by David W. Hodges and Kevin Schlottmann
Introduction
Migrations bring out the best and worst of library activities. Dedicated staff have invested years of practice and skill development around specific technologies, platforms, and software; and adapted to meet novel conditions and requirements. But after a while that CMS or software platform is looking long in the tooth. Or maybe its open-source maintainers have moved on to other things and there hasn’t been a new release in years. Or maybe each library unit has developed its own tools and workflows on separate paths. Then the time comes to bite the bullet and modernize. You may find that, while there may be resources out there for migrating from platform A to B, they don’t quite fit your particular flavor of A and/or B. Or they don’t take into account your special edge cases and cleverly devised workarounds. Improvisation is in your future, best-laid plans notwithstanding.
That’s all just to say, when it comes to tools and methods for migration, we often have to wing it. This was on our minds as Columbia University Libraries (CUL) embarked on a multi-phase project to migrate nearly 4,000 records describing over 70,000 linear feet of archival material from disparate sources and formats into ArchivesSpace. In the process, we committed to regularizing and remediating data while we had it in view—MARC records, accessions, and Encoded Archival Description (EAD) XML files created and updated over many decades by countless staff. Some problems were known, such as that collection metadata managed for years in parallel legacy systems diverged, sometimes significantly. But other issues with the data were unknown or could only be guessed. How were we to review so much data and make effective use of archivists’ time and effort? Which irregularities were isolated edge cases and which were project show-stoppers?
To address these concerns we looked at how to streamline the extraction and reporting of important data and devised new tools and workflows using Python, XSLT, and the Google Sheets API to:
- analyze the corpus,
- pipe custom reports of targeted data directly to shared Google Sheets for distributed review,
- and in turn use information in the sheets to guide data remediation at scale.
Many institutions make use of workflows involving tabular data structures and tools such as the pandas Python library or Open Refine to automate data cleanup (see e.g., Bartczak and Glendon 2017). However, the manual touch points of importing and exporting data to and from spreadsheets can prove burdensome and error-prone. We found the efficiencies gained by dispensing with transitory CSV (or Excel, OpenOffice) documents and routing data directly to and from the collaborative space of Google Sheets made the additional effort worthwhile. In the process, we developed a reusable tool set with wider applicability beyond the migration. In effect we found that Google Sheets could serve as an ad-hoc database—a versioned, cloud-hosted, reliable one at that—for Python-powered projects, with a flexible Web GUI as well. This paper describes the driving forces motivating this work at CUL, the tools and workflows created, and the work done across archival processing and technology units that helped make the migration successful.
Background
Columbia’s main archival repositories reside in the Rare Books and Manuscripts Library (RBML), Avery Art and Architectural Library, Starr East Asian Library, and the Burke Theological Seminary Library. The largest holdings by far are in RBML, which was also the first to explore archival management software (Archivists Toolkit, primarily to track accessions). In Phase 1 of our migration, we moved around 4,000 accessions from Archivists Toolkit along with a similar number of collection-level MARC records from our Voyager ILS into ArchivesSpace. This initial migration left us in a hybrid state, with collection-level catalog records managed in ArchivesSpace while finding aids remained for the time being in an eXist XML repository, authored manually by archivists in oXygen XML editor, and published by a durable but aging custom PHP-based Web application developed in 2008. The scripts and workflows around finding aids had served the organization well for many years, but the time for consolidation in ArchivesSpace had come [1].
This led us to Phase 2, the migration and integration of EAD finding aids into ArchivesSpace, and the retirement of the legacy Web application and associated workflows. This entailed not merely importing but rather merging of data at different levels of description in the platform. It was in this phase where the scope and scale of review and quality control (QC) called out for automated solutions and efficient reporting mechanisms.
Defining the Universe of Migration
A surprisingly difficult question to answer was what exactly we were migrating in this phase. We decided early on to focus on finding aids that were already in EAD 2002 XML, thus setting aside for later an assortment of ur-legacy content—scanned PDFs, static HTML finding aids, and such [2]. The legacy XML system, built on an eXist-db repository backend and an impressive array of associated scripts and tooling, was feature-rich but lacked data integrity safeguards. It had accumulated a large assortment of duplicate or orphaned content as well as “stub” records auto-generated from MARC with no component description. The eXist database held in the neighborhood of 7,300 records from six library repositories—clearly far more than we intended to migrate. De-duplicating and winnowing down this corpus to an authoritative data set was not a trivial task. We compiled an inventory of all XML data and, through some judicious sorting and filtering, were able to select a subset of records that (a) had component description (i.e., a non-empty element), (b) were currently (or soon to be) published as a finding aid, and (c) had a corresponding resource record in our newly operational ArchivesSpace. In this way, out of the thousands EAD files we defined our universe of migration to roughly 1,400 records.
