by Maria Collins, Xiaoyan Song, and Sherri Schon
1.0 Introduction
1.1 The Importance of a Digital Mindset
Technical services professionals in academic libraries are firmly committed to digital transformation and have embraced technologies and data practices that reshape their work to be more efficient, reliable, and scalable. Evolving systems, constantly changing workflows, and management of large-scale data are constants in the technical services landscape. Maintaining one’s ability to effectively work in this kind of environment involves embracing continuous learning cycles and incorporating new skills – which in effect means training people in a different way and re-conceptualizing how libraries provide support for technical services work. This article presents a micro lens into this space by examining the use of Python within a technical services environment. In addition, the surveys and interviews conducted for this research indicate that understanding the larger context of culture and organizational support were also of high importance for illustrating the complications of this learning space for technical services. Consequently, this article will address themes that affect skills building in technical services at both a micro and macro level.
In their book, The Digital Mindset, Leonardi and Neeley (2022)[1] discuss the concept of a digital mindset, which “is the set of approaches we use to make sense of, and make use of, data and technology,” and what it means to function in today’s information environment (p.11). The idea of a digital mindset is a useful frame for understanding the larger context of this research as there are implications in a library environment beyond the application of the skill, including gaining administrative support, providing an education framework, and re-structuring the organization to better align technical skills with data expertise. Successful skill-building for individual staff includes deepening their technical understanding of their work even if they are not the person writing actual code. This is explained broadly by Leonardi and Neeley (2022) when they note that “skills give you the vocabulary, knowledge and intuition to see the bigger picture – to ask important questions” (p. 10). It also involves cultivating a supportive culture that allows for experimentation across all levels of an organization. Leonardi and Neeley (2022) observe that “If employees don’t feel comfortable suggesting experiments, managers and departments cannot benefit from insights of those closest to the data” (p.162). From a theoretical perspective, it’s easy to recognize that harnessing insights of those embedded in the work is a critical component of process improvement. This is often trickier in practice especially in larger organizations with many roles and many moving parts. One intent of this article is to elevate and make visible the evolving skill sets that are of increasing importance and utility in technical services work.
1.2 NC State Context and Motivation for this Work
Experimentation has been a key element of the culture of North Carolina State University (NC State) Libraries, which has led to a willingness to build custom solutions to assist with managing technical services when market solutions are unavailable. This approach has provided opportunities for technical services staff in Acquisitions & Discovery (A&D) to gain more technical skills by participating in the development of solutions that support electronic resource management and automation of technical services work. Prioritizing staff development was critical in developing the knowledge needed for staff to participate in this kind of work. These experiences have also been critical in developing a digital mindset for A&D staff.
In 2012, the A&D department became increasingly interested in introducing additional technical skill sets, such as light-weight scripting using Python, after the creation of a data-centered unit in the A&D department called Data Projects & Partnerships (DPP). The formation of this unit was in direct response to the need for more technical and metadata expertise. DPP staff have learned to use OpenRefine, regular expressions, and some programming languages (such as Python) in order to write queries and create data workflow efficiencies. Given the growing interest in using Python in A&D as well as across several other library departments, A&D’s former electronic resources librarian, Xiaoyan Song, organized a Python interest group to examine the use of Python in library work. This interest group has served as a learning cohort for sharing Python-related tips, ideas, and strategies. Sharing sessions of the group also revealed increased interest and application of Python by the broader library community.
These ad hoc efforts have proven useful in exposing staff to the use of Python to support their work, however evolving these kinds of technical skills in A&D has not occurred without navigating numerous barriers including gatekeeping of resources and limited institutional understanding of the evolving requirements for technical services work. As A&D staff embarked on their learning journey, cultivating and acquiring organizational support emerged as a critical component for the successful adoption of these evolved skills. Consequently, in addition to learning about examples of how Python is used to perform technical services work, our team was interested in learning more about training and organizational support across the academic library community to support growing this skill set among technical services staff.
1.3 Research Objectives
In order to explore this further, the authors conducted two surveys and eleven follow up interviews to investigate the following three areas:
-
- use of Python to support technical services work including how often Python is used, areas of support, examples, and strategies for organizing and communicating code;
- education including skills and competencies, formal and informal training options, and suggested resources; and
- organizational support and acknowledgment including positions in the organization performing the work, types of organizational support such as time, increased pay, or formal training, transition of existing positions, and inclusion of related skills in position descriptions.
This research represents conversations among a limited number of professionals in the field, and these findings signal trends and areas of potential growth in technical services work. Beyond providing ad hoc examples of Python work, these conversations point to the value of growing technical skills more broadly to support technical services work.
2.0 Literature Review
2.1 Changing Landscape of Work
Since the approach to this article is both broad and narrow in scope, the literature review topics explored were likewise. Starting with the bigger picture context of the changing nature of work, Leonardi and Neeley (2022) observe that transitions in a digital environment are continuous and require constant change management. They state “leading in a digital environment is no longer about navigating change when it happens, it means helping your coworkers, employees, partners, and customers to continuously prepare for what’s coming next and to embrace that they live and work in inexorable transition” (p. 168). This concept as it relates to skills training indicates a different kind of learning environment that allows for constant introduction of new skills and a system of training that is iterative and not staged in phases. This has implications related to formal vs informal training as well as the ability to independently learn new skills.
More specific to libraries, Adam (2018)[2] discusses “the shifting paradigm of libraries in the digital age” and advocates in his essay that API training is an essential skill for all librarians (p. 180). Although this article is not Python-related, Adam’s call to action points to the shift in the kinds of works that librarians perform in the digital age and highlights the division of labor that exists in many libraries between information technology professionals and librarians. There are increasingly blurred lines between these two groups. Adam (2018) argues that “This division, though, is not tenable in the information world in which librarians now work, and it is certainly not going to be tenable in the future. As libraries focus increasingly on digital content, and as the realm of the information libraries collect and provide access to expands beyond the traditional “published” forms of monographs, reference works, and serials, anyone who seeks to provide patrons access to information is going to have to be familiar with pulling that information from a range of sources” (p.182). This shift in the way library professionals work goes both ways as the information skills applied by technical services staff are increasingly useful for supporting broader library functions. This is especially true for metadata support. Madden (2020)[3] discusses this idea of broadening the application of technical services support for areas like accessibility work for websites, for instance, by discussing how technical services staff are helpful in creating alternative text for images on a library’s website.
2.2 Shifting Core Competencies
Expanding the technical skills that librarians need in a digital environment indicates a need for broader core competencies related to technology for areas of librarianship. The literature in this area focuses on developing competencies for library science more broadly as well as specific areas of librarianship where there is increasing demand for programming skills. In a 2022 article, Yadav[4] seeks out alumni of India’s 10 library and information schools to determine essential competencies that should be taught. “Most of the professionals opined that LIS schools should integrate computing or IT skills in the curriculum, including digital library skills, library automation, discovery services, web publishing and database management. There should be intensive training on digital tools, statistical tools, programming languages, content management software and so on” (Yadav, 2022, p. 853). Beyond library school, the literature also points to a need to evolve competencies for professionals working in academic libraries. Raju (2017)[5] describes the changing skill sets required by academic librarians and notes that their “South African study concurs with findings from the international literature that librarians in the academic library environment, which has seen perhaps the greatest impact of technology compared to other library sectors, require IT knowledge and skills to a significant extent” (p.753).
