by Elizabeth McAulay
Introduction
In libraries software systems undergird the majority of our work. However, regardless of how ingrained a system may be in our daily activities, all software solutions are temporary [1]. Within an organization each software system has a life cycle: (1) selection, (2) implementation, (3) use, (4) dissatisfaction, and (5) migration and decommission (see Figure 1). There is the phase of the rising system: selection and implementation. Then there is an era of smooth sailing in which we use the system routinely and the system is integral to our work. But soon, the system enters its waning phase, and the looming death of the system haunts us [2]. The waning phase can be precipitated by internal or external forces, such as user and/or developer dissatisfaction with the system or software end-of-life decisions from external bodies. When the external or internal pressure reaches an inflection point, organizations initiate a new software system life cycle. In their recent article, Babcock et al. (2020) offer a good overview of this life cycle relative to their digital collections software system. As one system is waning, another life cycle is usually spawned that leads to the birth of a new system, and part of that process of switching systems is the awkward and onerous task of migration. Migration is the one-time activity in which we port our content from the old system to the new system.
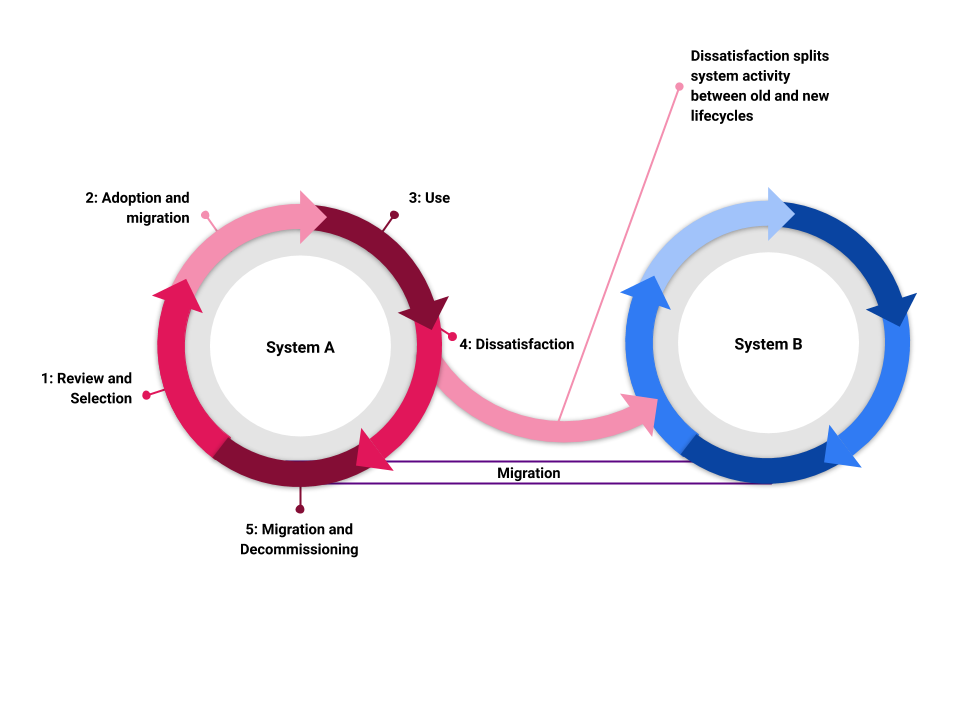
Figure 1. Two systems life cycles chained together.
Software system life cycles are a natural part of library organizations and, therefore, migrations are a frequent activity in library technology groups. I see evidence of the prevalence of migration activities both in my own organization and when consulting the articles in this journal. At the time of writing, the University of California, Los Angeles (UCLA) Library is involved in migrating four of our major systems: the general website content management system, the electronic resources management system, the integrated library system, and the digital collections repository [3]. When looking to our larger Code4Lib community, the frequency of migration projects is evidenced by the variety of articles on the topic in the Code4Lib Journal; at least 10 articles published within the past four years specifically report on migration tools, methods, or projects [4]. Nevertheless, migration is often seen as a one-way, one-time activity — just a big project with a lot of throwaway, case-specific code. Given the inevitability of migration in library technology work, I propose there is an opportunity to identify migration principles that support libraries in adopting and using systems. While specific examples and approaches to migration are useful, this article aims to serve as a companion during any migration. In this article, I will provide some specifics about the context of the migration for the UCLA digital collections and then outline some proposed evergreen principles of migration [5].