Migration Strategy
Having selected the archival description to migrate, we examined a few different approaches to actually getting the data into ArchivesSpace. Since we had already imported collection-level records and linked them with accessions in Phase I, we couldn’t simply import the EAD records and overwrite collection-level information. Appending component description (the dsc section in EAD files) to existing resources would get us closer to the desired result, but we lacked a means to do this at scale; the Harvard Excel importer plugin, while excellent for single file processing, lacks (as of this writing) a batch import feature.We also had to handle divergent description that predated the migration (described in more detail below). Together with our hosting vendor Lyrasis, we settled on a hybrid approach:
- export the ArchivesSpace resource record as EAD;
- create a complete EAD from the best elements of the eXist EAD and the ArchivesSpace EAD;
- delete the ArchivesSpace record;
- import the completed hybrid EAD;
- relink accession, assessment, external document, and locally-defined fields directly in the database.
This approach took advantage of the in-house expertise at CUL across collection and digital libraries departments centered on archival description, EAD, Python, XSLT, and XQuery.
Divergent Description
In the old infrastructure, when a new collection-level record was first created in Voyager, a stub EAD was automatically spawned. From that point forward, the EAD and MARC records were no longer programmatically connected. Thus, as a consequence of separate cataloging workflows for MARC and EAD, inconsistent manual updating, and automated changes such as authority control to the MARC records in the ILS; individual fields of collection-level records diverged significantly in unpredictable ways over the last decade. For example, a biographical note might have been updated with a death date in the Voyager record but not in the EAD record or vice versa. That same biographical note might also have later been expanded considerably in the EAD by a project archivist, but was not brought into the ILS record due to field size limitations. Similarly, an expired restriction that was found and lifted programatically in the EAD record using eXist might not be reflected in the ILS record. The immediate issue for phase II migration was thus to identify whether each field in every one of 1,400 collection-level records was better in the EAD or in the MARC record. Our goal was to not lose descriptive data in the process and reconcile the differences. It was very clear that CUL archivists were best positioned to do the review, but we were unsure how to do so efficiently.
Workflow Overview
For the finding aid migration and remediation, we generally worked in an Extract-Transform-Load (ETL) model, exporting all data to local XML files and performing bulk and individual cleanup operations via XSLT [3]. A recurring task was to iterate over a batch of EAD files and report out selected data based on XPath expressions to tabular format. A typical way to do this is to use XSLT to generate a pipe-delimited text string for each file; a script (bash, Python, etc.) would read directory contents and feed files one-by-one to the stylesheet, and compose the output into CSV format for import into Excel, OpenOffice, or Google Sheets.
But what if we could skip a step and write the data directly to the spreadsheet in a user-friendly format? Enter the Google Sheets API, a great resource sitting right there in our organization’s Google Apps suite, little noticed. Use is relatively straightforward to anyone familiar with APIs and Google provides decent documentation along with sample snippets in several code languages to help users get started. After some preliminary setup and OAuth authorization, any Google spreadsheet with requisite permissions (i.e., with edit permissions granted to the API user via the document “Share” settings) can be addressed by script functions. A sheet then can be put to use as both a light-weight, versioned data store behind a Python (or other language) process as well as a versatile collaborative interface for data review and remediation.
To facilitate no-frills interaction with the API we abstracted some core functions into the lightweight Python module sheetFeeder that has proven very useful. Its functions can be imported in Python in the usual way:
from sheetFeeder import dataSheet
# Define a dataSheet instance
my_sheet = dataSheet('1YzM1GinagfoTUiAoA21PsPt8TkwTT9KlgQ','Sheet1!A:Z')
Its dataSheet class defines a target sheet (based on the stable ID in the URL) and provides a number of straightforward methods for interacting with a sheet, for example, reading a whole table into a list:
# Get some data the_data = my_sheet.getData() the_heads = the_data[0]
Selectively extracting data via pattern matching :
# return value of col 1 for any row where col 0 matches ID
the_matches_by_id = my_sheet.lookup('423451', 0, 1)
# return rows where ID and Title match patterns
my_matching_rows = my_sheet.matchingRows([['ID', '^123*'], ['Title', '.*papers.*']])
Or posting new data to sheet:
# Clear the sheet my_sheet.clear() # Append new data my_data = [['a','b','c'],['d','e','f']] my_sheet.appendData(my_data)
The sheetFeeder module provides pythonic shorthand code that was very useful for our project , but readers are also encouraged to explore the Google Sheets API for themselves and try coding against it using whatever framework is most convenient.
With our tooling in place, our new workflow thus took shape:
- EAD data extracted from two sources (legacy and phase-1 migrated ArchivesSpace) was parsed and pushed to a shared Google Sheet via Python and the Google Sheets API using
sheetFeeder; - a user-friendly presentation allowed archivists to perform QC review;
- the QC results were read by another Python process and fed into an XSLT pipeline for merging and cleanup;
- and finally, the results were imported back into ArchivesSpace and QC’d again there.