In respect to core competencies for specific areas of librarianship, Read and Cox (2020)[6] explore technical competencies for scholarly communications librarianship. Their take is more about creating connective tissue between stakeholders interested in technical innovation rather than having scholarly communication librarians learn coding. They conclude that the necessary competency related to technology should be “soft skills and certain positive orientations to technology rather than practical technical skills” (p. 1). This speaks to Leonardi and Neelley’s (2022) ideas about establishing a baseline knowledge related to technical work that allows for and enhances collaboration. In other words, increasing understanding of these skill set areas has a positive benefit even if you are not actually programming. Another article by White and Powell (2019)[7] focuses on the need for evolved core competencies to better support GIS librarianship noting the increasing “importance of coding and programming languages” (p. 65). These authors discuss the utility of “applying a coding approach to solve practical problems in the library” and note, “in particular, R and Python, two programming languages used widely due to their accessibility and ease of learning” (p. 47). This call for updated technical skills to perform GIS work mirrors a similar need for shifts in core competencies for technical services work.
Related to technical services core competencies specifically, Frank (2013)[8] discusses not only the changes in technical services work, but also the collaborative benefits between IT and technical services professionals. As batch editing of bibliographic MARC records remains an important aspect of a cataloger’s job, Frank (2013) observes that “a cataloger’s ability to add to their arsenal additional tools and skills to automate workflows by analyzing and correcting MARC records in bulk is becoming more critical than ever.” Frank points to the tension that often exists between those with programming skills and those waiting on programming skills and observes that these tensions are often best handled through collaborative synergy. Frank observes that “the increase in collaborations between catalogers and coders, as well as the increase in catalogers who are coders, is proving to be the next logical direction for the field of bibliographic description and access.” Shifting competencies in this way directly corresponds to the changing demands of the job. Mitchell (2013)[9] discusses this idea of evolving competencies by framing programming competencies as part of metadata literacy. Mitchell states that “the ability to work with metadata programmatically both allows [a metadata professional] to be more effective at a type of work that they do and have greater overall control over the flow and use of metadata in their collections. While there is considerable movement in the library community toward cloud-based and linked data models for metadata these new formats require greater, not less, familiarity with programmatic tools (p. 309).” This last reference to understanding metadata initiatives through a programmatic lens is central to the idea of a digital mindset. Likewise, Adam’s take on librarians learning to use technology, such as APIs, further establishes the idea that evolved core competencies in this area are a necessity to perform the job. Adam (2018) states that “if librarians want to continue to play a key role in the supply chain of information, they will take this opportunity seriously and learn these new skills” (p.187). The common thread across these articles that are focused on developing technical core competencies is the critical need to evolve work practices to align with the changing nature of the job.
2.3 Why Python – Its utility and value to libraries
So, why Python? There are several reasons including general agreement in the literature that Python is an accessible and easy to use coding language for library work. Walton states that Python is “one of the best languages to start with…Python is simple and powerful” (Thomsett-Scott, 2016, p.7)[10]. He also addresses the accessibility of Python noting “a person reading the script can easily see what the script is trying to do” (Thomsett-Scott, 2016, p.7). White and Powell (2019) concur that “one big advantage to learning Python is that it is easy” (p.54).
Other authors comment specifically on coding libraries offered for Python including PyMARC. Magnuson (2016, July 5)[11] comments that “Python is a great programming language to know if you work in a library:… its syntax is fairly clear and intuitive, and it has great, robust libraries for doing routine library tasks like hacking MARC records and working with delimited data, CSV files, JSON and XML.” PyMARC, which is a “Python library for working with bibliographic data encoded in MARC21…and provides an API for reading, writing and modifying MARC records,” is referenced by several authors as a benefit for libraries, especially for catalogers (Python Software Foundation, 2023).[12] Frank (2013, April 17) explains that the PyMARC Python library is a result of an open-source project and “provides common methods of manipulating field indicators, subfields, and field content.” In terms of utility, Hill, Frank and Pernotto further explain that “This ability to programmatically work with data can save a large amount of time, and while tools such as MarcEdit can do large amounts of batch processing, learning PyMARC both gives greater freedom and, as mentioned, allows calling from batch scripts, such that it can be one of a number of things you automate together” (Thomsett-Scott, 2016, p. 17).[13] The consequence of this automation is dramatic savings in time and improved, efficient workflows. This is critical, especially for technical services departments that continue to decrease in staff support.
Numerous articles emphasized that the scale of automation using Python can be quite small and still provide value for daily tasks. This limited frame or concept of scale helps to make Python more accessible and less overwhelming to staff with limited programming expertise. Yelton (2015. April)[14] comments that “you don’t need to write large-scale, polished, reusable software in order to get big benefits from learning to code. Automating a task with a few dozen lines of code can save you many hours in a year” (p.29). Python’s accessibility allows for these interactive improvements. This is especially true for areas of growth in the collection, such as ebooks, where staff are having to manage high-volume workflows on a daily basis. For instance, Thompson and Traill (2017, Oct 18)[15] observe that “As ebook collections grow (and libraries’ staff shrink), management processes must also be scalable… In the current environment with its complex implementation choices and demanding maintenance workflows, automation is essential to make these choices and tasks manageable.” Another growing category of technical services work involves improving inclusive description. Dong, et al. (2017)[16] note that Python could also prove useful for managing remediation projects (p.144).
Another important factor in helping technical services staff learn and use Python is the community of practice that supports this tool. Having a community to lean on when learning something technical is a game changer, especially for new or inexperienced staff. Enis (2013, March 1)[17] reports that the Python community is one “that [does] a lot of outreach to newbies, and [is] explicitly pro-diversity.” The value of the Python community is also commented on by Hill, Frank and Pernotto in their chapter from The Librarian’s Introduction to Programming (Thomsett-Scott, 2016). They comment on the support provided stating that “the community is highly robust, creating packages and offering help so that any questions you might have will quite possibly already be answered” (p.17). They also talk about the general philosophy of the community in terms of ease of use and openness. “The language and the vibrant, active community that uses it place great value on code being readable and as obvious as possible; clarity is prized over cleverness and openness over concealment. This has led to the community releasing large amounts of open-source code” (Thomsett-Scott, 2016, p.17).
2.4 Examples of Python
Given the openness of the Python community, it’s no surprise that the literature abounds with examples of strategies, tips, and techniques for working with Python. Many of these examples are one-off descriptions of projects that share code or scripts. One common area of interest was collections analysis. Examples from the literature include how to use Python scripts to assist with reviewing duplicate titles to facilitate gift processing (Maguson, 2016), how to assist with a journal review project through subject heading evaluation (McDavid, McDavid, Das, 2021)[18], and ways to query GOBI to help with collections reporting (Frazier, 2020)[19]. All of these collection examples realized time savings and efficiencies. For instance, Frazier (2020) noted that the script she used to help compile reports reduced time and effort from 10-15 hours a week to just 30 minutes.
Several of the articles mention useful Python libraries for data analysis in addition to PyMARC including the Beautiful Soup library and the Pandas library; in particular, these articles call out the ability to process large amounts of data (Maguson, 2016; Zavalin & Miksa, 2021)[20]. Another exploration of Python libraries offers a comparison for readers. In Harrington’s (2019)[21] discussion of a pilot project to generate geographic terms for a streaming video site, he uses three different Python libraries to generate terms and then compares these methods for quality. In general, these articles are a useful introduction to the various Python libraries and how they might be used.
