manageable amount of stuff? Use bibliographic description. Got a seemingly never-ending vast mountain of materials? Use archival description. This is an oversimplification, as archival methods are also very good at retaining context of materials, but scale alone is a useful distinction to show how archival systems are meaningfully different.[7] The reality is that in our current unlimited information environment, archives and libraries have larger collecting scopes and volumes of materials than they have descriptive resources, much like the early National Archives. Even with the additional catalogers and archivists that should be hired to address this, archival methods should be reassessed in order to make the line between the available and the inaccessible more gradual, and to make a larger body of materials open for use.
Archival Description in Practice
Most of our librarian and technologist peers understand that archival data is structured differently, as archival data is hierarchical, with a tree structure of “components,” such as collections, file series, folders, and perhaps items. However, the way archival description inherits is not widely understood and has really important implications for system design. Even archivists do not often articulate how the relationships between components of description work.
For example, a repository might hold a folder called “Meeting Minutes, 1989 July 26.” This component only has a title and a date, which alone are not very helpful to users. Who was meeting? What were they discussing? Unlike a bibliographic record, not all of the available information is contained within the record and the relationships to other records are very meaningful. In this example, the file is part of a series titled “New Jersey Proportionality Review Project Records,” which is part of a collection titled the “Leigh B. Bienen Papers.” Both higher order components have fields where a user might learn the purpose of the meeting and its potential participants and outcomes.

Image 1. The file is part of a series titled “New Jersey Proportionality Review Project Records,” which is part of a collection titled the “Leigh B. Bienen Papers.” https://archives.albany.edu/description/catalog/apap312aspace_c264f5e1f93f9d58e5b60483c32d76e9
Here is where we have to get into the weeds a bit. At all levels, components may use twenty-five elements that are described in the archives content standard, Describing Archives: A Content Standard (DACS). Eleven of these elements are required fields. The standard also outlines a set of Requirements for Multilevel Descriptions that articulates rules for the relationships between multilevel archival components like the above example. This section of DACS is particularly impactful, but it is challenging for non-experts to fully appreciate its meaning. What is not often understood here is that, while most of the eleven required elements are often only used at the collection level in practice, each component is required to be described by every one of these fields. Even the above “Meeting Minutes, 1989 July 26” example needs to have a Name of Creator(s), a scope and content note, an access conditions note, etc. This example is actually described by those elements, they are just stored outside of the record in higher order components. Lower-level components only use DACS elements if they supersede or are more granular than the higher order component. If this is not the case, the element from the higher-level component applies. Thus, the Scope and Content element from the New Jersey Proportionality Review Project Records series component and several elements from the Leigh B. Bienen Papers collection component also describe the “Meeting Minutes” file component. When archival repositories used paper finding aids, inherited elements were implicitly displayed using front matter, indents, and other design features that conveyed this relationship, but our current discovery systems do not account for this.
Archival description also provides us with a tremendous amount of flexibility, allowing for the discovery of full text, bibliographic records, and description automatically derived from digital materials within a single descriptive schema and discovery system. DACS allows archivists to use bibliographic metadata, such as Dublin Core fields, to further describe materials when there is a user-driven reason to do so. It just requires a clear and explicit relationship between these records and the archival component that describes them. This allows archivists to create high-quality descriptive records when appropriate. An archival collection can easily contain one series of lower-value or rarely used materials that are only generally described by the series description, and another series of high valued items containing high quality detailed metadata for each item that you would expect in a library catalog. Instead of allocating a similar amount of descriptive labor to all materials as bibliographic description often does, archival description empowers archivists to use their appraisal skills and spend their valuable time in proportion to the value of materials they are working with. For rarely used items with less value, materials can still be accessible, just with a higher usability cost.[8]
Because archival methodology accommodates lower quality descriptive records, this also makes it a perfect fit for automated approaches that derive description from digital materials. This includes full text, technical metadata, or the output of computational techniques such as entities extracted using Natural Language Processing (NLP). Archival description is also a perfect fit for using emerging machine learning techniques for extracting meaningful information from digital images and documents for discovery if these tools can be used without causing harm. There have been some experiments that have used automated approaches to describe special collections materials. However, no matter how sophisticated, automated methods alone produce lower-quality records that limit discoverability and usability in bibliographic systems.[9] In archival description, these records would always be linked with higher-level metadata created by a human professional. The flexibility of archival description also makes it easy to manually enhance automated description when needed. For lower value materials that would not receive detailed description, automated description can also be better than nothing. Archivists are also welcome to use automated description at first while assessing its use and potentially enhancing the description later as appropriate. Yet, as I’ll discuss later, while archival description encourages these practices, the current systems available for managing digital materials are designed only to work with bibliographic description, thus they are blocking the use of automated approaches in practice.