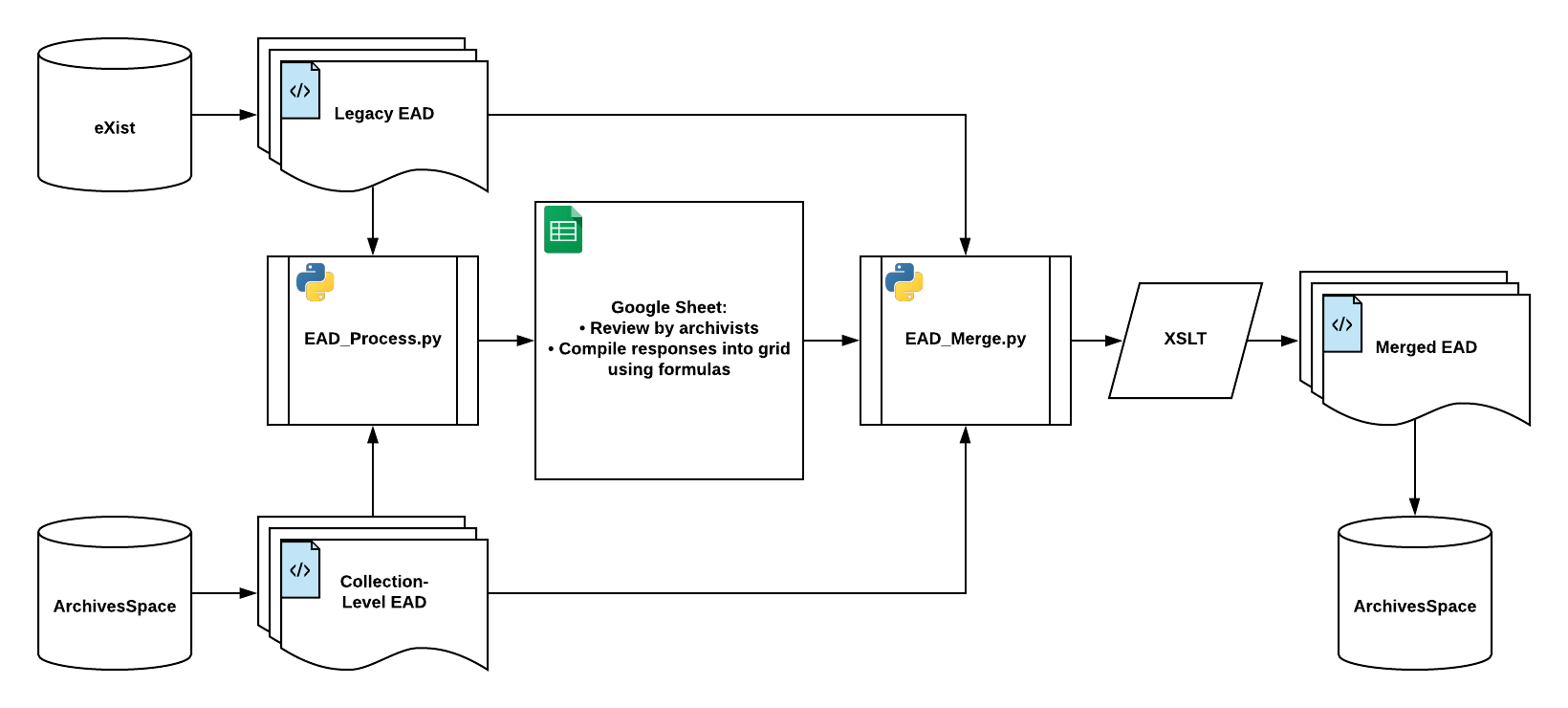
Figure 1.Workflow diagram.
Reading EAD Data Into a Sheet
Although its verbose syntax and ponderous matching mechanism can be daunting, XSLT is a great way to quickly and precisely grab a selected set of information from well-formed EAD XML files. We found that, since advanced XSLT 2.0 functions were not necessary for the extraction part of the process, we could use the native Python lxml library to apply XPath 1.0 expressions and forego calls to an external Saxon processor. Namespace support can be idiosyncratic with lxml, so the XPath expressions were more verbose than we would have liked, but still easily comprehensible, as is shown in a list of query strings in ead_process.py:
# Default namespace for CUL EADs
ns = {"ead": "urn:isbn:1-931666-22-9"}
[...]
# Dict of elements and their XPath.
asQs = {
"bibid": "ead:archdesc/ead:did/ead:unitid[1]/text()",
"repo": "ead:eadheader/ead:eadid[1]/@mainagencycode",
"title": "ead:archdesc/ead:did/ead:unittitle[1]/text()",
"status" : "ead:eadheader/@findaidstatus",
"revisiondesc": "ead:eadheader/ead:revisiondesc",
"altformavail": "ead:archdesc/ead:altformavail",
"accruals": "ead:archdesc/ead:accruals",
"accessrestrict": "ead:archdesc/ead:accessrestrict",
"userestrict": "ead:archdesc/ead:userestrict",
"acqinfo": "ead:archdesc/ead:acqinfo",
"arrangement": "ead:archdesc/ead:arrangement",
"bibliography": "ead:archdesc/ead:bibliography",
"bioghist": "ead:archdesc/ead:bioghist",
[...]