Other technical services examples in the literature have a bibliographic focus either for data clean up, updates, or remediation. Davis (2020)[22] outlines a project that utilized Python to update 1,487 MARC records with hierarchical place names from a rare materials cataloging aid. Another example discussed by Doug, Glerum, and Fenichel (2017) used Python to help with data remediation of duplicate series data. These authors emphasized how “catalogers can build on their traditional knowledge and also use data analysis, scripting, and batch manipulation when performing large-scale remediation” (Doug, Glerum, & Fenichel, 2017, p.143). Another article by Thomson & Traill (2017) not only discusses how staff at the University of Minnesota Libraries use Python to improve the quality of metadata for ebooks, but also ways to use Python to evaluate MARC record sources from vendors, the Alma Community Zone, and WorldShare Collection Manager.
2.5 Training & Organizational Support
In respect to support for Python work, the literature does provide training resources as there is “little formal pipeline for teaching librarians to code” (Yelton, 2015. p.15). In addition to a list of resources at the end of Yelton’s (2015) chapter on learning to code, she also provides several strategies for learning that include “ • find a project • rely on Google and existing code • write documentation • persevere • find a mentor” (p.26). Helping academic librarians find training opportunities to learn to code is also a central focus of Enis’ (2013) article “Cracking the Code.” Enis notes a variety of options including “classes at the schools where they work [and] free online lectures and tutorials.” From a broader perspective, Leonard & Neeley (2022) point out several key ideas related to education and training. The learning experiences need to be understood as continuous and should be customized to the needs of the learner, and there needs to be a supportive environment. They observe that “tailored curricula are the core of continuous learning initiatives – designed for specific roles and functions based on the skills and credentials necessary for each” (p.193). In general, Leonard & Neeley (2022) acknowledge that this kind of learning, which is self-driven, can be isolating and that it’s good to have a community to reach out to that supports this space ( p.193).
This brings us to the importance of having support from your organization to pursue this kind of work. There is limited discussion of this topic in the literature as most of the resources explored were pragmatic in nature, providing examples of code and discussion of projects. But this idea of organizational support was addressed in some resources in a few different ways. In Raju’s (2017) discussion of the blurring lines between information professionals and IT professionals, he posits that this evolution in skill sets for library science professionals should be acknowledged and taught to library professionals as part of the domain. He states that “IT knowledge and skill sets should be taught not as stand-alone or IT-serviced courses but should be firmly embedded within LIS epistemology, demonstrating the intellectual claim on this broadened disciplinary space resulting from a natural evolution of the LIS discipline in response to a technology-driven information environment” (Raju, p.754). This is not a direct recommendation for organizational support, but it is at least an acknowledgement that the foundational concepts for library science should include these kinds of knowledge and skills.
Yelton (2015) addresses organizational support in another way by pointing out barriers or a lack of support in some institutions that may prevent this kind of learning. Yelton comments that “unfortunately, some librarians have no support, or even face active hostility… [Yelton shares a story about] Two managers [who] were unable to secure coding skills development for interested supervisees because their institutions did not want to reclassify them into higher salary categories reflecting those skills” (p.29). This lack of support often goes beyond salary concerns. Yelton also points out how organizational structures can prove to be intractable and lead to gatekeeping where certain skill sets are either exclusive to a particular unit in an organization or subject to approval when these technical skills are needed to perform work in other units. Yelton (2015) illustrates this with an example of “one librarian who spends a significant amount of time coding and is doing so without upper management’s knowledge; in that institution, only people belonging to other, explicitly technical, units are allowed to code” (p. 29). These ideas are discussed further by Leonardi and Neeley (2022) within the context of organizational structure and who is allowed to experiment, specifically departmentalizing or centralizing certain skill sets. They explain that “existing organizational structures can make it difficult to democratize experimentation and, in many cases, they lead to the death of experimentation” (p.158). Leonardi and Neeley note that it is more helpful to the organization to have people closest to the services and data participate in innovation (p.157). Within the context of academic libraries, this means allowing staff with data expertise in specific domains the opportunity to develop technical skills that support that work. Managers can help support these endeavors in several ways. Yelton (2015) highlights several methods of support including time, resources, workshops and conferences, code review, and internships (p.29).
Much of the focus of the literature in this space centers on specific resources or techniques that the community can re-use or borrow. Other aspects of the literature include discussions of blurring lines and core competencies for technical services work. The authors believe that this research effort is unique in its broad assessment of this space using interviews and surveys to touch on not only examples and resources, but also on the types of organizational change and initiatives that support the development of technical skills needed to support evolving practices in technical services in academic libraries. This research also highlights the value of teaching technical skills to staff not trained as developers as a means to bridge gaps and provide a better understanding of the work and systems that support it. This holistic approach brings to the surface ideas and strategies to transition organizational structures, understand barriers that require active management, and to shape continuing learning and development opportunities in this space. This article also consolidates resources shared among the participants to share with the larger community.
3.0 Methodology
To investigate the use of Python in supporting technical services work within academic libraries, the authors conducted two surveys and a series of eleven interviews, which received approval from the Institutional Review Board at NC State University. The first survey was originally developed by Sherri Schon, an electronic resources intern in NC State’s A&D department, as part of her internship project. The survey featured open-ended questions focusing on participants’ experiences using Python for technical services in academic libraries, as well as their training and learning journeys related to Python. The survey questions can be found in Appendix A.
In July 2021, the first survey was distributed through the code4lib listserv, a community that intersects with libraries and possesses technical expertise. Within three weeks, the authors received nineteen responses. These responses provided insights into how Python is employed in technical services work, encompassing aspects such as the duration and frequency of Python usage, strategies for managing Python-related tasks, practical examples of Python’s applications, the concurrent use of other programming languages, and details about formal and informal training. Upon review of the initial survey results, the authors were intrigued by the influence of organizational structure on Python-related work, and this topic was added to the scope of this project.
Survey participants were also asked if they would be willing to participate in follow-up interviews. Out of the nineteen survey respondents, eleven expressed interest in interviews. Subsequently, in September 2021, the authors sent interview invitations to these individuals, all of whom graciously accepted. The interviews, conducted in hour-long sessions via Zoom, were organized either as group sessions or individual interviews based on participants’ preferences. Each focus group consisted of two or three participants.
The interview questions were categorized into three sections: experience, training and education, and organizational structure. For the experience category, participants were asked about the management of Python work, the specific tasks for which Python is employed, and how Python scripts are handled. Training and education inquiries revolved around formal and informal training experiences, their benefits, important prerequisites for learning Python, and training responsibilities within the organization. Under organizational structure, the authors sought insights into the roles responsible for Python work, the evolution of these roles, and the organizational support provided. The interview questions can be found in Appendix B.
Following the interviews, the authors recognized that participants’ Python experiences could vary depending on the size of the library and the department. Subsequently, additional information regarding the library’s size and department was collected from the participants via email.