Case Study: Background
The Digital Library Program at the UCLA Library was established as a library unit in 2004, comprised of librarians and situated to partner with a small team of digital library software developers in the library technology unit. Since 2004, the Digital Library Program unit has created and maintained a growing corpus of unique digital collections and projects. Some of these projects actually continue on the web in their near-2004 vintage, e.g., our Campaign Literature collection, which contains ephemera related to elections in California from 1908 to 1940. At present we manage 201 published collections comprising 3.25 million assets and 235 terabytes [6].
During the period of 2004 to the present, we have used many different systems. As with many digital library initiatives, at UCLA we have endeavored to support both custom projects with unique features and also generalized systems that promote increased output [7]. There was a period in which we focused on the marriage of these two opposites by using generalized systems to manage and structure metadata and content files underneath customized interfaces to display these items and enable unique user experiences. The underlying database and web application programs retained standardized workflows that could support high volume output and aggregation, and then custom web application programming could be layered on top for specialized features and unique branding. This endeavor occupied us locally, but also matches the broader developments across the digital library field. During this period, many institutions were developing repositories and other technologies that would support increased standardization and interoperability: DSpace, Fedora, Hydra (now Samvera), Islandora, and the International Image Interoperability Framework (IIIF).
First, we used a one-collection-per-system approach. We developed our own custom database schema, our own custom web application, and we cloned the schema and application and customized it for each collection. Each collection was a standalone instance and could be customized as much as we could afford [8]. As the collections started accumulating, we recognized that the aggregate of the collections was more meaningful than any single collection, and we re-architected our custom database plus Java solution into a custom-built repository and publishing system. This new system meant that we had a locally developed repository system that allowed for greater efficiency and improved discoverability.
However, soon we started to realize that we were isolated with our locally developed system. We were unable to share code with other institutions so we were always dependent on our own development personnel to accomplish any new objective. At that same time, we observed other institutions converging on shared technologies and developing features and solutions more quickly. To participate in this new way of working, we adopted Islandora as our digital library solution and Drupal as our new content management system for the broader library website [9]. This new solution did improve some of our capacity issues, but after roughly four years we again recognized the need for a new system that could better fit our needs. First among our reasons for selecting a new system was that the potential synergy between Drupal and Islandora was not as productive as imagined. Second, we realized we did not effectively connect with the larger Islandora community of developers and users [10].
Thus, in 2016, we began our systems life cycle again. We started with a formal review and selection process for a new digital library solution. Two digital library staff members were assigned to research and write a white paper; they were asked to outline our needs, conduct an environmental scan of possible systems, and offer a recommendation on how to proceed [11]. As an organization, we used the white paper to support discussion, review options, and select a new system. We chose Samvera, which is actually a suite of systems, specifically Hyrax for asset management and Blacklight for discovery and display. Since that decision, we have both adopted and begun implementation of the new system while also establishing a microservices approach. In this approach, we have developed a workflow and suite of microservices specifically around preparation and delivery of image assets using the International Interoperable Image Framework (IIIF). We have separated our IIIF applications into a set of services that our digital library applications utilize. At present, our IIIF-focused microservices include image preparation, IIIF-manifest preparation, and a IIIF image server. After images are prepared through these microservices, we ingest a comma separated values (CSV) file with URIs for the image asset and its corresponding IIIF manifest into Hyrax. Our Hyrax instance adds data to a Solr index that is copied to a second index which drives our public Blacklight instance. In this current instantiation, any one of the services can be replaced or re-architected while the other components remain unaltered. In the same fashion as the University of Toronto, as reported by Babcock et al. (2020), UCLA Library will continue to break our technical infrastructure and systems into microservices to allow for more nimble development, maintenance, and improvement going forward. As part of that transformation, we might find ourselves always migrating — at least a little bit.