}
The script defines two file sources for each record: an EAD file of the legacy finding aid (exported from eXist) and a corresponding EAD file exported from ArchivesSpace. An obvious prerequisite was that there be two corresponding EAD files for each record (identified by the ILS’s unique bibliographic number, the bib ID for short) [4]. Since the data structure differed slightly in ArchivesSpace-flavored EAD than what we had used for years in our legacy system, XPath expressions were slightly different and needed to be stored in two parallel dictionaries.
Looping through each batch of files (first legacy, then ArchivesSpace export), the script parses and extracts data via the XPath expressions, composes them into a list, and in turn compiles each list as a row in a nested list. Once done iterating through the batch, the resulting data object is posted to the Sheets API via sheetFeeder to populate the target tabs (one for legacy, one for ArchivesSpace) in the spreadsheet. The result is two enormous tables of very unreadable data. However, this is where formulas in the spreadsheet take over!

Figure 2. Raw import of EAD elements into columns.
Data Interface
The desired workflow was for archivists to compare two versions of a single element (e.g., scopecontent, userestrict, etc.) for a record and determine which is authoritative (or more accurate, or just better). This was a binary choice—further textual refinement could happen later. To make a reasonable interface for this task, each element was broken out into a separate tab. For a given element (e.g., relatedmaterial), QUERY() functions pulled in single columns from each of the large data tables and place them side by side for review. A column allowed archivists to indicate which to migrate for each record. Work was distributed to a number of staff to work concurrently on different tabs and record sets according to their domain expertise. Queries could be added as comments for review and resolution.
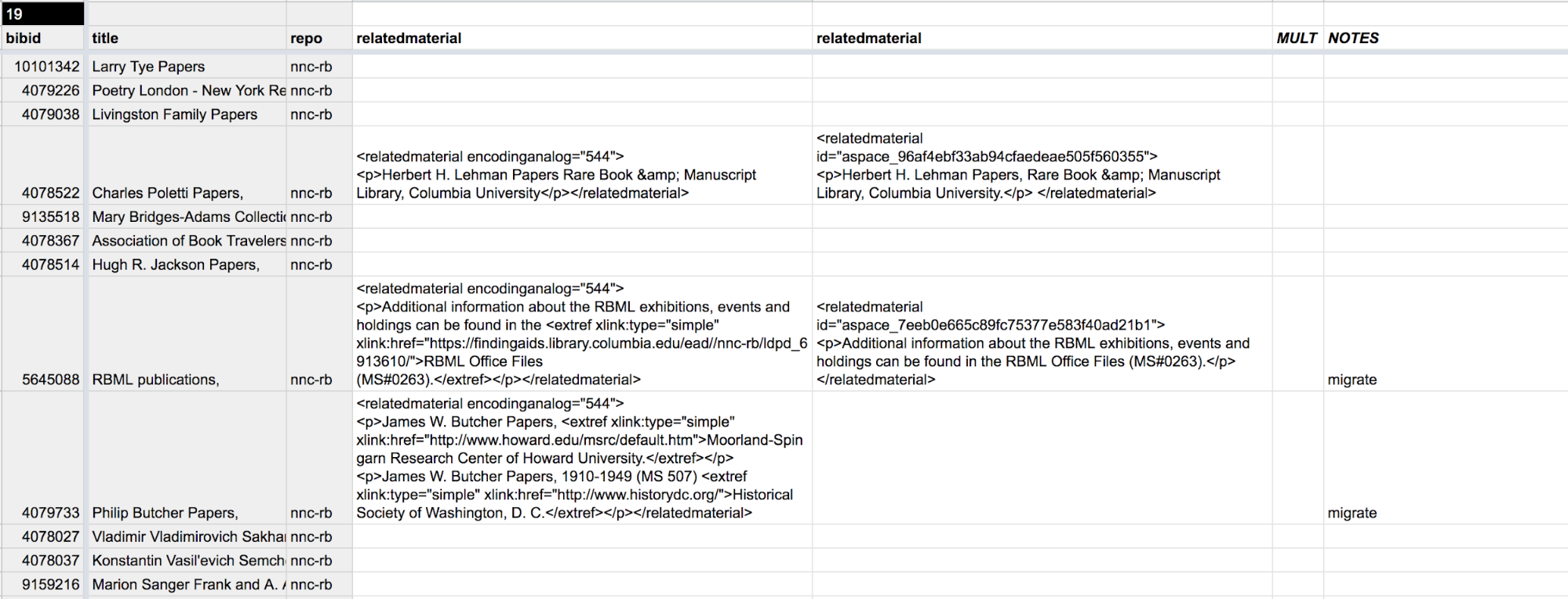
Figure 3. Each element is filtered to a separate tab, where archival staff can review two versions side-by-side and determine which to migrate. “Migrate” added in the Notes column indicates that the legacy version (on left) should be migrated in the merge.
Data Collation: The Migration Grid
The archivists completed the review efficiently by working concurrently in the same document. Each tab (24 in all), representing a collection-level element, now had a column indicating which version to migrate for each record. Another tab called “migrate-grid” assembled the information from the 24 tabs into a grid, with each element represented by a column. The cells were populated by formula with boolean values based on the information added by archivists in the respective tabs. The end result was a layout of one row per record, with a series of boolean values indicating whether or not to overwrite the ArchivesSpace values with those of the legacy data.