In September 2022, the authors decided to conduct a second survey (see Appendix C) that more directly focused on the technical services community. The objective was to explore how Python was used to support electronic resources work within academic libraries, with a particular emphasis on technical services. Three listservs, namely Electronic Resources in Libraries (ERIL-L), ACQNET, and AUTOCAT, were selected for the second survey. This survey revisited some of the same questions from the first survey regarding participants’ Python experience and introduced new inquiries aimed at understanding the ways in which organizational support was provided. The authors received 27 responses within three weeks.
To distill the insights from both the surveys and interviews, the authors reviewed and synthesized the information in several ways. They sought to identify valuable knowledge to share with the community, including examples of Python’s practical applications, similarities and differences in responses to discern potential patterns or indicators, and qualitative examples or stories illustrating how this work is supported.
4.0 Results and Discussion
This section delves into the findings derived from the surveys and interviews, presenting them under three categories: Python experience, training and learning, and organizational structure.
4.1 Python experience
This section scrutinizes various dimensions of the respondents’ experience with Python in the context of supporting technical services work. It includes an exploration of the duration for which respondents have been utilizing Python for their work, the frequency of its use, the management of Python-related tasks within specific institutions, encompassing the individuals responsible for writing Python scripts and the workflow for soliciting such work, as well as an examination of the specific tasks for which staff utilize Python scripts.
4.1.1 Length of time using Python
The question of how long staff have been using Python in support of technical services work was asked in both surveys. Similar results were seen across all listservs as well as some differences in different communities. Over 60% (20 out of 33) of participants from the Code4lib listserv have used Python within the five-year range. For the same five-year range, almost 50% (11 out of 22) of participants from other listservs have used Python (see Figures 1a and 1b). About 6% (2 out of 33) Code4lib participants started using it within a year and a bigger percentage, slightly over 30% (7 out of 22), from other listservs fall into this category.
From the Code4lib responses, 33% (11 out of 33) of participants have used Python for more than five years and a smaller percentage, less than 22% (5 out of 22) from other listservs have used it for more than 5 years.
The results indicate that the Code4lib community had started to use Python earlier than respondents from the other listservs that we surveyed. This is likely due to the fact that the Code4lib community comprises many developers who do development for libraries while other listservs focus more on traditional technical service work such as acquisition, cataloging, and electronic resource work.
The general trend among all listserv responses is that Python has been picked up by academic library workers within the last five years to assist in technical services work.
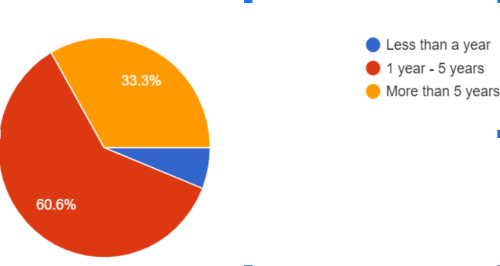
Figure 1a. Number of years using Python. Response from code4lib listserv survey.
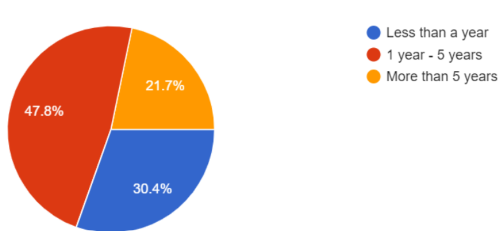
Figure 1b. Number of years using Python. Response from other listservs survey.
4.1.2 Frequency of Python use
When examining the frequency of Python usage among survey participants, the responses revealed a clear division between heavy users and light users, as depicted in Figures 2a and 2b. Among Code4lib participants, 30% employ Python on a daily basis, 33% do so weekly, while 24% utilize it at least once a month. The remaining 12% employ Python much less frequently, with intervals exceeding one month. For respondents from other listservs, the distribution shifts slightly, with monthly users representing the largest portion, exceeding one third of the total. These findings underscore the pivotal role Python plays in supporting day-to-day technical service work for the surveyed participants.
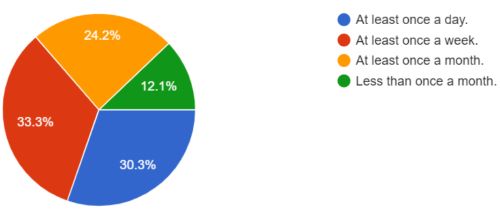
Figure 2a. How often do you use Python in your work? From Code4lib survey.
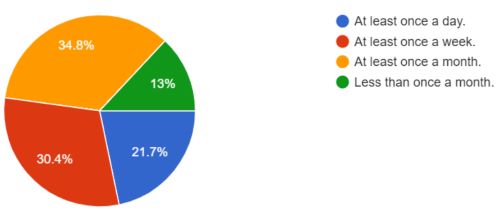
Figure 2b. How often do you use Python in your work? From other listservs survey.
4.1.3 Assigning or distributing Python-related work
The survey also inquired about the methods used by participants to manage their Python-related tasks and how they received requests for such work. In terms of the assignment of Python-related tasks, participants outlined a diverse set of approaches. Some requests were formal and channeled through a ticketing system (occurring once or twice a week) for technical support. Requests also originated directly from their supervisors or spontaneously from colleagues in different departments on campus. Regardless of the source of these work requests, participants highlighted a common theme: they typically encounter a problem (rather than a Python-specific request) and are entrusted with the autonomy to select the most suitable solution. Python is frequently one of the options they consider. These responses underscore the significance of being closely connected to or integrated within the problem spaces that staff support, as well as the staff’s capacity to independently explore a variety of solutions, including the use of Python.
4.1.4 Types of work supported by Python work
The survey findings demonstrated that Python is a versatile tool employed by staff to facilitate a wide range of functions within the library, spanning acquisitions, circulation, MARC records, institutional repositories, system API integration, reporting, data transformation, data analysis, and language translation. Although the nature of these tasks varies, a common thread is the involvement of batch processes or process automation in supporting these areas. A glimpse into the types of work for which Python is utilized is presented in Figure 3, which derives from the second survey. The top five applications of Python among respondents encompass system API integration (56.5%), task automation (56.5%), data cleanup (52.5%), batch processing of MARC records (34.8%), and reporting (30.4%). For more comprehensive insights into the specific work categories that survey participants employ Python to support, please refer to Appendix D.
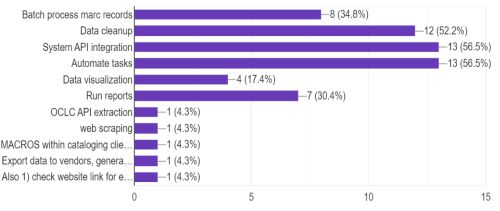
Figure 3. Types of work that Python supports. From code4lib survey.
4.1.5 Other programs, APIs, and programming languages used with Python
The surveys and interviews revealed that Python is employed both independently and in tandem with other software tools. Respondents from the first survey and interviewees disclosed instances where they combined Python with other applications, APIs, or programming languages, such as integrated library system (ILS) APIs, Java, JavaScript, SQL, PHP, and more. This underscores Python’s versatility as a general-purpose language, making it a versatile and widely applicable tool.
4.1.6 Managing Python code and documentation
During the interviews, participants shared various approaches for managing Python scripts and documentation. Many recommended utilizing GitHub as a platform for storing and sharing code, both within and outside their organizations. Additionally, a few of them adapted Python code authored by others from their GitHub repositories.