Archival methods do have significant drawbacks. This is an idealized vision of archival description. Systems that support the creation of quality archival description are a relatively new phenomenon and a lack of training and support can mean that archival methods are sometimes inconsistently mixed with bibliographic approaches, or just poorly applied. Additionally, even if we design discovery systems that make use of archival description, there is a usability cost that may be unavoidable when we compare it to the simplicity of bibliographic description. When you compare catalog cards to finding aids or OPACs to ArchivesSpace, bibliographic description is often more familiar and comfortable for most users. The usability problems of online finding aids and archives access systems are very well-documented.[10] The more complex relationships in archival data are simply just more challenging to navigate and display intuitively. Yet, there are paths forward if we design digital repositories to match the affordances of archival description, then we may be able to improve the usability of discovery systems to where the advantages are well worth the costs to users.
The Current Landscape of Digital Repositories
When we apply a strong understanding of archival description to the current landscape of digital repositories, we see that there are several digital repositories available, but no system allows for the discovery of digital material using archival description. This is true across both open source and proprietary systems. Using archival methods for discovery is simply not currently possible without substantial customization. Most repositories are designed as Digital Asset Management Systems (DAMS) like ContentDM for the upload and discovery of digital objects or designed as Institutional Repositories (IRs) like Islandora, Samvera-based applications, or Bepress Digital Commons that have built-in multi-user submission workflows. Every single one of these systems is designed with bibliographic description in mind. Each assumes that librarians or archivists will enter a set of descriptive metadata fields when uploading digital objects. Each tool also envisions itself as a self-contained system for this description. No complete off-the-shelf system expects description to be managed and made discoverable outside of its interface.
Remember that if an item is described by an archival component, DACS requires a clear and explicit relationship between that item and its higher-level components so that users can use those inherited descriptive fields, and it is reasonable for a user to expect at least a navigable link here. A common workflow is for archivists to digitize an item that is already described by an archival component, but since all DAMS and IRs assume they are self-contained, the archivist then has to spend additional time and labor to create a separate set of Dublin Core or other bibliographic elements for a digital repository. This both duplicates effort and creates an obvious usability barrier. Users often must navigate both a system for archival description and a separate system for digital content. This problem is particularly acute for small repositories, as to make digital content available, they are incentivised to change their local descriptive practices to match the system used by whatever consortial repository is available to them.
It is probably correct to say that none of the current tools, including ContentDM, Islandora, DSpace, Bepress Digital Commons, or Samvera-based systems like Hyrax or Hyku, are compliant with DACS. Archivists have no options. This is a major use case that is simply not being met with available tools, likely because of the divide in domain knowledge between archivists and administrators, librarians, and technologists. There is no off-the-shelf product that provides access and discovery for digital materials using archival repositories’ existing description methods and systems.
Over the last decade or so, there has been a lot of progress in designing and developing systems to manage archival description, with the development of ArchivesSpace being a major success. However, ArchivesSpace, Access to Memory (AToM), and Arclight all only manage and/or provide access to description, not digital content. While these tools all help provide us with an important piece to the access puzzle, users want to access materials, not just descriptive records. In-person research will always be a key part of archival repositories, but more and more archival research is being done primarily or solely online, with the COVID-19 pandemic possibly being a major turning point. The closure of reading rooms finally forced many archives to regularly accommodate digitization requests on-demand. This is a major advancement in user services, yet many of these materials are often sent directly to users and not uploaded into digital repositories for future use. This is because these systems are not able to accommodate items without additional descriptive labor, despite them already having archival description and the fact that they were already discovered by a user.[11]
Archival repositories need systems that manage digital content to do less – focus on asset management, file serving, and interoperability. Archivists are already able to create and manage complex archival description in tools like ArchivesSpace or AToM. Archives need digital repositories to manage digital content but be interoperable with and rely on their existing description systems. The International Image Interoperability Framework (IIIF) is a great way to make these connections. There are some important roles that repositories should take on, such as processing or ingest workflows and technical metadata, but digital repositories as currently constituted cannot serve as the primary end-user discovery system for archival materials. It also could be advantageous to designate digital repositories and discovery systems as separate concerns, as repositories can better serve as a “back-end” systems that may better provide or are more interoperable with preservation functions. In the future this may help us avoid design problems like the Samvera architecture, which too tightly coupled preservation and access functionality though ActiveFedora.[12] This separation may also make it easier for systems to manage access restrictions, as archivists need to manage and preserve digital materials that cannot currently be made publicly available, as “Virtual Reading Rooms” or limited or controlled access systems are another important piece of the access puzzle.[13] But most importantly, separating discovery from asset management may also provide us with the space and flexibility to design access systems that allow end-users to discover and navigate that content using archival description.