Data Must Flow
Indeed, even while I am wrestling with the challenges and details related to our current migration to Samvera, we are re-migrating some of the already migrated collections so that we keep pace with the newer microservices. I found this reality somewhat frustrating even while I am supportive of the microservices philosophy. In the midst of this reaction, I recognized an opportunity to analyze our migration activities and shift from a telic mindset to an atelic one. The Greek word telos means end or purpose and telic activities would therefore be those that have an end as their goal. By contrast, atelic activities are those that are pursued for their own good and without end. While clearly the migration project we are working on at UCLA for our digital library will have a completion — a successful one! — I would like to attempt to reconceive migration as a practice, like yoga, instead of a single event like a race or a match. An always-migrating mindset might include thinking about our metadata and content as water that flows through a faucet that repository managers can turn on at any point and direct toward any garden.
Principles of Migration
From my experience through several migrations, I have learned that while system-to-system migration is always specific and non-repeatable, there are some principles that undergird every migration and are worth sharing. I propose the following principles:
- Documentation: Take the time to document and share your data with your organization. When you make decisions about how to organize your data, document those as well. Leave a trail, they may be your breadcrumbs.
- Transparency: Treat your migration like something that someone else might need to take over at any time.
- Love your data: Interfaces and systems change. The data that flows through these systems is the true value in all our organizations.
- Interoperability is a verb: Moving data among systems improves its interoperability.
First, systems exist to serve a purpose. In the past, that purpose and the current system were aligned and married. However, when a system approaches its end of life, it is a good moment to re-examine the purpose it is serving. Ask questions. What is the mission-driven service that the system enables or supports? In what ways does the organization want to evolve that service? What are the bottlenecks that impede efficiency or degrade the quality of the service? In asking these questions, you can ensure that you and your organization are not mistaking aging technology for outdated services or processes.
Second, inventories of what is in a system are essential. Inventories are both philosophical and practical. Philosophically, an inventory should present the theory of the system: what are the things the system contains, how many types of things are there, what is the relationship between the internal inventory (often a database) and the thing it points to (a file, a link, a physical entity). Your inventory needs to show you the theory of the system and then it needs to provide a scale of the system. Inventories can serve throughout all stages of the system life cycle and can help you continually evaluate the efficacy of your system.
Third, this migration will not be your last. Everything about a migration is focused on getting it done: getting to the promised land where everything will be in the new system and working better. Then we can get back to our regular work and everything will go more smoothly. That ethos of migration is a partially true myth. The new system will improve some of your regular work, but you are still in a life cycle of systems. More importantly, your data and metadata are in motion constantly–serving your organization’s mission. You are always in the process of imagining new ways to orchestrate the connections among your materials, access, data, metadata, users, and staff. Therefore, if another migration might be in the near future, I encourage you to prepare for it now. I see this as a gift to a future self. Is there some aspect of this migration or the new system that you can arrange to make future migrations easier? Some areas to consider: documentation, data integrity, inventory processes, and communications.
Conclusion
This article is a thought piece about a standard practice in library technology: systems migration. I urge us to see migration as an activity that is a phase of a life cycle, and that we are always engaged in that life cycle. Migrations are disruptions to existing workflows and work assignments with enormous effort dedicated toward them, but so frequently these migrations are filled with throw-away scripts and data or metadata mappings that are only useful for the current migration. Our challenge is to extract learning from each migration that might help us when all the specifics may be completely different when the next migration rolls around. With these principles in hand, I think we can adopt an ethos of always migrating that more closely matches the reality of systems life cycles in libraries.
Coda
One final note about software systems: they are run by people. The best software solution for your organization’s list of requirements is not necessarily the right system for your organization. A software system and a migration strategy need to align with the motivations and aptitudes of your organization, your organization’s leadership, and your current staff. Managers and decision-makers should push team members to take on new challenges and to continue to learn new technologies. However, we should ensure that the challenge aligns with the values and motivations of the leaders. Moreover, if key personnel related to the system change, take a moment to evaluate whether your current trajectory still has the same alignment. Even if you just finished a migration to a new system, it’s okay to always be migrating. In fact, with these best principles in hand, you are ready for it.