Some participants opted to store their code and documentation on local machines or internal documentation systems, such as Confluence Wiki, while others found value in using Google Colab. Notably, one participant using Google Colab mentioned creating and sharing scripts with colleagues in their department.
The choice of which system or tool to employ predominantly hinged on availability, convenience, or the necessity to share with others. One noteworthy best practice highlighted by several participants was the importance of commenting on the code, enhancing its comprehensibility and usability for others.
4.2 Training and learning
The second aspect investigated in the surveys and interviews pertained to training and learning. Participants were queried about the methods they employed to acquire the skills needed to integrate Python into their technical services responsibilities. This inquiry encompassed both informal and formal training experiences, as well as the obstacles encountered in the learning process.
4.2.1 Acquiring Python skills
Is a computer science degree a prerequisite for acquiring Python skills? Our participants unequivocally asserted that it is not. The majority of them developed their Python proficiency through self-guided learning and learning on the job. Among the eleven interview participants, only two possessed a background in computer science. Some participants even had humanities backgrounds, including one with a degree in English.
The results of the second survey, involving participants from other listservs, unveiled a diverse array of approaches to acquiring Python skills (see Figure 4). Notably, none of the survey respondents learned Python through formal education during their undergraduate or graduate studies. Instead, 64% engaged in Python workshops or courses, either in-person or online, while 41% pursued self-guided learning without formal training. Thirty-two percent turned to YouTube as a valuable resource for learning Python, and some found Python classes within library schools, constituting 9% of the participants. Additional avenues for acquiring Python skills included utilizing books and attending conference presentations.
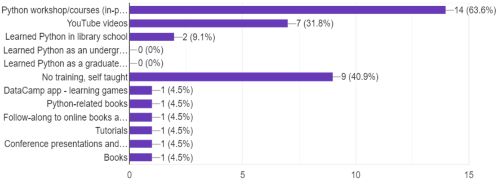
Figure 4. Methods for learning Python. From the code4lib survey.
4.2.2 Value of Formal training
When asked about the potential advantages of formal Python training, the responses from over half of the interview participants indicated that its value hinged on an individual’s preferred learning style. While some individuals might find formal training beneficial, others may not. Participants also acknowledged the crucial role that library schools can play in providing formal training. They suggested that library schools should offer classes on the fundamentals of programming, as a strong foundation in these principles can facilitate the acquisition of proficiency in any programming language. Additionally, some participants emphasized the importance of tailored training opportunities, concentrating on Python within a specific library domain, as these might be more advantageous than generic Python courses.
4.2.3 Other learning strategies
During the interviews, participants were asked about their responsibilities regarding training their colleagues in Python usage. In general, none of the interviewees held such responsibilities. This was mainly because they either operated as the sole Python user in their respective roles or were among a very limited number of individuals within their departments or libraries who utilized Python. Nevertheless, one interviewee recounted receiving training in a different programming language from their supervisor in a previous job. Another participant highlighted the potential benefit of informal or formal mentorship programs to foster skill development among their peers. This underscores the potential value of internal training and mentorship as a means of organizational support.
Numerous interviewees emphasized the importance of having a prior understanding of command lines and APIs before embarking on Python-related tasks. Furthermore, they identified additional beneficial knowledge areas, such as Git, Github, regular expressions, and MarcEdit. Previous experience with programming languages also proved advantageous, as it facilitated comprehension of Python’s logic and structure. Participants further contributed a wealth of valuable resources for Python learning and work, which can be found in Appendix E.
4.2.4 Python learning challenges
When confronting the challenge of acquiring new knowledge, the primary obstacle, as reported by both interview and survey participants, was the constraint of time. For instance, a survey participant expressed, “The hardest part was learning the basics; I had to make time for that outside of work and it took multiple weeks. It can be hard to convince fellow staff to make the effort, especially if they feel overworked already, and it’s easier to just use Excel or OpenRefine to do the same thing.”
In summary, Python proved to be beginner-friendly, with no necessity for a computer science degree to embark on its learning journey. Individuals cultivated their Python skills through on-the-job tasks and capitalized on professional development opportunities. Online learning emerged as a popular choice due to its accessibility and flexibility allowing individuals to learn at their own pace from virtually anywhere. While formal training may not always be deemed essential, the emphasized relevance of knowledge by participants, such as tools OpenRefine and MarcEdit, underscores the value of gaining a foundational understanding of wrangling with metadata in library technical services.
4.3 Organization structure
In addition to exploring participant experiences with learning and training Python, this study also looked into how organization structure impacted or influenced the use of Python in technical services. Four aspects were considered: location of positions within an organization, evolution and transformation of current positions, position descriptions, and organizational support and barriers.
4.3.1 Location of positions in the Organization
Regarding the organizational placement of positions utilizing Python for technical services, the interview findings revealed a diverse range of department locations. These positions were not exclusively housed within traditional technical services departments. Interviewees held roles in various departments, including four systems librarians in library system departments, three programmers in information technology (IT) departments, one archivist in a Digital Strategy unit, another archivist in a special collections technical services unit, one librarian responsible for metadata and assessment in a Resource Discovery Services department, and one metadata analyst in a technical services department.
Of all the interview participants, only three positions – the metadata librarian, metadata analyst, and one archivist—resided within conventional technical services departments. Their duties encompassed batch data manipulation to support institutional repositories, metadata management, cataloging, authority control, and working with Dublin Core elements schema. Two of the positions located in technical services, the metadata analyst and the archivist, mentioned that Python was not utilized in their department until after their hire.
For those situated outside traditional technical service departments, their responsibilities primarily revolved around technical support tasks such as batch loading, report generation, or serving as library system administrators to assist colleagues in technical services. Additionally, these positions contribute to data science initiatives within their libraries. In cases where positions were located outside of technical services, Python usage varied, with some work tasks incorporating use of Python and others not using it.
One factor to consider regarding the placement of positions performing Python-related work for technical services is the size of the institution. The libraries where interviewees were employed varied in staff size, ranging from five to over five hundred individuals. Two specific examples stand out in this context: one institution with a substantial technical services staff retained the position responsible for Python-related work within the technical services department. This institution had twelve staff members in their cataloging department, and the individual responsible for Python work transitioned from a specialized language cataloger to a more technically oriented role that supported batch processing, automation, report generation, and linked data projects. Conversely, in another institution with a smaller overall library staff of 18, the position handling similar Python-related technical services work transitioned from a cataloging role but was relocated to the IT department. Their duties encompassed reporting, batch data cleanup, and extracting data from various systems like ILLiad and Alma.
The results from the second survey, which targeted listservs closely associated with technical services, did not explicitly indicate departmental location. However, respondents did specify their roles at their respective institutions. Many of these roles, such as acquisitions librarians and electronic resources librarians, are conventionally located within technical services departments. According to the second survey, the top five roles for staff performing Python-related work included metadata librarians (47.8%), catalogers (30.4%), electronic resources librarians (26.1%), acquisitions librarians (13%), and system librarians (13%). Please refer to Figure 5. Notably, all of these position titles, with the exception of system librarians, are typically associated with technical services functions.