UAlbany Case Study
A case study of the Espy Papers from UAlbany illustrates both the potential for using archival description to manage digital objects, particularly by enabling digitization on demand, as well as the practical challenges that arose attempting this with current systems. M. Watt Espy spent most of his life documenting capital punishment in the United States. He dug up information for every death row inmate he could find from corrections records, county histories, court proceedings, and popular publications, and summarized each case on index cards – colorfully documenting victims, alleged perpetrators, and circumstances. At his height he had a large network of collaborators that sent him documentation sourced from all over the country. This collection represented the most complete documentation of executions in what is now the United States dating back to European colonization. In 1984 the National Science Foundation (NSF) awarded a grant to the University of Alabama to create a computational dataset based on the materials, which was first released as Executions in the United States, 1608-1987: The ESPY File. On Espy’s death, the original source materials along with other papers were donated to UAlbany’s National Death Penalty Archive and in 2010 it received detailed folder-level processing with funding from the National Historical Publications and Records Commission (NHPRC).[15]
While the ESPY File dataset became a canonical source for criminal justice researchers, abstracting the stories of these thousands of individuals onto a spreadsheet took away a lot of meaning and serviced only certain types of research. Some researchers had found issues with the dataset and reference staff had heard a number of anecdotes from users about discrepancies they found between the index cards and the ESPY File data. Seeing so many users willing to travel to see the index cards, along with the potential of leveraging the existing metadata from the dataset made it a strong candidate for digitization and in 2016, UAlbany was awarded a Council on Library and Information Resources (CLIR) Hidden Collections grant to digitize two file series and make them openly available online.[16]
Since the collection had previously received detailed folder-level processing and the materials were the source for an existing dataset, it seemed wasteful and duplicative to create additional item-level records with bibliographic metadata for what would be about 125,000 digital objects. The ESPY File dataset was not created as descriptive metadata to our current standards and did not map to the paper materials in a machine-actionable way, so it was not useful as a drop-in replacement for bibliographic metadata in a DAMS. Thus, the collection seemed like an excellent candidate for using existing archival description to provide access to the digital scans, as it could make practical use of the problematic ESPY File data.
Our existing systems provided no way to use the existing description to provide discovery and access to digital scans. We had recently completed migrating our archival description to ArchivesSpace and were using eXtensible Text Framework (XTF) and the LUNA DAMS for access, but neither XTF or LUNA were interoperable or sustainably customizable and no digital repository was available that used archival description for discovery out-of-the-box. The ArchivesSpace REST API provided the potential to use archival description in new ways, and we were eager to fully leverage our descriptive labor already dedicated to the collection to benefit users and make our work more impactful. We decided to implement an open-source digital repository that would be more customizable to use folder-level description from ArchivesSpace along with the ESPY File dataset. For much of the source materials series, we thought that the quality folder-level description already existed should be sufficient to provide access. Also, if we could implement a successful process for using existing archival description for digitization, we hoped that we could do the same for other collections, and potentially even provide digitization services on request for single folders without having to create detailed bibliographic metadata.
We decided to implement a lightly customized Hyrax repository which uses the Samvera framework. Hyrax is not a “turnkey” system, but a fully featured set of open components that can be implemented into a digital repository. We hoped the openness of Hyrax would make it easily adaptable to our existing archival description. Over the course of the project, the Arclight MVP project made Arclight into a viable option for providing access to archival description. Because it uses a similar Ruby on Rails stack as Hyrax, it became easier to implement Arclight and integrate it with Hyrax than doing a similar level of customization with the ArchivesSpace Public User Interface (PUI). We needed data to be passed both ways, from Hyrax to Arclight and from Arclight to Hyrax, and both systems exposed JSON metadata with REST APIs, which was an invaluable feature we could not have done without. Since both systems used the same technology, much of what we learned customizing one system could also be applied towards the other.
We did not quite know what we were getting into. The project was significantly under-resourced in both outside funding and internal expertise. However, despite some delays, data problems, and the challenges of learning new technologies, the systems we implemented were a major success. The Espy Project Execution Records website provides open access and discovery to the Espy Papers. Our University Libraries also gained a lot of skills and capacity to implement and host open-source applications that would be applicable to other projects, we developed a more productive relationship with the university-level Information Technology Services division, and we are better able to utilize our on-campus virtualized data center. The need to support these systems was successfully used in 2019 to justify filling a vacant technologist position that otherwise was not likely to have received university-level approval. The project enabled us to use existing archival description for digitized and born-digital items and allowed us to provide online access to a much greater volume of materials.
On the Hyrax side, we had to develop multiple custom data models to handle both legacy materials from our existing DAMS as well as objects that would rely only on a link to a component of archival description. It was relatively straightforward to create Image and AV models to handle the schemas used in our existing DAMS, but Hyrax’s use of linked data URIs was a barrier to creating a sensible digital archival object (DAO) model for archival description.[17] To make connections between digital objects and components of archival description, we used the 32-character ref_id generated by ArchivesSpace and indexed into Arclight. Each folder-level component would have a ref_id for itself, could have multiple ref_ids for higher level series and subseries components, and always had a collection identifier for the top-level collection. We thus needed three identifier fields, one containing multiple IDs where the order mattered, and each having a separate meaning. It also made sense to store the name of each component in the model as a string. This was challenging to model using linked data URIs since Hyrax requires a unique URI for each field. Once we got a set of URIs that Hyrax accepted, we essentially ignored the URIs downstream and relied on local meanings for the fields. I am skeptical that even a perfectly designed or customized ontology would have provided any value to this project, and trying to use any form of the Records in Context (RiC-O) ontology currently being designed by the International Council on Archives Experts Group on Archival Description (ICA EGAD) would have been a nightmare.[18]
Once the DAO model was complete, we customized the workflow page where an archivist would upload and describe a digital object. This worker would enter the ref_id for the component of archival description, the collection identifier, and click a “Load Record” button. This button would make a JavaScript AJAX call to the Arclight JSON API and automatically fill most of the descriptive fields. The worker would then only be required to add a resource type and a license or rights statement before uploading the object.