Notes
[1] For a good summary of some scenarios that lead to migrations see Hodges and Schlottmann’s introduction (2019). In their article about their digital collections interface tool, Becker, Williamson, and Wikle note as an aside that “no platform is future proof” (2020).
[2] This life cycle is the same whether systems are vendor-supplied or locally developed or some combination of the two. Likewise, the connection between an old system and a new system remains migration, and whether supported by a vendor or performed locally, the readers of this journal will find themselves involved.
[3] For our general library website we are migrating from a single content management system and web publishing solution (Drupal 7) to Craft as our content management system and a locally developed Vue.js end user interface. The migration for both our electronic resource management system (Summon) and our integrated library system (Voyager) is driven by the University of California’s system-wide selection of Ex Libris’ Alma-Primo solution. Lastly, for our digital collections repository system, we are migrating away from our locally developed Oracle-Java web application to a microservices suite of applications that leverages community products, including Samvera applications and Cantaloupe for implementation of the specifications outlined by the International Image Interoperability Framework (IIIF).
[4] I searched the Code4Lib Journal archive using the keyword “migration” and then reviewed the introduction to each article to determine whether the article was substantially about a technology system migration. From this process, I identified 10 articles that substantially addressed migration, including migrations of repositories, archival description systems, and integrated library systems. Notably, these articles were all from the past four years. These articles were: Babcock et al. (2020), Banerjee and Forero (2017), Gomez et al. (2020), Hodges and Schlottmann (2019), Maistrovskaya and Newson (2019), Mayo (2019), Mayo and Bowers (2017), Ramshaw et al. (2018), Teal (2018), and Tuyl et al. (2018).
[5] I see this article as furthering the concepts presented by Tuyl et al. so creatively in their 2018 migration as Greek tragedy article.
[6] The way we count our assets varies across our multiple platforms. Depending on the collection, we may count an issue of a local newspaper as one item or as eight items (each page being an item). That discrepancy is caused because we currently are using several repository systems and we are building inventories based on the way those systems work instead of maintaining an agnostic and independent inventory. In the future, we will want to be able to represent our holdings in multiple counting methods: volumes, linear feet, and archival digital assets. For the purpose of evaluating the magnitude of the collections we are managing and migrating, the size in terabytes indicates the scale and the number of collections indicates the diversity of these assets.
[7] This approach has been discussed in the literature in the following article: Becker, Williamson, and Wikle (2020).
[8] We used Oracle database and wrote Java web applications.
[9] Our Islandora 7 instance still serves as a repository for some of our collections, but we use a non-Islandora web application for public discovery. See, for example, the International Digital Ephemera Project and the Picturing UCLA collection. For more about the Islandora digital library software, see https://islandora.ca/. The UCLA Library website uses Drupal 7.
[10] The Islandora community is robust and many creative and effective repositories have been built using Islandora. I do not intend to disparage the Islandora community in these comments, but I am aiming to be transparent about my experience in managing the UCLA Digital Library Program through a variety of digital repository systems. The process of selecting and evaluating systems is not the focus of this article so I am aiming to provide enough details about the context around a migration process without delving into that context substantially.
[11] Our process and key activities were similar to those outlined by Tuyl et al. (2018) and Babcock et al. (2020) in their recent articles: conduct stakeholder discussions and outline our current needs; investigate existing software solutions that might meet these needs; and provide a recommendation. The full white paper has been made available on Zenodo by the authors Peter Broadwell and Dawn Childress https://zenodo.org/record/3027359#.X-pb6-lKg1s. doi:10.5281/zenodo.3027359. The white paper process worked very well for our organization because it encouraged a process that allowed for requirements gathering and an environmental scan with a resulting white paper that promoted discussion and debate. After a decision about our replacement system was made, the white paper supported communication and transparency. Now that a few years have elapsed, the white paper still serves as a record of the software solutions available at that time and our organization’s articulated needs.
Bibliography
Babcock K, Lee S, Rajakumar J, Wagner A. Where Do We Go From Here: A Review of Technology Solutions for Providing Access to Digital Collections. The Code4Lib Journal. 2020 [accessed 2020 Nov 14]; (47). https://journal.code4lib.org/articles/15000
Banerjee K, Forero D. 2017. DIY DOI: Leveraging the DOI Infrastructure to Simplify Digital Preservation and Repository Management. The Code4Lib Journal.(38). [accessed 2020 Dec 29]. https://journal.code4lib.org/articles/12870.