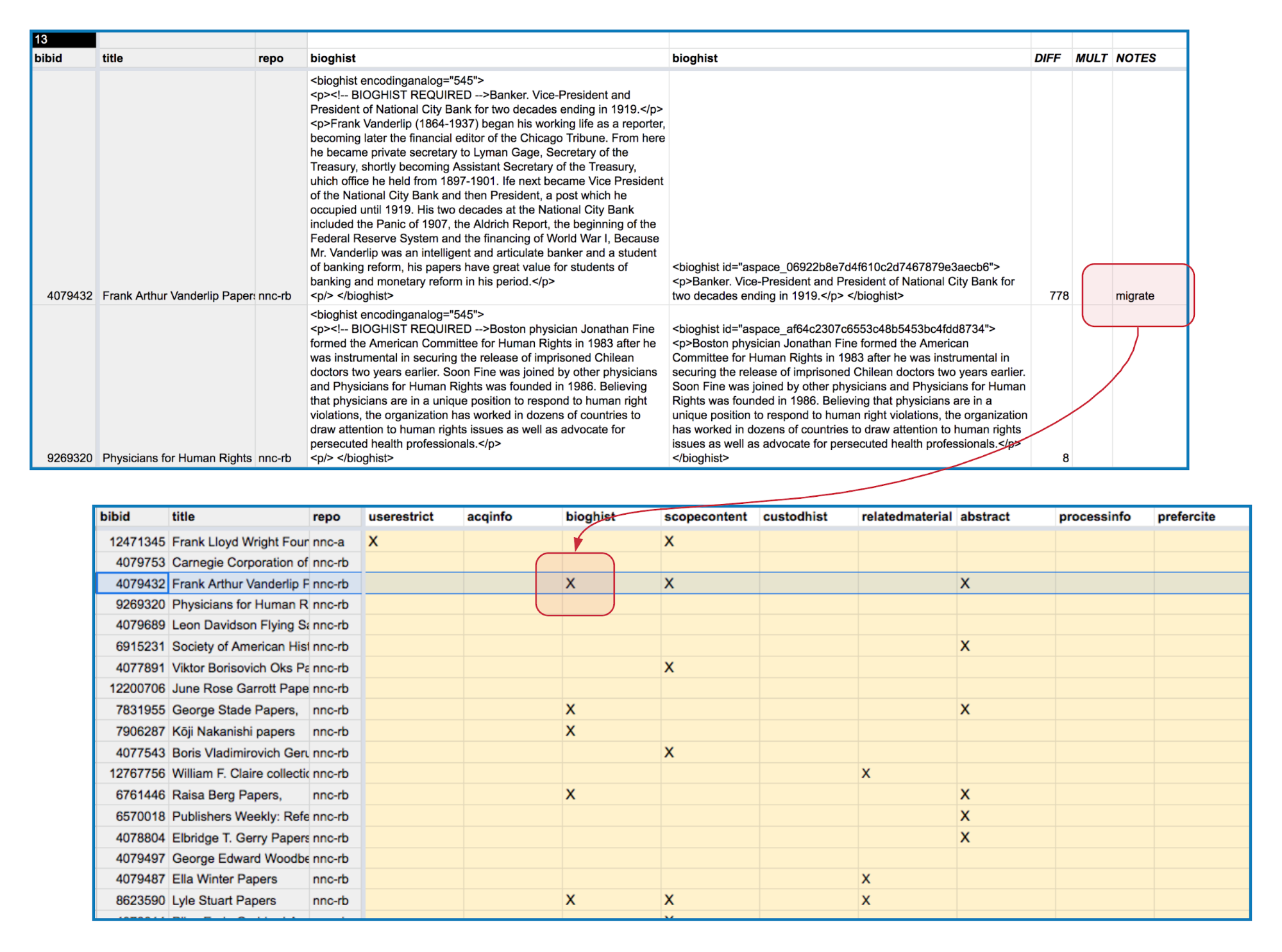
Figure 4. A migration grid collates selections from the various element views into a single row for ingest into the merge script.
Round Trip Back to Python
The next step was to merge the two versions of each record, grafting the component (dsc) section from the legacy data onto the collection-level data coming out of ArchivesSpace (and by extension, the ILS), and selectively replacing elements per archivists’ wishes as well. For this, another Python script, ead_merge.py, needed to read the data from the Google Sheet and use it to inform the merge process. For this to work, the script needed to send the boolean values from the spreadsheet as parameters when executing the XSLT transformation.
Again using the Sheets API and sheetFeeder, ead_merge.py read the migrate-grid tab into an array of rows, including the heads for use in identifying element names. The values from each row were parsed out into a series of parameters with boolean values to be passed to the XSLT pipeline executed in Saxon [5], like so:
m_userestrict=Y m_arrangement=Y m_scopecontent=Y [...]
The first stylesheet in the pipeline (ead_merge.xsl) prepared the merge by saving the requested elements (along with the dsc section) in a tree fragment variable and interpolating them into the appropriate locations in the result tree.