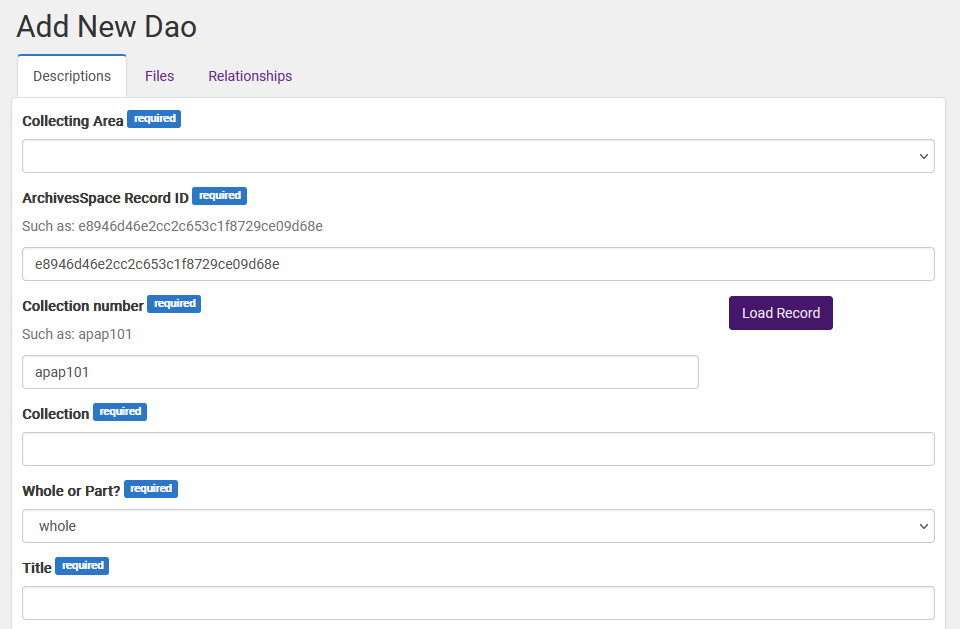
Image 2. DAO Model.
We also customized the display page for each object to pull relevant archival description from Arclight also using client-side JavaScript calls. When an object page loads, it uses the ref_id and collection identifier to query the archival description component and all of its parent components. The page then displays the names and links for all higher-level components as any Scope and Content notes. The use of client-side AJAX calls is imperfect but allowed us to integrate the two systems without much more complex customization within the Rails applications.
If a worker was digitizing an item, they would just have to find the ref_id and collection number for the folder in ArchivesSpace or Arclight, and enter those fields in Hyrax with a resource type and rights statement. For descriptive metadata Hyrax would then only contain a title (example: Skandalon, Vol. 3, No. 9) and date (example: 1965 March 10), which by itself would not be very helpful to users. When a user accesses the item, Hyrax will query and display Scope and Content notes for the Skandalon and the University Publications Collection. A user could then read that this is a single issue from a bi-weekly journal of news and opinion published by Campus Christian Council, which was part of an artificial collection of student publications.
This minimal descriptive workflow, along with rapid lower-quality scanning allowed for digitization on user request. We later implemented a new Digital Reproduction Fee Schedule that charged by the time required for digitization rather than page counts.[19] Since we were using existing archival description for metadata and avoiding page count estimates with back-and-forth emails, in many cases we were able to digitize an item in about the same time as a traditional reference request and make requests that take under 30 minutes free to users. This practice improved user experience, allowed us to digitize a much larger volume of materials and make them accessible online, and has the added benefit of making our digitization labor more transparent to users. In this example, I received a request for one issue and digitized the whole run of 42 issues in an afternoon merely because I had some extra time and thought the materials were interesting and worth digitizing.
In addition digitizing individual items on request, we also developed a batch upload workflow for large sets of items sent to an outside vendor for digitization. The process relied mostly on spreadsheets. Here we also used existing archival description so the materials did not require item-level bibliographic metadata. This proved to be really useful for university publications, for example, where we had existing volume and issue lists. We had an existing tool for exporting this metadata from the ArchivesSpace API, so we added on a process where an archivist could paste in the corresponding access file for each issue and a script would generate another spreadsheet that could be uploaded into Hyrax using a rake task. This workflow enabled us to rapidly digitize large collections or file series that were really valuable for reference use, such as student newspapers, university publications, commencement programs, university organizational charts, press releases, and university senate legislation. While additional descriptive care would have improved discoverability as always, making these materials discoverable using existing archival description plus full text OCR and extracted text was a major advancement.