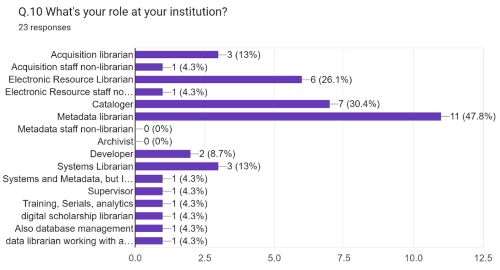
Figure 5. Respondents’ roles.
4.3.2 Evolution and Transformations of Current Positions
Regarding the inquiry into whether organizations are transitioning traditional technical services roles into more system-oriented positions, the responses were mixed. Among the eleven interviewees, only three had experienced such a transition from traditional technical services positions to more technically focused roles. One interviewee’s role shifted from cataloging to systems librarian, while another transitioned from a technician in technical services to a programmer and system administrator position. Similarly, a metadata librarian had evolved from a conventional cataloging librarian position.
Interview participants held diverse perspectives on whether the transformation of technical services positions into more technical roles represented a potential trend. The metadata analyst interviewed expressed optimism about seeing this transition occur more frequently, as they believed that utilizing Python for batch work was a progressive step. The metadata librarian emphasized the increasingly data-centric nature of technical service work, suggesting that technical services staff should concentrate on data analysis and visualization, indicating a potential need for staff with enhanced technical skills. On the other hand, some interviewees stated that their libraries had no intentions of converting traditional technical service positions into more system-oriented roles. One reason cited was the presence of a robust library systems group within their libraries. Nonetheless, one interviewee observed that such transitions might occur organically as personnel retire.
4.3.3 Position Descriptions
During the interviews, participants were also asked about whether Python skills were explicitly mentioned in their job descriptions. The responses varied depending on the participants’ job titles. Two system librarians stated that Python was not specifically listed but that programming and reporting were integral parts of their job descriptions. One interviewee mentioned that position descriptions for faculty librarian roles were challenging to update, making it unlikely for something as specific as Python to be included. Both the metadata analyst and the metadata librarian noted that Python was not listed as a requirement but that programming skills were either expected or necessary. The two archivists interviewed indicated that Python was not mandatory but was considered a valuable addition in the preferred category for their roles. Several system librarians and programmers shared that Python was initially not mentioned in their job descriptions but was subsequently added, alongside other coding languages, when their position descriptions were revised.
When asked whether their departments would continue to seek candidates with Python skills or if the use of these skills was more of a personal preference, interview participants once again provided a variety of responses. Some interviewees expressed their intention to keep hiring individuals with these skills, while others stated that it wouldn’t be a strict requirement. A few participants observed that the use of Python was a matter of personal choice. One participant mentioned that although functions or tasks might be slower without Python, staff would still be able to complete their work. Another interviewee saw the demand for Python skills as a trend, even though it hadn’t fully manifested in their libraries yet. Generally, the use of Python in technical services was considered a current trend by the interview participants.
4.3.4 Organizational Support and Barriers
The authors were also interested in exploring the different methods organizations employ to facilitate Python-related work. In the second survey, participants were queried about the mechanisms their organizations employ to support Python skills development (see Figure 6). The findings revealed that 85% of the organizations, as indicated by the survey participants, allocated time for independent learning among their staff. Additionally, 40% offered financial assistance for training, 10% delivered structured training programs, and another 10% recognized and rewarded staff who used Python to enhance their work with increased compensation.
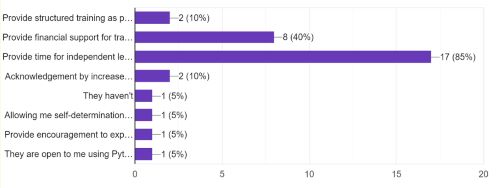
Figure 6. Organizational support for Python learning.
However, information gained from the interviews as well as the literature review highlighted numerous organizational barriers to learning Python or similar technical skills. These barriers included:
Gatekeeping: This refers to when others determine your level of access or need for a particular skill. One interview participant mentioned that they hid the fact that they used Python to assist with their work as they were not allowed to complete their work in this way by their institution.
Imposter syndrome: During one interview discussion a participant admitted that if Python had been listed in the job ad, they probably would not apply. This comment was made after the participant acknowledged how useful they found Python to be on the job.
Formal acknowledgement: This relates to lack of formal acknowledgement by the organization that Python is useful and necessary when performing technical services work as well as a lack of monetary compensation. Informal adoption of coding skills can result in lack of systemic support where training and funding are left up to the individual on a case-by-case basis.
Limited knowledge of changes in technical services: For behind the scenes library work like technical services, there is often limited understanding by others in the library of changing workflows and processes. This lack of knowledge by others in the library of the many transitions that have occurred in technical services can lead to a form of benign neglect where administrators are simply out of touch with changing requirements and competencies.
These kinds of barriers and concerns reveal that it’s simplistic to just ask a talented staff member to learn a new technical skill and apply it. There are management and infrastructure strategies that are required to better support staff and ensure they have the resources needed to effectively perform their job. When these barriers are recognized and addressed, staff will adjust to their changing work environment. When these needs are not met, staff will leave. The authors discussed these barriers during several presentations following the completion of the survey work. Shortly, thereafter, one of the interview participants reached out to the authors and commented that if these barriers had been addressed at their library, they would have stayed in their current position. They have since left the library to pursue a different position at the university where their use of these kinds of technical skills is accepted and supported.
5.0 Conclusion
Establishing a digital mindset encompasses much more than just learning a new skill to perform a task, it also involves understanding how technology fundamentally changes how and what we do. Learning a new technical skill is woven into a broader organizational context that includes continuing education, administrative support, and evolving practice. Leonardi and Neeley (2022) observe that “new technologies directly facilitate change in the way people perform their tasks” (p.176). Consequently, part of developing a digital mindset is being responsive to new technologies and being willing to make adjustments in how one works. The changing nature of technical services work in academic libraries illustrates this idea well. With increasing data pipelines and a plethora of systems supporting discovery, access, and management of thousands of library resources, scalable approaches to work are required. Library staff are increasingly using tools like Python to better manage this work. Within this context of a changing environment, this study explored the use of Python to assist with technical services work as well as the organizational support provided. Interviews and survey data revealed several key insights. First and foremost, Python has proven to be valuable for technical services tasks, especially for creating efficiencies and automating data workflows. The participants’ experiences demonstrated that Python has become an essential tool to support a variety of work in recent years. Python’s accessibility as a programming language makes it an ideal entry point for individuals without prior coding experience. A variety of positions in academic libraries within and outside of technical services are writing or using Python scripts to support technical services work. Interview participants noted that Python-related work assignments always started with a specific problem, with Python consistently emerging as one of numerous potential solutions, frequently complementing other skills like SQL and APIs.
Training for Python is mostly informal and self-directed; support is provided on an as-needed basis, with a wealth of resources available to aid in learning the language, including ample examples within the library literature. The choice to use Python is often a matter of personal preference. Although this ad hoc approach was identified as preferable to formal training by many of the interview participants, this can be indicative of a lack of structure within organizations that formally acknowledges the importance of and need for this skill. This could be due to a variety of reasons: newness of using these skills, lack of awareness of changing work requirements, or rigidity in the organizational culture. However this has occurred, formal acknowledgment is needed to ensure that staff are consistently trained and adequately compensated for the skills that are needed on the job. The fact that several interview participants noted that programming/coding work was added to position descriptions in at least the preferred category is a possible indicator that formal acknowledgement is beginning to happen.