Becker D, Williamson E, Wikle O. 2020. CollectionBuilder-CONTENTdm: Developing a Static Web ‘Skin’ for CONTENTdm-based Digital Collections. The Code4Lib Journal.(49). [accessed 2020 Dec 29]. https://journal.code4lib.org/articles/15326.
Broadwell P, Childress D. Digital Library Systems and UCLA: An Environmental Scan with Suggestions for Near and Medium-Term Technology Strategies and User Stories / Functional Requirements. Zenodo; 2017. https://zenodo.org/record/3027359#.X-pb6-lKg1s. doi:10.5281/zenodo.3027359.
Gomez J, Clarke KS, Vuong A. 2020. IIIF by the Numbers. The Code4Lib Journal.(48). [accessed 2020 Dec 18]. https://journal.code4lib.org/articles/15217.
Hodges DW, Schlottmann K. 2019. Reporting from the Archives: Better Archival Migration Outcomes with Python and the Google Sheets API. The Code4Lib Journal. (46). [accessed 2020 Dec 12]. https://journal.code4lib.org/articles/14871.
Maistrovskaya M, Newson K. 2019. Making the Move to Open Journal Systems 3: Recommendations for a (mostly) painless upgrade. The Code4Lib Journal. (43). [accessed 2020 Dec 29]. https://journal.code4lib.org/articles/14260.
Mayo C, Jazairi A, Walker P, Gaudreau L. 2019. BC Digitized Collections: Towards a Microservices-based Solution to an Intractable Repository Problem. The Code4Lib Journal. (44). [accessed 2020 Dec 12]. https://journal.code4lib.org/articles/14445.
Mayo D, Bowers K. 2017. The Devil’s Shoehorn: A case study of EAD to ArchivesSpace migration at a large university. The Code4Lib Journal.(35). [accessed 2020 Dec 29]. https://journal.code4lib.org/articles/12239.
Ramshaw V, Lecat V, Hodge T. 2018. WMS, APIs and LibGuides: Building a Better Database A-Z List. The Code4Lib Journal.(41). [accessed 2020 Dec 29]. https://journal.code4lib.org/articles/13688.
Teal W. 2018. Alma Enumerator: Automating repetitive cataloging tasks with Python. The Code4Lib Journal.(42). [accessed 2020 Dec 29]. https://journal.code4lib.org/articles/13947.
Tuyl SV, Gum J, Mellinger M, Ramirez GL, Br, Straley on, Wick R, Zhang H. 2018. Are we still working on this? A meta-retrospective of a digital repository migration in the form of a classic Greek Tragedy (in extreme violation of Aristotelian Unity of Time). The Code4Lib Journal.(41). [accessed 2020 Dec 12]. https://journal.code4lib.org/articles/13581.
About the Author
Elizabeth McAulay is the Head of the Digital Library Program at the University of California, Los Angeles Library.

Bill Hackenberg, 2021-02-17
Lisa, I really enjoyed your post. Your perspective to see migration as a process is very illuminating. Also, really enjoyed working with you in a project manager role for your first implementation of Samvera at the UCLA Library.
Your post really got me thinking. What about a Progress Metric of some sort? It might provide some additional insight into the migration process. How much content has finished? How much is left? What is the pace of migration?
Here’s a recent example of the potential benefits of a progress metric. Early in the recent 2021 COVID-19 vaccination phase, a leader was heard to say something along these lines: if we continue at the current pace, we will finish in late 2022. This lead to improvement!
Progress metrics can guide practitioners and inform leadership.
Here’s another example. I am not sure is this is still true, but at one time the size of the team tasked with painting the Golden Gate Bridge was determined so they could just start again when finished. This was a factor of the life-span of the paint divided by the size of the team. With a good Progress Metric, you may be able to synchronize with the system life cycle.
Progress Metrics serve all sorts of purposes and are frequently used by Project Managers for planning and tracking purposes. Sometimes they lead to change. Sometimes not. In other words, quantifying progress can be helpful!