While our Arclight and Hyrax implementations were very successful in providing access to digital materials using archival description, they also have a number of practical limitations. The most obvious problem is that users still must navigate two separate systems, one for archival description and another for digital materials. We implemented a “bento” style discovery layer based on QuickSearch to make search results from both ArcLight and Hyrax available from a single search box but found that users still had trouble navigating back and forth between the two systems.[20] A redesign in early 2022 based on the Duke University Arclight implementation addressed some minor issues with this integration, but the core problem remains.[21]
Additionally, getting data from Hyrax back into Arclight is challenging. It was easy to modify Arclight templates to point to Hyrax for digital materials, but once an archivist uploaded a new object into Hyrax, that URI had to be added to a new ArchivesSpace Digital Object record. We were also storing separate preservation copies for each object outside of Hyrax so we needed to download the object, store it as a local Archival Information Package (AIP), and add an identifier that references the AIP into Hyrax. Since Hyrax does not provide an API for this, we were only able to automate this using a very wonky script that queries the Hyrax Solr index, adds a new Digital Object in ArchivesSpace, schedules it to be indexed to Arclight, downloads and stores the object as an AIP and adds the identifier to Hyrax by literally scraping the Hyrax login and edit pages and POSTing data to the edit form using the Python requests module. It worked, but it was a hack.
This process along with overall support for Hyrax creates major sustainability risks. Our Library Systems department has struggled to maintain Hyrax without anyone with a strong Ruby or Rails background on staff. Major cuts to library staff in 2020-2022 only minimally impacted applications support, but with overall library staff reduced by about 30% due to unfilled retirements, our long-term support for customized applications should be questioned, particularly when we are adapting systems like Hyrax and not using them quite as they are intended. Overall, there is a need for this setup to be simplified.
A Discovery System Designed for Archival Description
Archivists need a discovery system for digital materials that uses archival description. A true archival discovery system would query archival description along with item-level bibliographic metadata and automated description derived from digital materials, such as extracted text, OCR text, and A/V transcripts in a single search interface. Arclight has the potential to be this system. Currently Arclight is an access system for archival description based on Blacklight. It does not manage digital assets but returns individual components of archival description and lets users navigate through connected records. Since Arclight merely displays data indexed in Solr just like Blacklight, it also has the potential to display and return search results for digital objects, including full text.
description_indexer is an experimental tool that overrides the default Arclight indexing pipeline. Out-of-the-box, Arclight uses Traject to index archival description from EAD-XML files, often exported from ArchivesSpace. While Traject is set up to be easily configurable to select which XPath to use for each Solr field, it is not easily customizable to add the significant logic needed to index archival description or data from other sources. Instead, description_indexer is a Python library that uses ArchivesSnake and PySolr to index archival description directly from the ArchivesSpace API. This approach is potentially very useful for individual repository instances but may be less so for consortial aggregators because of the high permissions levels currently needed to access the ArchivesSpace API. description_indexer contains two very basic JSON data models, one for archival description and another for the Arclight Solr index. This extra layer of abstraction is useful, as any data source that can map to the archival description model would then be automatically indexable into Arclight. The archival description model is very much a draft and is likely too simple to be comprehensive, but community consensus around a model like this is key to consistently representing digital materials in the Arclight index.
The description_indexer main branch is set up to be a “drop-in” replacement for the current Traject indexer. The dao-indexing branch is designed to be a more experimental branch that flexibly indexes from digital repositories or other systems that manage digital assets. It is designed to be extensible, since individual implementations will likely need to index asset data from a number of different sources, you can write your own plugin-in to index digital assets from your local system. Once description_indexer is installed, you can add a custom class in a .py file in your home directory or using an environment variable that will allow for local logic to override how digital objects are indexed. The UAlbany example that is included queries JSON from our Hyrax instance to index links to content and other item-level data not managed in ArchivesSpace. description_indexer also contains multiple “extractors” for pulling content from digital files using Apache Tika and/or Tesseract, however running these during indexing is a challenge and a better design would be to extract and store this data while processing digital files and make it available to the indexer via a file system or a REST service. Here is also where there is the potential to experiment with new tools for extracting useful information from documents for discovery using NLP or models generated with machine learning. The data pipeline to the indexer needs further consensus and standardization.
In writing description_indexer, I discovered that digital objects, files, and file versions are under-theorized in archival description and archivists need to better define these objects and their relationships. The Portland Common Data Model (PCDM) provides helpful definitions of objects and files, and should be incorporated as much as possible, but the relationships between objects and archival components in lieu of PCDM collections is ill-defined and current practice is inconsistent.[22] ArchivesSpace attaches Digital Objects to archival components, but allows component attributes such as subjects and note fields to be attached to Digital Objects as well. Digital Objects also do not have href or URL attributes but contain File Versions which have File URI attributes. Both Digital Objects and File Versions also have is_representative Boolean attributes that are likely useful for Digital Objects. Overall, it should be clearer that Digital Objects are an abstraction that do not necessarily correspond to a file, and Digital Objects should probably have a field for an International Image Interoperability Framework (IIIF) manifest, as that also can be an abstraction and should be the preferred method of linking archival description to digital materials. Attributes for how files and versions are displayed in the absence of a IIIF manifests are also likely necessary, and overall, it was challenging to model this and broader and more complex community use cases are needed.[23]
The biggest barriers to enabling the discovery of digital materials in Arclight are establishing consensus data models and data pipelines. Once content from digital materials is indexed into an Arclight Solr index, we can display those objects in Arclight with only some minor customizations and a IIIF-compliant image server. I implemented a simple demonstration application that illustrates what this could look like in practice. This system returns results based both on archival description and full-text content extracted from digital objects. This implementation has data and design limitations, but I hope that this can be a useful model that shows the potential for what Arclight can be going forward.