In respect to barriers and concerns, it is also worth noting that certain organizations still maintain gatekeeping practices, dictating who is permitted to utilize Python in their work. This is problematic when trying to create an organizational culture that embraces change and supports innovation. Leonardi and Neeley (2022) address the problematic nature of centralizing and gatekeeping experimental practices. They observe that centralized experimentation “mak[es] it difficult for the people closest to the products and the data to have the legitimacy to run their own experimentation” (p.160), which is critical to success. Even if technical services staff are not the ones using Python, it’s still important in establishing a digital mindset for staff to recognize when coding is an option to automate or improve their workflows. Knowledge of programming languages helps staff to support their work at scale more directly. Scalable practices are especially needed given the changing nature of technical services work and the decrease in technical services staff. Experience in this space also allows technical services staff to better communicate with technical stakeholders in other parts of the library including system administrators and web team staff.
So how might we formalize support for this kind of work within a technical services environment? This might look like adding coding and scripting skills as a core skill or competency for performing technical services work, creating infrastructure to support training and growth, providing equitable access to resources and systems, providing equitable pay for evolving skills required for the job, and providing time for learning. These strategies allow for staff to stretch and adjust to keep up with evolving demands on the job. This kind of support also provides the potential to enhance collaboration across library departments.
The use of coding to support technical services work is commonplace as evidenced by the numerous examples of how-to-articles in the literature, but formalizing support for transitioning to and developing technical skills is less common. Establishing a digital mindset is a critical piece of this skills building equation as it will help staff (and the organizations that support them) better understand how technology can evolve their work, especially as new technologies appear on the horizon. For instance, generative artificial intelligence (AI) has the potential to transform technical services work including assisting staff with writing code, automating repetitive tasks, improving metadata quality, and streamlining acquisitions. Further investigation is required to explore the potential impacts of generative AI. However, library staff with a digital mindset will be better able to understand, adjust, and integrate these technologies into their work.
References
[1]Leonardi, P., & Neeley, T. 2022. Developing a digital mindset: how to lead your organization into the age of data, algorithms, and AI. Harvard Business Review [cited 2023 October10]. Available from: https://www.hbs.edu/ris/Publication%20Files/Developing%20a%20Digital%20Mindset_81f3f69d-e28d-483e-8d1e-ce0ee159c0bb.pdf.
[2]Adam, R. M. Jr. 2018. Overcoming disintermediation: A call for librarians to learn to use web service APIs. Library Hi Tech 36 (1):180-190.
[3]Madden, L. 2020. A new direct for library technical services: using metadata skills to improve user accessibility. Serials Review. [cited 2023 October 10]: 46 (2). Available from: https://doi.org/10.1080/00987913.2020.1782648.
[4]Yadav, A. K. 2022. An evaluation of library and information science curricula and professional perspectives in India. International Information & Library Review 54 (3): 242-254.
[5]Raju, J. 2017. Information professional or IT professional? The knowledge and skills required by academic librarians in the digital library environment. Portal: Libraries and the Academy. [cited 2023 October 10]; 17(4): 739-757. Available from: https://doi.org/10.1080/07317131.2013.785802.
[6]Read, A. & Cox, A. 2020. Underrated or overstated? The need for technological competencies in scholarly communication librarianship. The Journal of Academic Librarianship, [cited 2023 October 10]: 46 (4). Available from: https://doi.org/10.1016/j.acalib.2020.102155.
[7]White, P. and Powell, S. 2019. Code-literacy for GIS librarians: a discussion of languages, use Cases, and competencies. Journal of Map & Geography Libraries 15:45–67.
[8]Frank, H. 2013. Augmenting the Cataloger’s Bag of Tricks: Using MarcEdit, Python, and PyMARC for Batch-Processing MARC Records Generated From the Archivists’ Toolkit. Code4Lib Journal [Internet]. [cited 2023 October 10]; 20. Available from: http://journal.code4lib.org/articles/8336.
[9]Mitchell, E. 2013. Trending tech services: programmatic tools and the implications of automation in the next generation of metadata. Technical Services Quarterly. [cited 2023 October 10]; 30 (3): 296-310. Available from: https://doi.org/10.1080/07317131.2013.785802.
[10]Walton D. Introduction. In: Thomsett-Scott B, editor. The Librarian’s introduction to languages: a lita guide. Maryland: Rowman & Littlefield; 2016. p. 1-10. [cited 2023 October 13]. Available from: https://books.google.com/books?hl=en&lr=&id=Q9llDAAAQBAJ&oi=fnd&pg=PR7&dq=python+pymarc&ots=g4Sb91aqdy&sig=OxeVqZgSUvw8vbujN5lfqKcQRa0#v=onepage&q=python%20pymarc&f=false.
[11]Magnuson, L. 2016. Do library stuff faster with Python. TechConnect. Available from:
https://acrl.ala.org/techconnect/post/do-library-stuff-faster-with-python/.
[12]Pymarc 5.1.0 [Internet]. 2023. Python Software Foundation; [cited 2023 October 13]. Available from: https://pypi.org/project/pymarc/.
[13]Hill, C.E., Frank, H., Pernotto, M. Python. In: Thomsett-Scott B, editor. The librarian’s introduction to languages: a lita guide. Maryland: Rowman & Littlefield; 2016. p. 11-26. [cited 2023 October 13]. Available from: https://books.google.com/books?hl=en&lr=&id=Q9llDAAAQBAJ&oi=fnd&pg=PR7&dq=python+pymarc&ots=g4Sb91aqdy&sig=OxeVqZgSUvw8vbujN5lfqKcQRa0#v=onepage&q=python%20pymarc&f=false.
[14]Yelton, A. 2015. Chapter 6: Learning to Code. In: Library Technology Reports 51(3). ALA TechSource. [cited on 2023 October 13]. Available from: https://journals.ala.org/index.php/ltr/issue/view/506.
[15]Thompson, K. and Traill, S. 2017. Leveraging Python to improve ebook metadata selection, ingest, and management. Code4Lib Journal [Internet]. [cited 2023 October 10]; 38. Available from: https://journal.code4lib.org/articles/12828.
[16]Dong, E., Glerum, M. A., & Fenichel, E. 2017. Notes on Operations, Using Automation and Batch Processing to Remediate Duplicate Series Data in a Shared Bibliographic Catalog. Libraries Resources & Technical Services. [cited 2023 October 10]: 61 (3). Available from: https://journals.ala.org/index.php/lrts/article/view/6395/8442.
[17]Enis, M. 2013. Cracking the Code. Library Journal 138 (4).
[18]McDavid, S. R., McDavid, E., Das, N. E. 2021. Leveraging a Custom Python Script to Scrape Subject Headings for Journals. Code4Lib Journal [Internet]. [cited 2023 October 10]; 52. Available from: https://journal.code4lib.org/articles/16080.
[19]Frazier, K. 2020. Automated Collections Workflows in GOBI: Using Python to Scrape for Purchase Options. Code4Lib Journal [Internet]. [cited 2023 October 10]; 49. Available from:https://journal.code4lib.org/articles/15334.