<xsl:variable name="add_ins">
<xsl:if test="$m_revisiondesc = 'Y'">
<xsl:copy-of select="//eadheader/revisiondesc"/>
</xsl:if>
<xsl:if test="$m_bioghist = 'Y'">
<xsl:copy-of select="//archdesc/bioghist"/>
</xsl:if>
<xsl:if test="$m_scopecontent = 'Y'">
<xsl:copy-of select="//archdesc/scopecontent"/>
</xsl:if>
<xsl:if test="$m_relatedmaterial = 'Y'">
<xsl:copy-of select="//archdesc/relatedmaterial"/>
</xsl:if>
[...]
</xsl:variable>
On the XSLT side, this task of merging data in various configurations in the two corresponding source trees proved complicated. The stylesheet had to test for a variety of scenarios where an identified element (e.g., a bioghist note) may replace one or more counterpart elements or may have no counterpart to replace and is inserted as a new element. The output was passed to two additional clean-up stylesheets performing a large number of global remediation actions. The end result was a valid, house-standard-compliant EAD that included (a) collection-level data as known to the ILS, (b) selected collection-level notes and other elements identified by archivists and brought over from the legacy EAD, and (c) all component description from the legacy finding aid.
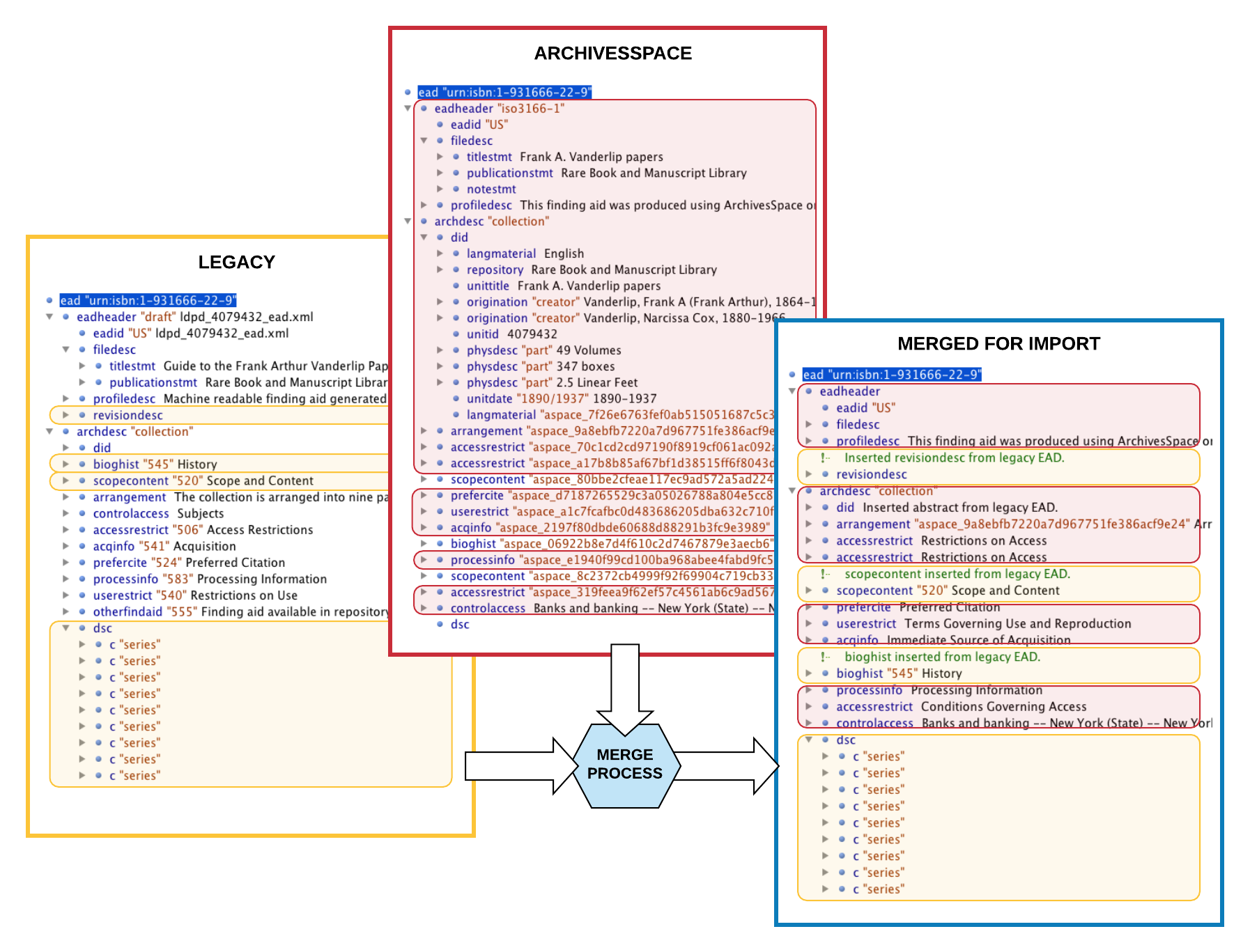
Figure 5. Elements from two source trees are merged in a result EAD document ready to import back into ArchivesSpace.