Privileging Archival Description in Discovery Systems
Academic libraries and other cultural heritage institutions also manage digital objects using bibliographic description. To avoid implementing and maintaining multiple discovery systems, archival materials are often forced into off-the-shelf IRs and DAMS designed for bibliographic description. A better understanding of archival description shows that it is actually more appropriate to do the reverse, and index bibliographic records into systems designed for archival materials. Here, it might be helpful to see archival description as an organizational schema for managing materials which have many different organizational schemas. In the same way that the early National Archives used archival description to manage different descriptive methods used by different government agencies, archival systems can also accommodate bibliographic metadata that provides more usable and familiar access. This provides the best of both worlds. We can have one discovery system that provides both a strong user experience for higher value materials while still providing some level of access for materials that do not receive wide interest and otherwise would not receive detailed descriptive care.
This also works from a purely technical perspective. While it is possible to model archival description in digital repositories like Hyrax, the more complex structure of archival data makes this very challenging. It is comparably much simpler to model bibliographic metadata into archival systems than the reverse. With well-defined data models, we can easily add bibliographic metadata to an Arclight index, just like with a Blacklight instance. These records could stand alone or also be linked to archival description. This provides Arclight with the potential to unify bibliographic and archival metadata in a single user environment, offering the usability of detailed records with the extensibility of archival hierarchy. This would provide us with the full potential of archival description to flexibly allocate our descriptive labor based on the value of materials and user needs. Navigating complex archival data structures for items with lesser value may still be challenging for users. If we can make decisions based on the value of materials, rather than systems limitations, this should actually be an effective allocation of our limited descriptive resources.
There are also additional opportunities to improve the usability of archival description. Since Arclight is just an extension of Blacklight, it presents description to users in search results as discrete units much like bibliographic metadata. What we can do is experiment with how archival tree structures are indexed to better match how DACS envisions inheritance. Since DACS expects notes that are usually only applied at collection or series levels—like Scope and Content or Historical notes—to apply to lower-level components as well, we can experiment with indexing these notes as part of lower-level components too and just return them with lower relevancy scores. Arclight currently indexes parent access and use notes like this but does not use them to return search results. This has the potential to return better results for minimally-described materials, but would need to be part of an iterative usability testing process so that results are weighted appropriately. These are exciting possibilities, but we cannot do usability testing on archival discovery systems until they exist.
Conclusion
Archival description takes a very different approach to description than what is commonly used elsewhere – whether that be in library catalogs, digital repositories, or on the web. Archival methodology has key strengths that make it very useful for managing the vast quantity of digital materials held by libraries and avoiding a digital divide in an era where pandemics and the emissions costs of travel may limit in-person research. Our descriptive labor, no matter how extensive it is or should be, has limits. If academic libraries continue to prioritize bibliographic approaches to metadata and apply the same level of descriptive care to objects one by one regardless of value, there will always be a hard line between what is accessible and what is not. Archival description provides flexibility that empowers us to apply that valuable descriptive care based on the needs of users and prepares us to experiment with automated metadata approaches and iterative workflows. Archival methods simply more accurately and appropriately model our descriptive resources to our materials.
Unfortunately, it is currently very challenging to use archival description to manage and provide access to digital materials, as current digital repositories are not designed to work with archival description. Archivists manage description for materials in systems like ArchivesSpace that are designed for archival description, but DAMS and similar digital repository systems expect them to create additional bibliographic metadata for any digital material they manage, whether that is an appropriate use of resources or not. There is usually no easy way to link that metadata from two different systems together. In practice, this means that lower-valued items or the increasing number of items digitized by archives on user request are not made available or discoverable for future users because they do not have the value needed to receive detailed bibliographic description. This is silly considering archival description already exists for them.
Since archives data structures can accommodate bibliographic metadata, but the reverse is very challenging, discovery systems design must privilege archival description. Currently, there is no easy way to integrate archival description from systems like ArchivesSpace with digital materials managed in digital repositories into a single discovery point for users. UAlbany’s approach of using a “bento” style discovery layer on top of these two systems works functionally but has substantial usability limitations and sustainability concerns.
The misunderstandings around archival description have marginalized archival systems in academic libraries. Because our digital access systems never have worked for archival methods, libraries long took shortcuts by establishing whole separate programs to manage unique digital materials and limiting archives and special collections to a very traditional understanding of their collecting scopes. Instead of working with archives, libraries often worked around them – often causing needless duplication in metadata work, digitization, asset management, and digital preservation across different reporting structures.
Arclight has the potential to unify discovery of archival and bibliographic description and provide a single discovery point for physical and digital materials that allows archivists to fully leverage the affordances of archival description. We need further community consensus on a data model for archival description – most notably for digital objects, files, and file versions. I hope description_indexer can be a helpful example that can be iterated upon, that further work can be done to index digital materials in the Arclight index, and that we can experiment more with indexing archival description in general. While not really discussed here, archival description’s focus on agents and functions behind the creation of records has the potential for opening new patterns for discovery.[24] Overall, we need examples of digital materials in Arclight alongside archival and bibliographic description for iterative usability testing.