[20]Zavalin, V. I., & Miksa, S. D. 2021. Collecting and evaluating large volumes of bibliographic metadata aggregated in the WorldCat database: a proposed methodology to overcome challenges. The Electronic Library. [cited 2023 October 13]; 39(3):486-503. Available from: https://www.emerald.com/insight/content/doi/10.1108/EL-11-2020-0316/full/html.
[21]Harrington, P. 2019. Generating Geographic Terms for Streaming Videos Using Python: A Comparative Analysis. Code4Lib Journal [Internet]. [cited 2023 October 10]; 49. Available from: https://journal.code4lib.org/articles/14676.
[22]Davis, K.K. 2020. Leveraging the RBMS/BSC Latin place names file with Python. Code4Lib Journal [Internet]. [cited 2023 October 10]; 48. Available from: https://journal.code4lib.org/articles/15143.
About the Authors
Maria Collins is the head of Acquisition and Discovery at North Carolina State University Libraries. She is a former editor-in-chief for the journal Serials Review. Her research interests include management practices in technical services and electronic resources management (ERM) systems.
Xiaoyan Song previously served as the Electronic Resources Librarian at North Carolina State University. Since July 2023, she transitioned to Duke University Libraries, assuming the role of Electronic Resources Acquisitions and Licensing Librarian. With a passion for enhancing productivity, she leverages tools and programming languages like Python to optimize work processes.
Sherri Schon received her Master’s degree in Library and Information Science from Simmons University in 2021. She currently works in Advancement Services at Hampshire College.
Appendix A: Python Questionnaire Questions sent to Code4lib
- Have you or someone on your staff ever used Python to complete any library technical services work?
- If so, how long have you or your staff been using Python?
-
- Less than a year
- 1 year – 5 years
- More than 5 years
-
- How is the work managed? For example, who writes the code and who uses the script, etc.? (No need to list any names, just job title or position)
- What kinds of tasks are accomplished with Python?
- How often do you use Python in your work?
-
- At least once a day.
- At least once a week.
- At least once a month.
- Less than once a month.
-
- Do you use other programs, APIs, or programming languages in conjunction with Python? If so, what are they? How long have you been using them?
- Have you participated in any training (formal or informal) with Python scripting? If so, can you describe the training?
- If you have not used Python for your work yet, are you planning to use it in the future? For what purposes?
- Are you willing to be contacted for further discussion about Python use in your library? (If so, please provide your email address below).
Appendix B: Python Interview Questions
Introduction
Thank you for taking the time to share your Python experience. We will start with the purpose of the project, which is to find out how Python is used in academic libraries to support technical services work. It’s for our own education to see what we can do in our own department and may potentially write up for publications. We also want to make it clear that the interview will not be recorded and that you have the option to skip any question. Your name, institution and email address will not be used in any of the written or presented reports.
Organizational structure
-
- Discussion of position:
-
-
- What is the name of your position title?
- What department are you in?
- What kind of work do you typically do (system, metadata, cataloging, IR support)?
- What is the history of doing Python-related work in your current department?
-
-
- If your position is not in a traditional technical services department, describe your intersection with positions in technical services and the work that is performed there.
- Is your organization considering transforming traditional technical services positions into more systems-focused technical positions?
- Are Python skills listed as a formal part of your job description?
- Would your department continue to hire someone with Python skills or is the use of these skills more a personal preference
- Discussion of position:
Training/education
-
- How did you acquire the skills needed for Python work? Have you done any formal or informal training?
- If you acquired your training organically through self-teaching, do you think people would benefit from a more formal training approach?
- Are you responsible for training others in your department on Python-related work?
- Can you think of skills or experience that would be important to have before learning or beginning Python-related work (prerequisites)?
Experience
-
- How is Python work managed or assigned in your department?
- Can you talk more about your experience with Python that you mentioned in the survey, especially the technical services-related work?
- What other kinds of tasks do you hope to address or approach using Python-related skills?
- How do you manage the scripts that you and your colleagues have written (Github, internal documentation system)?
- Is there anything else from your experience working with Python that we should know?
Wrap-up
-
- Potential follow up
- Questions for us
Thanks again for sharing your Python experience with us!
Appendix C. Python questionnaire sent to other listservs
- Have you or someone on your staff ever used Python to complete any library technical service work? If your answer is yes, please proceed with the remaining questions. If your answer is No, click Next and you’ll be asked to submit the survey.
- What kinds of task do you use Python for? Please select all that apply.
- Can you provide more details about the tasks you perform with Python?
- How long have you or your staff been using Python?
- Are you writing your own Python scripts or someone else writes for you?
- How often do you use Python in your work?
- Have you participated in any training (formal or informal) with Python scripting? Select all that apply.
- Are there any Python workshop or courses you’d like to recommend to others? If so, please share them here.
- In what ways has your organization supported you in learning more about Python/coding to improve or enhance your work?
- What’s your role at your institution?
- Is there anything else you’d like to share about your Python use?
Appendix D. Types of work supported with Python
- Circulation
-
- Batch searching against GOBI for lost items to have them replaced
- Send out overdue notice
- Use PyMarc, come up with a local tag 912 to store circ info from old to the new ILS
- Clean up user records
-
- MARC records work
-
- Use Pymarc combining the OCLC metadata API to clean up bib records and then have them ready for import
- Bulk edit a MARC field across all records in a manner that isn’t supported by local ILS bulk record modification function
- Cataloging copy look up program – batch search cataloging copy in Worldcat based on ISBN, LCCN, and OCLC number.
- MARC record generator for internet archives records, books
- Clean up call numbers after migration to a new ILS
- Batch adding of a list of URLs from a spreadsheet as 856 tags to the corresponding bib records.
- Batch encoding holdings information stored in a CSV file in a particular ILS MARC holdings format for respective bib records.
- Retrieving and processing MARC files from OCLC Collection Manager, Marcive for government documents, and Marcive authority work
- Processing and submitting MARC output files from Sierra to EBSCO for discovery service
- On-going bibliographic maintenance, fixing errors via Sierra API, identifying duplicate or merged records
- Submitting serial holdings from Sierra to OCLC via data sync
-
- Acquisition work
-
- Batch update renewal dates and renewal periods for PO Lines
-
- Transform data from one format to another
-
- From EAD XML to human readable PDFs
- From TIFF to PDF and apply OCR
-
- Support IR work
-
- Check bad links
- Make global changes
-
- System interaction and integration via APIs
-
- Pulling data from different systems or sources
- Calling APIs to grab and parse data
- Writing plugin modules to integrate with FOLIO ILS
-
- Reporting
-
- A report on how many folks are in Google scholar, used to maintain databases on course reserve system;
- Number of citations and publications in combination with Scopus API and Python
- Report on new items, high demand holds, lost and paid, missing items
-
- Support language translation
-
- Convert regional language to a standard script
- Apply OCR for regional languages
-
- Other data analysis
-
- Analyzing order records, import logs
- Parsing MOD XML files or spreadsheets, csv files
- OA content evaluation
-
- Other automation
-
- File renaming
- Inventory of born-digital content
- Scripting to enable students, faculty, and staff to play legacy computer games
-
Appendix E. Python resources recommended by participants
https://docs.google.com/document/d/1bVZLrR34-33sVrXBT6fE37KDDGo7I3BSV1NcYRYjE2A/edit?usp=sharing

Subscribe to comments: For this article | For all articles
Leave a Reply