Loading Back into ArchivesSpace
The last step of the migration was to re-import the now-complete EAD files into ArchivesSpace. We realized when evaluating migration options that using an ETL approach that relied on deleting and re-importing EAD, rather than editing in place, would require extra work from our host vendor Lyrasis to restore lost links to other ArchivesSpace data structures [6]. However, careful analysis of existing links and database-level scripting allowed Lyrasis to quickly relink accessions, assessments, and other data structures. Over two months, we performed three rounds of data load and QC. 99% of our EAD files imported successfully in each load, thanks to the extensive data cleanup. Errors found in the QC process were mostly minor and due to either quirks in the ArchivesSpace-EAD importer, such as silently dropping uniform titles in controlled vocabularies, or unusual CUL EAD constructs.
Conclusion and Further Applications
The ArchivesSpace EAD migration at CUL was a complex project that forced us to countenance data variability and think through the implications of various strategies at some length. The tool chain discussed in this paper is best suited for scenarios where there are intermediate programming skills and a need to consolidate and accelerate reporting or QC processes on the cheap. Institutions that already make heavy use of Google Docs and XML workflows, such as many academic libraries (Colin et al. 2019), will find this a useful way to synergize these competencies. Libraries that encourage staff to learn by doing (e.g., writing Python scripts for one-off tasks like reporting on an EAD collection) and to explore scripted solutions on a case-by-case basis may find this approach hits a sweet spot as well.
Building To the Audience: Staff UX Matters Too
The visual design of internal reports and data interfaces is often an afterthought at best (and nonexistent for CSV exports). But the principles of user experience are just as applicable, and anything that can be done to lower the cognitive load required to navigate and use an interface means users can more readily focus attention on the task at hand [7]. Advantages of using Google Sheets for distributed data review and remediation are myriad, starting with the ubiquity and (likely) familiarity of the interface, along with ease of customization. Being able to work concurrently in one document allowed our project to move forward quickly and complete dozens of person-hours of work in a few days. Use of filtered views, formulas, and conditional formatting let us tailor the interface to our users and purpose. Programmatic use of archivist-generated judgements on which field was correct to build the combined EAD file meant we avoided the error-prone copy-and-paste method of data transfer. The automated population of the Google Sheet from the data sources meant that it was very easy to refresh data on demand and eliminated risk of version confusion that often emerges whenever CSVs or other files are passed back and forth. Most importantly, this approach allowed archivists to focus on the descriptive data in a familiar web-based interface, centering their skills and experience on the content question rather than wrestling with XSLT or struggling with version control of multiple spreadsheets.
While we made only modest attempts to innovate reporting interfaces for this particular project, we think this approach shows potential to iteratively improve report UX design at minimal cost, with potential to boost productivity, reliability, and general satisfaction. Going “beyond the CSV” in a collaborative reporting environment with high customizability thus presents advantages to institutions wishing to innovate around QC methods and practices.
Extension and Limitations
The Python–Google-Sheets integration outlined here is easily adapted to other projects and reporting needs and has proved useful at CUL for data import QC and reporting accessions and other data from the ArchivesSpace API [8]. With the addition of some modest query and operator functions including the ability to select rows based on regular-expression matching, the toolset takes on broader applicability, and in effect enables a Google Sheet to serve as a light-weight, versioned, cloud-hosted database for any Python project. Not a fan of Python? The Sheets API offers good documentation for Ruby, PHP, Java, and other frameworks. In this way, we see this type of integration as holding potential for library projects at institutions where Google Apps is already the go-to collaborative platform and where spinning up reporting interfaces quickly and repeatedly is desired. It would however not be ideal for large-scale data manipulation and storage, and production applications would be better served with a high-availability MySQL or other database if performance is of high importance. If complicated analysis and manipulation of tabular data sets is a requirement, users may do well to look at the pandas Python library and the many tools built around it.
Acknowledgements
The authors would like to thank their colleagues in the Rare Book and Manuscript Library, Avery Architectural Library and Archives, Digital Library and Scholarly Technologies, Digital Project Management, and Library Information Technologies, and at our host Lyrasis, for their work on the migration described here.
About the Authors
David W. Hodges is Special Collections Analyst in the Digital Collections and Preservation Services unit of the Libraries, and served as project manager for the first phase of the ArchivesSpace migration project.
Kevin Schlottmann has been Head of Archives Processing at Columbia University’s Rare Book and Manuscript Library since 2018. Among his first tasks was spearheading migration into ArchivesSpace. Previously, Kevin was Digital Archives Manager at the New York Philharmonic and Archival Processing Manager at the Center for Jewish History.