About the Author
Gregory Wiedeman is the university archivist at the University at Albany, SUNY where he helps ensure long-term access to the school’s public records. He manages the University Archives and supports born-digital collecting, web archives, and systems implementation for the department’s outside collecting areas. He currently serves as co-chair of the Technical Subcommittee for Describing Archives: A Content Standard (TS-DACS).
Endnotes
[1] Joyce Chapman, Kinza Masood, Chrissy Rissmeyer, Dan Zelner, “Digitization Cost Calculator Raw Data,” Digital Library Federation (DLF) Assessment Interest Group (2015). https://dashboard.diglib.org/data/. Amanda J. Wilson, “Toward Releasing the Metadata Bottleneck: A Baseline Evaluation of Contributor-supplied Metadata,” Library Resources & Technical Services Vol. 51, No. 1 (2007). https://journals.ala.org/index.php/lrts/article/view/5384/6604.
[2] “DCMI: One-to-One Principle,” Dublin Core Metadata Innovation. https://web.archive.org/web/20220627093857/https://www.dublincore.org/resources/glossary/one-to-one_principle/
[3] McCoy states that “…the National Archives had to deal with the greatest volume of records in the world; the unparalleled diversity of their origins, arrangement, and types; and their widely scattered locations in 1935.” Donald R. McCoy, The National Archives: America’s Ministry of Documents 1934-1968 (Chapel Hill, NC: The University of North Carolina Press, 1978), 45, 69.
[4] McCoy, 78-80. Philip M. Hamer, “Finding Mediums in the National Archives: An Appraisal of Six Years’ Experience,” The American Archivist, Vol. 5, No. 2 (1942): 86-87.
[5] The National Archives, Guide to the Material in The National Archives (Washington, DC: United States Government Printing Office, 1940), ix.
[6] This process is discussed in more depth in Gregory Wiedeman, “The Historical Hazards of Finding Aids,” The American Archivist, Vol. 82, No. 2 (2019): 381-420. https://doi.org/10.17723/aarc-82-02-20.
[7] In addition to working well at scale, archival description is also more effective at maintaining contextual relationships between records, their creators, and the activities that created them. This is further discussed in Jodi Allison-Bunnell, Maureen Cresci Callahan, Gretchen Gueguen, John Kunze, Krystyna K. Matusiak, and Gregory Wiedeman, “Lost Without Context: Representing Relationships between Archival Materials in the Digital Environment,” The Lighting the Way Handbook: Case Studies, Guidelines, and Emergent Futures for Archival Discovery and Delivery, eds. M.A. Matienzo and Dinah Handel (Stanford, CA: Stanford University Libraries, 2021). https://doi.org/10.25740/gg453cv6438.
[8] This practice is best described in Daniel A. Santamaria, Extensible Processing for Archives and Special Collections: Reducing Processing Backlogs (Chicago: Neal-Schuman, 2015). Shan C. Sutton also discusses the further extension of this to digitization in Shan C. Sutton, “Balancing Boutique-Level Quality and Large-Scale Production: The Impact of “More Product, Less Process” on Digitization in Archives and Special Collections,” RBM: A Journal of Rare Books, Manuscripts, and Cultural Heritage Vol. 13, No. 1 (2012). https://doi.org/10.5860/rbm.13.1.369.
[9] Paul Kelly, “Better Together: Improving the Lives of Metadata Creators with Natural Language Processing,” in Code4Lib Journal Issue 51 (June 14, 2021), https://journal.code4lib.org/articles/15946. Kaldeli, Eirini, Orfeas Menis-Mastromichalakis, Spyros Bekiaris, Maria Ralli, Vassilis Tzouvaras, Giorgos Stamou, and Evaggelos Spyrou, “CrowdHeritage: Crowdsourcing for Improving the Quality of Cultural Heritage Metadata,” Information Vol. 12, No. 2 (February 2021).
[10] Christopher J. Prom, “User Interactions with Electronic Finding Aids in a Controlled Setting,” American Archivist 67, no. 2 (2004): 234–68, https://doi.org/10.17723/aarc.67.2.7317671548328620. Anne J. Gilliland-Swetland, “Popularizing the Finding Aid: Exploiting EAD to Enhance Online Discovery and Retrieval in Archival Information Systems by Diverse User Groups,” Journal of Internet Cataloging 4, nos. 3–4 (2001): 199–225, https://doi.org/10.1300/J141v04n03_12. Luanne Freund and Elaine G. Toms, “Interacting with Archival Finding Aids,” Journal of the Association for Information Science and Technology 67, no. 4 (2016): 1007, https://doi.org/10.1002/asi.23436. Wendy Scheir, “First Entry: Report on a Qualitative Exploratory Study of Notice User Experience with Online Finding Aids,” Journal of Archival Organization 3, no. 4 (2005): 49–85, https://doi.org/10.1300/J201v03n04_04. Joyce Celeste Chapman, “Observing Users: An Empirical Analysis of User Interaction with Online Finding Aids,” Journal of Archival Organization 8 (2010): 4–30, https://doi.org/10.1080/15332748.2010.484361.
[11] James E. Murphy, Carla J. Lewis, Christena A. McKillop, and Marc Stoeckle, “Expanding digital academic library and archive services at the University of Calgary in response to the COVID-19 pandemic,” IFLA Journal Vol. 48, No. 1 (2021). https://doi.org/10.1177/03400352211023067. Florence Sloan, “Special Collections Practice in Response to the Challenges of COVID-19: Problems, Opportunities, and Future Implications for Digital Collections at the Louis Round Wilson Library at the University of North Carolina at Chapel Hill,” Masters Thesis, University of North Carolina at Chapel Hill School of Information and Library Science (April 30, 2021). https://cdr.lib.unc.edu/concern/masters_papers/1z40m3313. The infeasibility of creating item level records is also discussed in Stephanie Becker, Anne Kumer, and Naomi Langer, “Access is People: How Investing in Digital Collections Labor Improves Archival Discovery & Delivery,” The Lighting the Way Handbook: Case Studies, Guidelines, and Emergent Futures for Archival Discovery and Delivery, eds. M.A. Matienzo and Dinah Handel (Stanford, CA: Stanford University Libraries, 2021), 33. https://doi.org/10.25740/gg453cv6438.
[12] Esmé Cowles, “Valkyrie, Reimagining the Samvera Community,” https://library.princeton.edu/news/digital-collections/2018-06-05/valkyrie-reimagining-samvera-community.
[13] Elvia Arroyo-Ramírez, Annalise Berdini, Shelly Black, Greg Cram, Kathryn Gronsbell, Nick Krabbenhoeft, Kate Lynch, Genevieve Preston, and Heather Smedberg, “Speeding Towards Remote Access: Developing Shared
Recommendations for Virtual Reading Rooms,” The Lighting the Way Handbook: Case Studies, Guidelines, and Emergent Futures for Archival Discovery and Delivery, eds. M.A. Matienzo and Dinah Handel (Stanford, CA: Stanford University Libraries, 2021). https://doi.org/10.25740/gg453cv6438.
[14] M. Watt Espy, John Ortiz Smykla, Executions in the United States, 1608-2002: The ESPY File (ICPSR 8451), (Ann Arbor, MI: Inter-university Consortium for Political and Social Research (distributor), 2016-07-20). https://doi.org/10.3886/ICPSR08451.v5.
[15] M. Watt Espy Papers, 1730-2008. M.E. Grenander Department of Special Collections and Archives, University Libraries, University at Albany, State University of New York. https://archives.albany.edu/description/catalog/apap301. “Commission Recommends $7 Million In Grants,” The U.S. National Archives and Records Administration, 2010 June 1. https://web.archive.org/web/20220307211150/https://www.archives.gov/press/press-releases/2010/nr10-107.html.
[16] Blackman and McLaughlin summarize the widespread praise for Espy’s work, while also highlighting some of the ESPY File’s limitations and criticizing its use for quantitative analysis. Blackman and McLaughlin, “The Espy File on American Executions: User Beware,” Homicide Studies Vol. 15, No. 3 (2011): 209-227.
[17] Models for the UAlbany Hyrax instance. https://github.com/UAlbanyArchives/hyrax-UAlbany/tree/main/app/models.
[18] EGAD – Expert Group on Archival Description, “Records in Contexts – Ontology,” July 22, 2021. https://www.ica.org/en/records-in-contexts-ontology.
[19] “Request Items for Digitization,” M.E. Grenander Department of Special Collections & Archives, University at Albany, SUNY. https://archives.albany.edu/web/reproductions/.
[20] “QuickSearch,” North Carolina State University Libraries. https://www.lib.ncsu.edu/projects/quicksearch.
[21] Sean Aery, “ArcLight at the End of the Tunnel,” November 15th, 2019. https://blogs.library.duke.edu/bitstreams/2019/11/15/arclight-at-the-end-of-the-tunnel/.
[22] Portland Common Data Model (April 18, 2016), https://web.archive.org/web/20220912065008/https://pcdm.org/2016/04/18/models.
[23] description_indexer experimental archival description model, https://github.com/UAlbanyArchives/description_indexer/blob/dao-indexing/description_indexer/models/description.py.
[24] The Rockefeller Archive Center’s DIMES access system is a really interesting step in this direction by emphasizing agent records and requiring users to click through archival components to convey description inheritance. Renee Pappous, Hannah Sistrunk, and Darren Young, “Connecting on Principles: Building and Uncovering Relationships through a New Archival Discovery System,” The Lighting the Way Handbook: Case Studies, Guidelines, and Emergent Futures for Archival Discovery and Delivery, eds. M.A. Matienzo and Dinah Handel (Stanford, CA: Stanford University Libraries, 2021). The Records in Contexts – Conceptual Model (RiC-CM) also has a very intriguing focus on agents and functions for discovery that deserves further practical exploration. “Records in Contexts – Conceptual Model.” Expert Group on Archival Description (EGAD), https://web.archive.org/web/20221007020234/https://www.ica.org/en/records-in-contexts-conceptual-model.

Subscribe to comments: For this article | For all articles
Leave a Reply