Notes
[1] In the earlier workflow, new finding aids were manually seeded in eXist by a digital librarian with basic data from Voyager ILS; archivists then edited and added description using oXygen XML Editor. A PHP application pulled data from eXist in real-time to build public-facing HTML content on the fly (Catapano et al. 2008). The setup accrued many features over the years, including a staging/preview mode for unpublished content; custom XPath-based reporting; and CUL-specific validation against a custom XML schema. It was a fine example of the custom-built solutions that archivists have built since the advent of EAD 2002, in the absence of archives-specific software solutions. However, as time went by the system showed other hallmarks of complex bespoke solutions familiar to library professionals. The intricate XML and PHP codebase—layered with years of bug fixes and feature additions—required delicate handling for even minor changes. The broad permissiveness of EAD 2002 emboldened archivists to push the limits of what finding aids could do, producing sometimes very divergent practices and and an assortment of display-oriented markup and ad-hoc workarounds to achieve desired outcomes. If that weren’t enough, the PHP application had been flagged by central IT as a security risk. Perhaps most importantly, the DIY ethos it embodied was increasingly at odds with the trend toward common frameworks and open-source platforms in library technology. With advances in the ArchivesSpace project over recent years, the coalescence of support in the archival community around the platform as the best-of-breed tool of archival description, and the emergence of community-developed add-ons like the excellent Harvard Excel import plugin (aspace-import-excel, [updated 2019]), the decision to migrate was an easy one. We have reached the point that Mike Rush called for in 2011, to “. . . move beyond our angle bracket fetish to develop and implement tools that allow us to focus on archival tasks. ” (Hensen et al., 2011)
[2] We did however take the opportunity to survey all non-EAD archival description and lay the groundwork for future remediation efforts.
[3] For specific EAD cleanup and preparation for ArchivesSpace import, we relied heavily on ground covered previously by our colleagues at other institutions. Dave Mayo and Kate Bower’s extensive description of EAD data cleanup in “The Devil’s Shoehorn (Mayo and Bower 2017) proved extremely useful, as did Mark Custer’s Yale AS-prep schematron(Custer 2015).
[4] A separate script extracted EADs from AS based on bib ID: https://github.com/cul/rbml-archivesspace/tree/master/ead_harvest
[5] Because of the complexity of the cleanup and merging activities performed on each record, we found we needed to break the XSLT processing into three passes (ead_merge.xsl, ead_cleanup_1.xsl, and ead_cleanup_2.xsl). Multiple stylesheets can be strung together in a single call to Saxon, with the result tree of one becoming the input of the next.
[6] This approach does not maintain AS ids for resources. CUL didn’t rely on these, but persisting these would likely require additional database-level work.
[7] Even minimal tweaks to shared sheets such as freezing header rows and write-protecting imported data columns make for much improved report UX.
[8] Our migration workflow did not make use of the AS API since we were already working with EAD XML and it was easier to merge XML with XML. However, a similar process could act on JSON data from API calls rather than XML via XSLT; the Python-Google Sheets approach described here is agnostic as to data interchange methods.
References
Aspace-import-excel [Internet]. [updated 2019 June 20]. Harvard Library of Harvard University. Available from: https://github.com/harvard-library/aspace-import-excel
Bartczak, J., & Glendon, I. (2017). Python, Google Sheets, and the Thesaurus for Graphic Materials for Efficient Metadata Project Workflows. The Code4Lib Journal, (35). Available from: https://journal.code4lib.org/articles/12182
Catapano, T., DiPasquale, J., & Marquis, S. (2008). Building an Archival Collections Portal. Code4Lib Journal, (3). Available from: https://journal.code4lib.org/articles/77
Colin P., Chassanoff A., Lee C.A., Rabkin A., Zhang A., Skinner K., Meister S. (2019). Digital Curation at Work: Modeling Workflows for Digital Archival Materials. Proceedings of the 19th ACM/IEEE Joint Conference on Digital Libraries, 39-48. JCDL ’19. Urbana-Champaign, IL: IEEE Computer Society Press. doi:10.1109/JCDL.2019.00016. Available from: https://colincpost.info/files/post-etal-digital-curation-at-work_final-preprint.pdf
Custer, M. (2015). Validation Scenarios – ArchivesSpace @ Yale. Available from: https://campuspress.yale.edu/yalearchivesspace/2015/07/22/validation-scenarios/
Huffman, N. (2016). Getting Things Done in ArchivesSpace, or, Fun with APIs. The Digital Collections Blog. Available from: https://blogs.library.duke.edu/bitstreams/2016/09/21/archivesspace-api-fun/
Mayo, D., & Bowers, K. (2017). The Devil’s Shoehorn: A case study of EAD to ArchivesSpace migration at a large university. The Code4Lib Journal, (35). Available from: http://journal.code4lib.org/articles/12239
Ou, C., Rankin, K. L., & Shein, C. (2017). Repurposing ArchivesSpace Metadata for Original MARC Cataloging. Journal of Library Metadata, 17(1), 19–36. Available from: https://doi.org/10.1080/19386389.2017.1285143
Hensen, S., Landis, W., Roe, K., Rush, M., Stockting, W., & Walch, V. (2011). Thirty Years On: SAA and Descriptive Standards (Session 706). The American Archivist, 74(Supplement 1), 1–36. Available from: https://doi.org/10.17723/aarc.74.suppl-1.15011hj3lg56t0t3

Subscribe to comments: For this article | For all articles
Leave a Reply